Kafka 的基本概念
分布式流处理平台
提供发布订阅及 Topic 支持
吞吐量高但不保证消息有序
Kafka消费者组是Kafka消费的单位
单个Partition只能由消费者组中某个消费者消费
消费者组中的单个消费者可以消费多个Partition
常见命令
1、启动Kafka
bin/kafka-server-start.sh config/server.properties &
2、停止Kafka
bin/kafka-server-stop.sh
3、创建Topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic jiangzh-topic
4、查看已经创建的Topic信息
bin/kafka-topics.sh --list --zookeeper localhost:2181
5、发送消息
bin/kafka-console-producer.sh --broker-list 192.168.220.128:9092 --topic jiangzh-topic
6、接收消息
bin/kafka-console-consumer.sh --bootstrap-server 192.168.220.128:9092 --topic jiangzh-topic --from-beginning配置
https://www.cnblogs.com/saryli/p/13840672.html
Kafka客户端操作类型
AdminClient API:允许管理和检测Topic、broker以及其它Kafka对象
Kafka AdminClient API 和对应的 作用
- AdminClient: AdminClient客户端对象
- NewTopic: 创建Topic
- CreateTopicsResult: 创建Topic的返回结果
- ListTopicsResult: 查询Topic列表
- ListTopicsOptions: 查询Topic列表及选项
- DescribeTopicsResult: 查询Topics
- DescribeConfigsResult: 查询Topics配置项
Producer API:发布消息到1个或多个topic
Sample
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.220.128:9092");
properties.put(ProducerConfig.ACKS_CONFIG, "all");
properties.put(ProducerConfig.RETRIES_CONFIG, "0");
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, "16384");
properties.put(ProducerConfig.LINGER_MS_CONFIG, "1");
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, "33554432");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "com.imooc.jiangzh.kafka.producer.SamplePartition");
// Producer的主对象
Producer<String, String> producer = new KafkaProducer<>(properties);
// 消息对象 - ProducerRecoder
for (int i = 0; i < 10; i++) {
ProducerRecord<String, String> record =
new ProducerRecord<>(TOPIC_NAME, "key-" + i, "value-" + i);
producer.send(record, (recordMetadata, e) ->
System.out.println("partition : " + recordMetadata.partition() + " , offset : " + recordMetadata.offset()));
}
// 所有的通道打开都需要关闭
producer.close();Producer发送模式
- 同步发送
- 异步发送
- 异步回调发送
构建 KafkaProducer
- MetricConfig
- 加载负载均衡器
- 初始化Serializer
- 初始化RecordAccumulator ——类似于计数器
- 启动newSender ——守护线程
KafkaProducer
- Producer是线程安全的
- Producer并不是接到一条发一条
- Producer是批量发送
