0 联系我
2.完整博客链接
3.个人知乎
4.gayhub
相关源码
广告检索系统的核心是实现广告检索服务,为加快广告检索的速度,良好的索引设计是不可缺少的. 本文首先对索引的设计与维护进行介绍,之后,实现广告数据的索引服务.
1 广告数据索引设计介绍

1.1 正向索引
- 定义 也称为正排索引(Forward Index),通过唯一键/主键生成与对象的映射关系. 即通过主键(Key)检索到文档(Doc)内容,以下简称正排表或Table.
Table 不仅提供按主键的增删除改查,也配合倒排表实现检索、过滤、读取等功能. 作为核心数据结构,Table必须支持频繁的字段读取和各类型的正排过滤,需要高效和紧凑的实现.
- 一个简单的例子

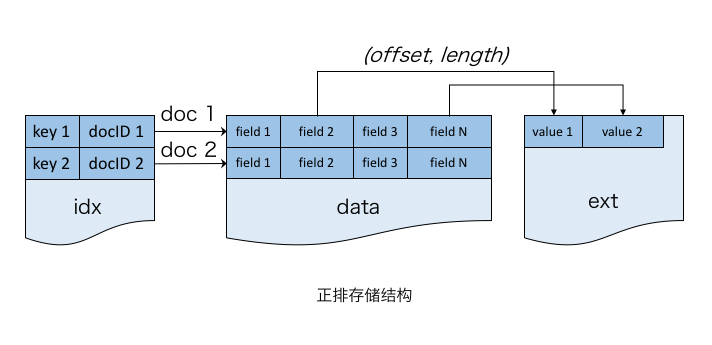 为支持按 docID 的随机访问,把Table设计为一个大数组结构(data区). 每个 doc 是数组的一个元素且长度固定,变长字段存储在扩展区(ext区),仅在 doc 中存储其在扩展区的偏移量和长度. 与大部分搜索引擎的列存储不同,将data区按行存储,这样可针对业务场景,尽可能利用CPU与内存之间的缓存来提高访问效率.
为支持按 docID 的随机访问,把Table设计为一个大数组结构(data区). 每个 doc 是数组的一个元素且长度固定,变长字段存储在扩展区(ext区),仅在 doc 中存储其在扩展区的偏移量和长度. 与大部分搜索引擎的列存储不同,将data区按行存储,这样可针对业务场景,尽可能利用CPU与内存之间的缓存来提高访问效率.
此外,针对NoSQL场景,可通过HashMap实现主键到docID的映射(idx文件),这样就可支持主键到文档的随机访问.由于倒排索引的docID列表可以直接访问正排表,因此倒排检索并不会使用该idx.
- 小结 这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护.
- 因为索引是基于文档建立的,若是有新的文档加入,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面
- 若是有文档删除,则直接找到该文档号文档对应的索引信息,将其直接删除.
但是在查询的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下,尽管正排表的工作原理非常的简单,但是由于其检索效率太低,除非在特定情况下,否则实用性价值不大.
1.2 倒排索引(Inverted Index)
 即通过关键词(Keyword)检索到文档内容. 为支持复杂的业务场景,如遍历索引表时的算法粗排逻辑,在此抽象了索引器接口Indexer.
即通过关键词(Keyword)检索到文档内容. 为支持复杂的业务场景,如遍历索引表时的算法粗排逻辑,在此抽象了索引器接口Indexer. 
倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况.
由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以效率高于正排表。在全文检索中,检索的快速响应是一个最为关键的性能,而索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率. 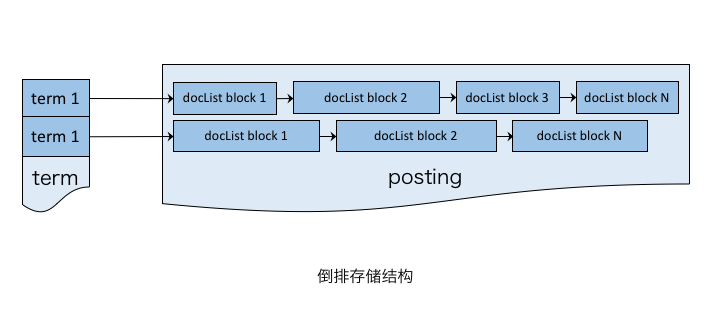
正排索引是从文档到关键字的映射(已知文档求关键字) 倒排索引是从关键字到文档的映射(已知关键字求文档)
一个简单的例子

在检索系统中的应用 核心用途是对各个维度限制的"整理"