KafkaProducer send(record) 方法
- 计算分区 —— 消息具体进入哪一个partition
- 计算批次 —— accumulator.append
- 1、创建批次 2、向批次中追加内容
消息传递保障
- 最多一次:收到0到1次
- 至少一次:收到1到多次
- 正好一次:有且仅有一次
acks 配置
acks参数,是在KafkaProducer里设置的,也就是说,往kafka写数据的时候,可以来设置这个acks参数。有三种常见的值可以设置,分别是:0、1 和 all。
Leader维护了一个动态的ISR(in-sync replica), 目的是和leader保持同步的follower集合,当ISR中的follower完成数据的同步之后,leader就会给生产者发送ack,如果follower长时间未向leader同步数据,则该follower将被踢出ISR,该时间阈值由replica.lag.time.max.ms参数设定,Leader发生故障之后,就会从ISR中选举新的Leader
producer需要server接收到数据之后发出的确认接收的信号,此项配置就是指 procuder 需要多少个这样的确认信号。此配置实际上代表了数据备份的可用性。以下设置为常用选项:
(1)acks=0
- 设置为0表示producer不需要等待任何确认收到的信息。副本将立即加到
socket buffer并认为已经发送。没有任何保障可以保证此种情况下server已经成功接收数据,同时重试配置不会发生作用(因为客户端不知道是否失败)回馈的offset会总是设置为-1;
- 设置为0表示producer不需要等待任何确认收到的信息。副本将立即加到
(2)acks=1(kafka默认的设置)
- producer等待borker的ack,这意味着至少要等待leader已经成功将数据写入本地log,但是并没有等待所有follower是否成功写入。这种情况下,如果follower没有成功备份数据,而此时leader又挂掉,则消息会丢失。
(3)acks=-1(all)
- producer等待borker的ack,只有所有参与复制的节点(ISR列表的副本)全部收到消息时,生产者才会接收到来自服务器的响应,此时如果ISR同步副本的个数小于
min.insync.replicas的值,消息不会被写入 ,即broker的partition的ISR中的leader和follower都落盘成功才返回ack,但在follower同步之后,broker发送ack之前,leader故障,会造成数据重复
- producer等待borker的ack,只有所有参与复制的节点(ISR列表的副本)全部收到消息时,生产者才会接收到来自服务器的响应,此时如果ISR同步副本的个数小于
当ISR列表只剩Leader的情况下, asks=-1 相当于 asks=1
- (4)其他的设置
- 例如acks=2也是可以的,这将需要给定的acks数量,但是这种策略一般很少用。
数据一致性问题(follower之间的数据一致性)故障处理细节
Log文件的HW和LEO
- LEO(Log End Offset):每个副本的最后一个offset
- HW(High Watermark):消费者能见到的最大的offset,ISR队列中最小的LEO

follower故障时
会被临时踢出ISR,待该follower恢复后,follower会读取本地磁盘记录的上次HW,并将log文件高于HW的部分截取掉,从HW开始向leader进行同步,等该follower的LEO大于等于该Partiton的HW,即follower追上leader之后,就可以重新加入ISR了
leader故障时
会从ISR中选出一个新的leader,之后为保证多个副本之间数据一致性,其余的follower会先将各自的log文件高于HW的部分截掉,然后从新的leader同步数据
注意⚠️:这只能保证副本之间的数据一致性,并不能保证数据不丢失或不重复
Exactly Once
Exactly Once = 幂等性 + At Least Once
将服务器的ACK级别设置为-1,可以保证Producer到Server不会丢数据,即At Least Once语义,但不能保证数据重复
将服务器的ACK级别设置为0,可以避免数据重复,At Most Once,但不能保证数据不丢失
但是对于交易数据,下游数据消费者要求数据即不重复也不丢失,就是Exactly Once,在0.11以前版本,是无能为力的,只能保证数据不丢失,再在对数据做全局去重
0.11版本的Kafka,引入了一项重大特性:幂等性,所谓的幂等性就是指producer不论向Server发送多少次重复数据,Server端都只会持久化一条,幂等性结合At Least Once语义,构成了Exactly Once
要启用幂等性,只需要将Producer的参数中enable.idompotence设置为true即可
幂等性的实现就是将原来下游需要做的去重放在了数据上游,开启幂等性的Producer在初始化的时候会被分配一个PID,发往同一Partition的消息会附带Sequence Number,而Broker端会对做缓存,当具有相同主键的消息提交时,Broker只会持久化一条
但是PID重启就会变化,同时不同的partiton也具有不同主键,所以幂等性无法保证跨分区跨会话的Exactly Once
Consumer APl:订阅一个或多个topic,并处理产生的消息
消费方式
consumer采用pull的方式从broker中拉数据
pull的方式缺点是,如果kafka中没有数据,消费者可能会陷入循环中,一直返回空数据,针对这一点,kafka的消费者在消费数据时会传入一个时长参数timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回,这段时间即为timeout
分区分配策略
一个consumer group中有多个consumer,一个topic有多个partition,就会有partition分配问题,即确定哪个partition由哪个consumer消费
Kafka有两种分配策略,一种是RoundRobin(轮询),另一种是Range(按范围)
RoundRobin

轮询,如果一个topic有多个partition,一个消费者订阅多个topic,多个topic的partition都组合在一起,进行轮询
使用的前提条件:消费者组订阅的topic都是一样的
Range -- 默认的分区策略

可以尽量均匀
当消费者组的消费者个数发生变化的时候,都会重新分配分区策略
offset的维护
由于consumer在消费过程中可能会出现宕机等故障,consumer恢复后,需要从故障前的位置开始消费,就需要实时记录自己消费的位置,以便故障恢复后继续消费
kafka在zookeeper中的节点数据

灰色的部分,kafka0.9之前,默认保存在zookeepr中,从0.9版本开始,consumer默认将offset保存在kafka一个内置的topic中,该topic是**_consumer_offset**,消费者启动时使用--bootstrap-server localhost:9092,就会保存在kafka本地,如果用--zookeeper localhost:2181,就会保存在zookeeper
总结:offset保存的形式是:消费者组+topic+partition
_consumer_offset也是一个主题,也可以查看,需要进行设置
consumer.properties中:exclude.internal.topics=false
读取offset
bin/kafka-console-consumer.sh --topic _consumer_offsets --zookeeper hadoop102:2181 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning一个消费者组,同一时刻只能有一个消费者消费
修改多个消费者是同一个消费者组:consumer.properties中group.id = xxx //消费者组名
Consumer注意事项
- 单个分区的消息只能由ConsumerGroup中某个Consumer消费
- Consumer从Partition中消费消息是顺序,默认从头开始消费
- 单个ConsumerGroup会消费所有Partition中的消息
新成员入组

组成员崩溃
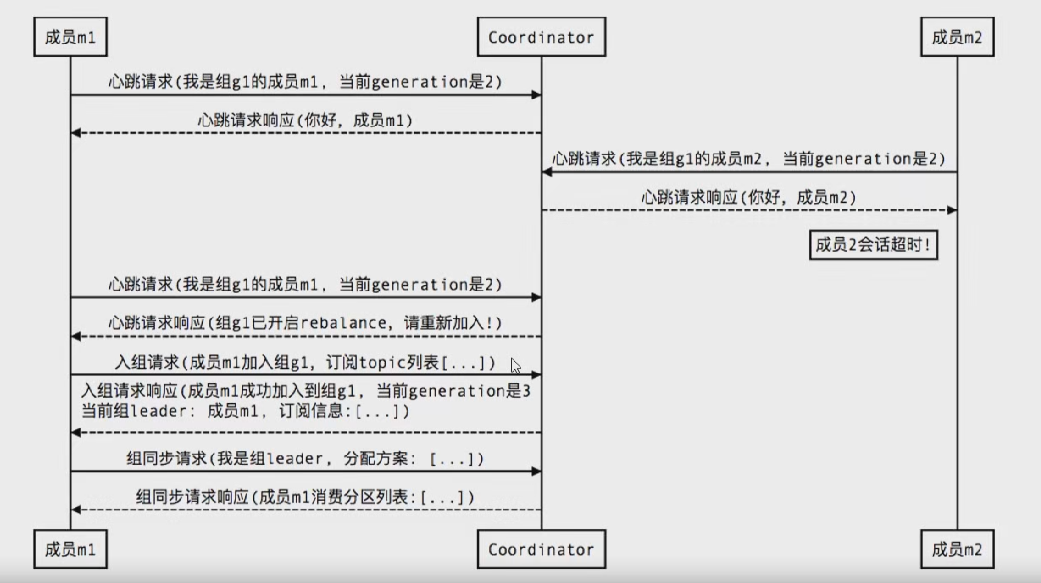
组成员主动离组
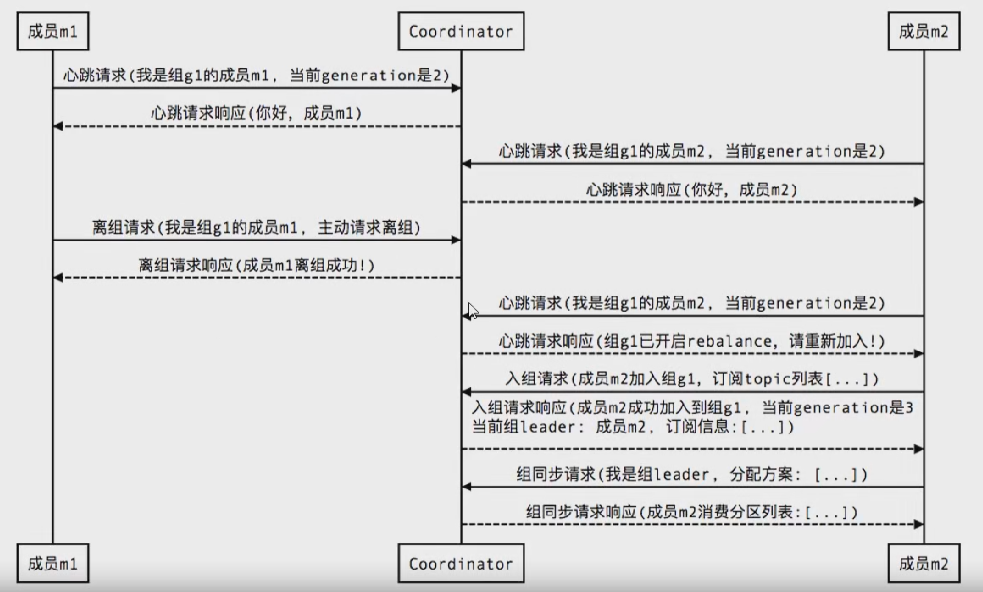
提交位移

Streams API:高效地将输入流转换到输出流
Kafka Stream基本概念
- Kafka Stream是处理分析存储在Kafka数据的客户端程序库
- Kafka Stream通过state store可以实现高效状态操作
- 支持原语Processor和高层抽象DSL
sample
public class StreamSample {
private static final String INPUT_TOPIC="jiangzh-stream-in";
private static final String OUT_TOPIC="jiangzh-stream-out";
public static void main(String[] args) {
Properties props = new Properties();
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.220.128:9092");