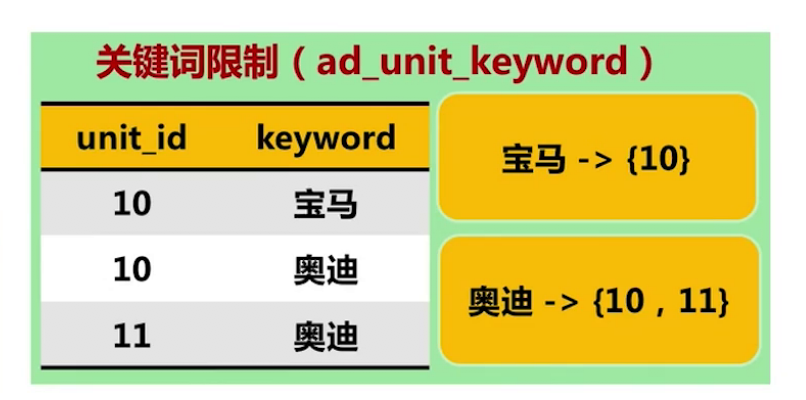

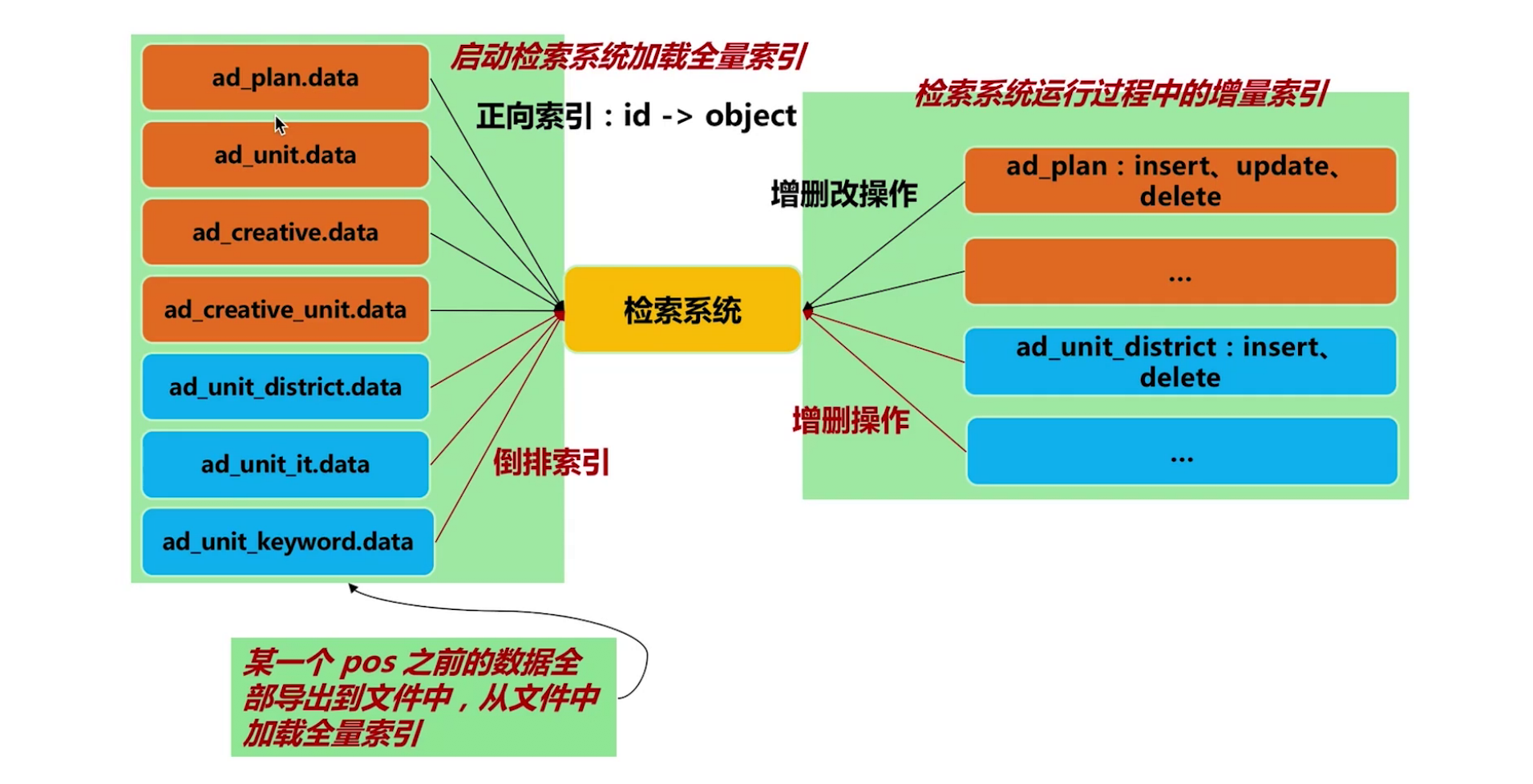
2 广告数据索引维护
全量索引 + 增量索引

3 推广计划索引对象定义与服务实现
- 索引接口

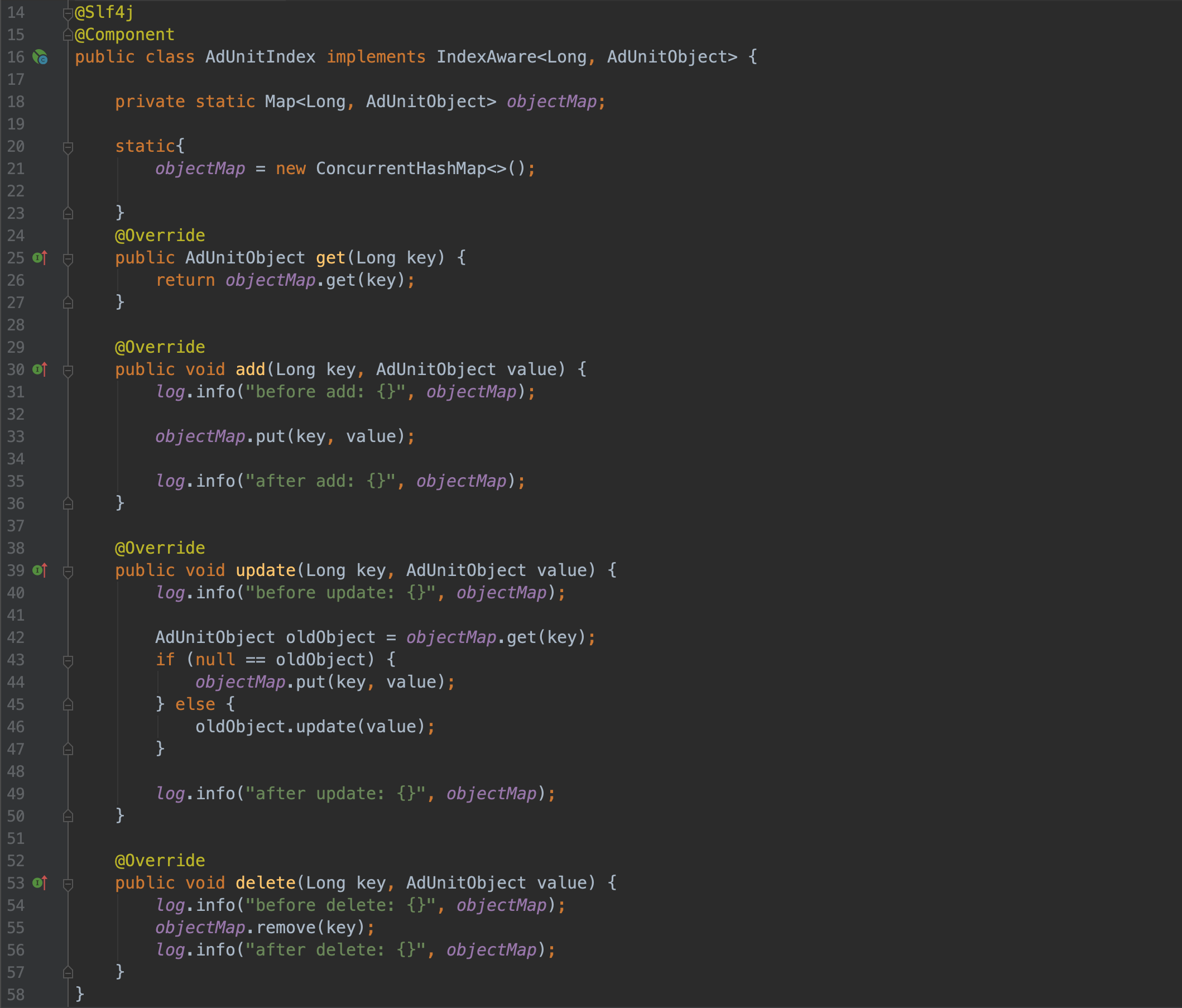