props.put(StreamsConfig.APPLICATION_ID_CONFIG,"wordcount-app");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
// 如果构建流结构拓扑
final StreamsBuilder builder = new StreamsBuilder();
// 构建Wordcount
wordcountStream(builder);
// 构建foreachStream
foreachStream(builder);
final KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
}
// 如果定义流计算过程
static void foreachStream(final StreamsBuilder builder){
KStream<String,String> source = builder.stream(INPUT_TOPIC);
source
.flatMapValues(value -> Arrays.asList(value.toLowerCase(Locale.getDefault()).split(" ")))
.foreach((key,value)-> System.out.println(key + " : " + value));
}
// 如果定义流计算过程
static void wordcountStream(final StreamsBuilder builder){
// 不断从INPUT_TOPIC上获取新数据,并且追加到流上的一个抽象对象
KStream<String,String> source = builder.stream(INPUT_TOPIC);
// Hello World imooc
// KTable是数据集合的抽象对象
// 算子
final KTable<String, Long> count =
source
.flatMapValues(value -> Arrays.asList(value.toLowerCase(Locale.getDefault()).split(" ")))
// 合并 -> 按value值合并
.groupBy((key, value) -> value)
// 统计出现的总数
.count();
// 将结果输入到OUT_TOPIC中
count.toStream().to(OUT_TOPIC, Produced.with(Serdes.String(),Serdes.Long()));
}
}Connector API:从一些源系统或应用程序中拉取数据到kafka
Kafka Connect基本概念
- Kafka Connect是Kafka流式计算的一部分
- Kafka Connect主要用来与其他中间件建立流式通道
- Kafka Connect支持流式和批量处理集成
Kafka核心概念
- Broker:一般指Kafka的部署节点
- Leader:用于处理消息的接收和消费
- Follower:主要用于备份消息数据
Kafka集群部署
- Kafka天然支持集群
- Kafka集群依赖于Zookeeper进行协调
- Kafka主要通过brokerld区分不同节点
Kafka节点故障
- Kafka与zookeeper心跳未保持视为节点故障
- follower消息落后leader太多也视为节点故障
- Kafka会对故障节点进行移除
Kafka节点故障处理
- Kafka基本不会因为节点故障而丢失数据
- Kafka的语义担保也很大程度上避免数据丢失
- Kafka会对消息进行集群内平衡,减少消息在某些节点热度过高
Kafka集群之Leader选举
- Kafka并没有采用多数投票来选举leader
- Kafka会动态维护—组Leader数据的副本(ISR)
- Kafka会在ISR中选择一个速度比较快的设为Leader
- Kafka有一种无奈的情况,ISR中副本全部宕机
- 对于上述情况,Kafka会进行unclean leader选举
- Kafka提供了两种不同的选择处理该部分内容
Leader选举配置建议
- 禁用“unclean leader”选举
- 手动指定最小ISR
Kafka面试题类型
Kafka面试题分析
Kafka概念:分布式流处理平台
Kafka特性一:提供发布订阅及Topic支持
Kafka特性二:吞吐量高但不保证消息有序
Kafka消费者组是Kafka消费的单位
单个Partition只能由消费者组中某个消费者消费
消费者组中的单个消费者可以消费多个Partition
Kafka常见应用场景
- 日志收集或流式系统
- 消息系统
- 用户活动跟踪或运营指标监控
Kafka与其他消息中间件异同点
todo
Kafka 吞吐量为什么大? 速度为什么快?
- 日志顺序读写和快速检索
- Partition机制
- 批量发送接收及数据压缩机制
- 通过sendfile实现零拷贝
Kafka底层原理之日志
- Kafka的日志是以partition为单位存储的
- 日志目录格式为 topic名称+数字
- 日志文件格式是一个 ”日志条目“ 序列
- 每条日志消息由4字节整形与N字节消息组成java
message length : 4 bytes (value: 1+4+n) //消息长度 "magic" value : 1 byte //版本号 crc : 4 bytes //CRC校验码 payload : n bytes //具体的消息
日志分段
每个partition的日志会分为N个大小相等的segment中
每个segment中消息数量不一定相等
每个partition支持顺序读写(磁盘io顺序读写不一定比内存慢)
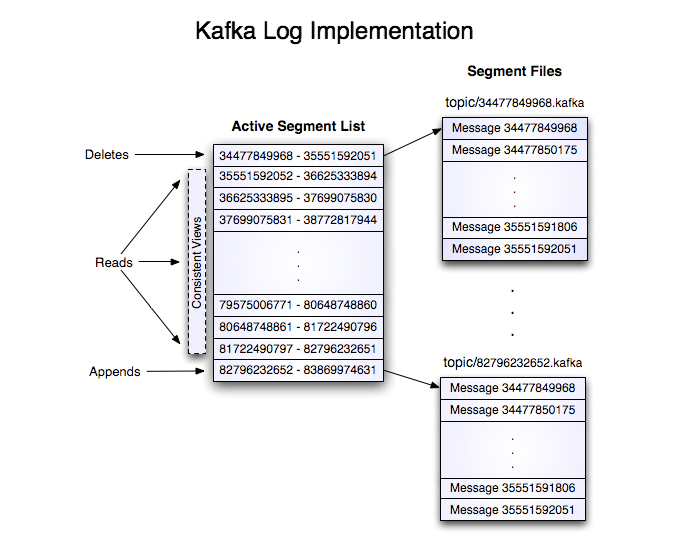
segment存储结构
- Partition会将消息添加到最后一个 segment 上
- 当segment达到一定阈值会flush到磁盘上(consumer只有flush在磁盘上之后才能读到)
- segment 文件分为两个部分:index文件和 data文件(.log文件)
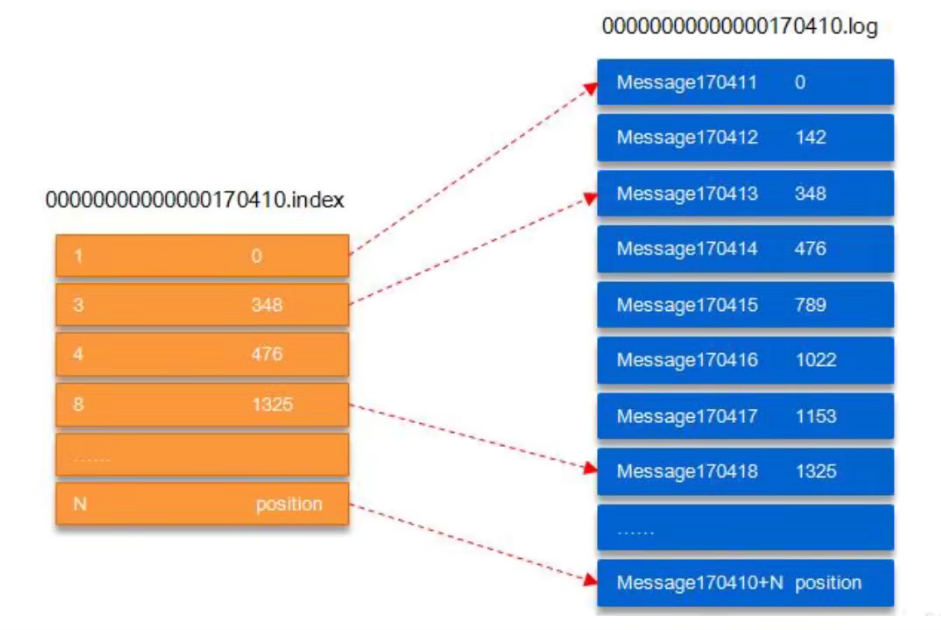
日志读操作
- 首先需要在存储的数据中找出 segment 文件
- 然后通过全局的 offset 计算出 segment 中的 offset
- 通过 index 中的 offset 寻找具体数据内容
日志写操作
- 日志允许串行的追加消息到文件最后
- 当日志文件达到阈值则滚动到新 segment 文件上
Kafka 通过sendfile实现零拷贝原理

- 直接使用Linux的Sendfile(不建议Kafka部署在windows上面)
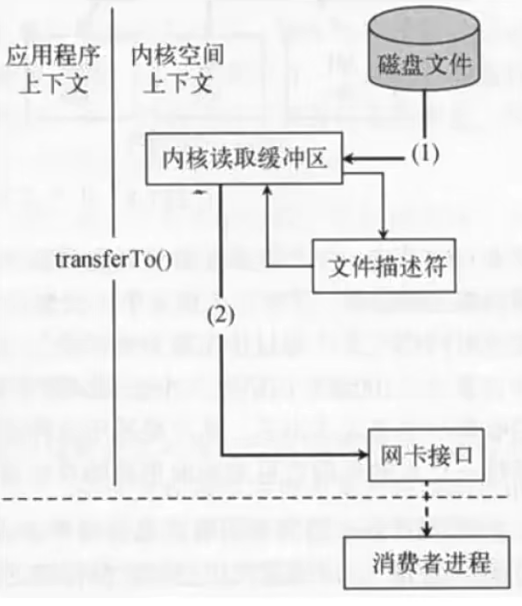
Kafka Producer