4 推广单元索引对象定义与服务实现
5 关键词索引对象定义与服务实现

6 兴趣索引对象定义与服务实现

7 地域索引对象定义与服务实现

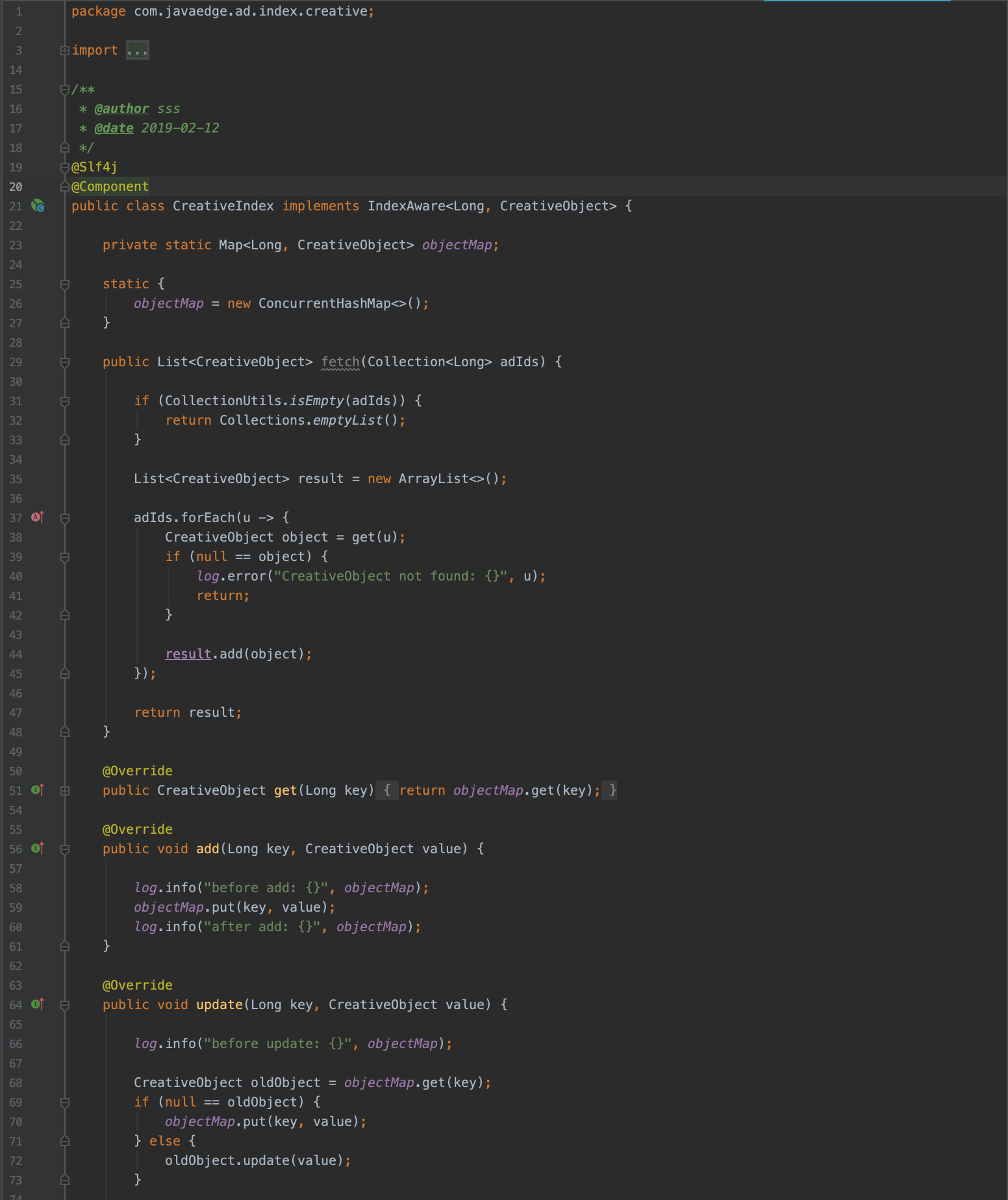
8 创意索引对象定义与服务实现
9 创意与推广单元关联索引对象定义与服务实现

10 索引服务类缓存的实现

参考
https://coding.imooc.com/class/chapter/310.html#Anchorhttps://tech.meituan.com/2018/05/11/adp-rtidx-ls.htmlhttps://blog.csdn.net/zhangzeyuaaa/article/details/48676775