- 创建producer的时候就会创建一个守护线程(RecordAccumulator)
- 这个守护线程一直轮询把消息发到Kafka


Kafka 消息有序性处理
- Kafka的特性只支持单 Partition 有序
- 使用Kafka Key+offset可以做到业务有序
- eg:订单系统的id作为 key 加上 offset
Kafka Topic 删除
- 流程

- 建议
- 建议设置auto.create.topics.enable=false
- 建议设置delete.topic.enable=true
Kafka如何保证单partition有序?
producer发消息到队列时,通过加锁保证有序 现在假设两个问题 broker leader在给producer发送ack时,因网络原因超时,那么Producer 将重试,造成消息重复。 先后两条消息发送。t1时刻msg1发送失败,msg2发送成功,t2时刻msg1重试后发送成功。造成乱序。
解决重试机制引起的消息乱序
为实现Producer的幂等性,Kafka引入了Producer ID(即PID)和Sequence Number。对于每个PID,该Producer发送消息的每个<Topic, Partition>都对应一个单调递增的Sequence Number。同样,Broker端也会为每个<PID, Topic, Partition>维护一个序号,并且每Commit一条消息时将其对应序号递增。对于接收的每条消息,如果其序号比Broker维护的序号)大一,则Broker会接受它,否则将其丢弃:
- 如果消息序号比Broker维护的序号差值比一大,说明中间有数据尚未写入,即乱序,此时Broker拒绝该消息,Producer抛出InvalidSequenceNumber
- 如果消息序号小于等于Broker维护的序号,说明该消息已被保存,即为重复消息,Broker直接丢弃该消息,Producer抛出DuplicateSequenceNumber
- Sender发送失败后会重试,这样可以保证每个消息都被发送到broker