小智后端服务 xiaozhi-esp32-server
项目定位:开源的语音交互与物联网控制后端
核心价值:模块化设计 · 实时流式处理 · 多服务兼容
源码地址:github.com/xinnan-tech/xiaozhi-esp32-server
本项目为开源智能硬件项目小智 ESP32 提供后端服务,根据小智通信协议实现功能:
- Python 实现的 Websocket Server
- Java 实现的管理 API
- Vue.js 实现的管理界面
帮助开发者快速搭建小智智能硬件服务器
功能架构
核心能力
语音交互系统
- 语音识别 (ASR):支持多语言(中文/粤语/英语/日语/韩语)
- 语音合成 (TTS):默认微软 EdgeTTS,支持火山引擎双流式合成
- 语音活动检测 (VAD):通过 SileroVAD 实现实时打断
智能对话引擎
- 大语言模型 (LLM):支持智谱/火山豆包/DeepSeek/Ollama 等模型
- 记忆管理:本地短期记忆 + mem0ai 云端长期记忆
- 意图识别:通过 function_call 实现设备控制指令解析
物联网控制
- 设备注册与状态管理
- 上下文感知控制(如"打开客厅灯")
管理平台
- 设备监控管理
- 系统配置管理
- OTA 固件升级
- 测试工具:提供接口调试页面
- 智控台地址: https://2662r3426b.vicp.fun
- 服务测试工具: https://2662r3426b.vicp.fun/test/
- OTA接口地址: https://2662r3426b.vicp.fun/xiaozhi/ota/
- Websocket接口地址: wss://2662r3426b.vicp.fun/xiaozhi/v1/
高级扩展
- OTA升级:支持设备远程固件更新(
/xiaozhi/ota/接口)。 - 多协议兼容:适配
xiaozhi-esp32硬件通信协议,支持第三方LLM/ASR/TTS服务接入。
- OTA升级:支持设备远程固件更新(
系统架构
项目采用 模块化微服务架构,关键组件如下:
通信层
- 协议:基于
xiaozhi-esp32自定义协议,使用 WebSocket 实现设备与服务器的双向实时通信。 - 接口:
- 对话接口:
wss://domain/xiaozhi/v1/ - OTA升级:
https://domain/xiaozhi/ota/
- 对话接口:
- 协议:基于
业务逻辑层
- 模块化设计:ASR、LLM、TTS、Intent、Memory 等模块可独立替换(通过配置文件切换)。
- 流式处理:全链路流式支持(ASR→LLM→TTS),响应速度优化(较旧版提升2.5秒)。
数据层
- 简化版:数据存储在配置文件(无数据库)。
- 完整版:使用数据库存储设备/用户数据(具体DB类型未说明)。
部署架构
- 容器化:提供
Dockerfile-server和Dockerfile-web,支持一键部署。 - 资源要求:
- 简化版:2核2G(全API)或 2核4G(含FunASR)。
- 完整版:2核4G(全API)或 4核8G(含FunASR)。
- 容器化:提供
原作者的使用效果视频 🎥
- 小智esp32连接自己的后台模型:https://www.bilibili.com/video/BV1FMFyejExX
- 自定义音色:https://www.bilibili.com/video/BV1CDKWemEU6
- 使用粤语交流:https://www.bilibili.com/video/BV12yA2egEaC
- 控制家电开关:https://www.bilibili.com/video/BV1pNXWYGEx1
- 成本最低配置:https://www.bilibili.com/video/BV1kgA2eYEQ9
- 自定义音色:https://www.bilibili.com/video/BV1Vy96YCE3R
- 播放音乐:https://www.bilibili.com/video/BV1VC96Y5EMH
- 天气插件:https://www.bilibili.com/video/BV1Z8XuYZEAS
- IOT指令控制设备:https://www.bilibili.com/video/BV178XuYfEpi
- 播报新闻:https://www.bilibili.com/video/BV17LXWYvENb
- 实时打断:https://www.bilibili.com/video/BV12J7WzBEaH
- 拍照识物品:https://www.bilibili.com/video/BV1Co76z7EvK
- 多指令任务:https://www.bilibili.com/video/BV1TJ7WzzEo6
已使用本地test-page验证的功能
- 语音/文本交互
- 音色切换
- 天气查询
- 播放音乐
- 新闻播报
生态与扩展
- 客户端支持:
- Android/iOS客户端(Flutter开发)
- Python模拟客户端(
py-xiaozhi) - Java服务端替代方案(
xiaozhi-esp32-server-java)
- 第三方服务兼容:
- LLM:阿里百炼、Dify、FastGPT、Coze 等兼容OpenAI接口的模型。
- TTS:腾讯云、阿里云、GPT-SoVITS 本地合成等。
- ASR:支持本地(SherpaASR)或云端(腾讯/Aliyun)方案。
部署文档
本项目提供两种部署方式,请根据您的具体需求选择:
🚀 部署方式选择
| 部署方式 | 特点 | 适用场景 | 部署文档 | 配置要求 | 视频教程 |
|---|---|---|---|---|---|
| 最简化安装 | 智能对话、IOT功能,数据存储在配置文件 | 低配置环境,无需数据库 | Docker版 / 源码部署 | 如果使用FunASR要2核4G,如果全API,要2核2G | - |
| 全模块安装 | 智能对话、IOT、OTA、智控台,数据存储在数据库 | 完整功能体验 | Docker版 / 源码部署 | 如果使用FunASR要4核8G,如果全API,要2核4G | 本地源码启动视频教程 / 本地源码自动更新教程 |
总结
项目定位:为ESP32硬件提供低代码、可扩展的语音交互与物联网控制后端,核心价值在于:
- 模块化:自由组合ASR/LLM/TTS服务(本地/云端混合)。
- 实时性:全流式架构优化响应速度。
- 生态整合:兼容多品牌硬件和AI服务,提供智控台统一管理。
适用场景:个人开发者搭建智能家居中控、教育类语音机器人等实验性项目。
附:通信协议:Websocket 连接
基本信息
- 协议版本: 1
- 传输方式: Websocket
- 音频格式: OPUS
- 音频参数:
- 采样率: 16000Hz
- 通道数: 1
- 帧长: 60ms
连接建立
- 客户端连接Websocket服务器时需要携带以下headers:
Plain
Authorization: Bearer <access_token>
Protocol-Version: 1
Device-Id: <设备MAC地址>
Client-Id: <设备UUID>设备MAC地址和UUID都是设备唯一识别码。
- 连接成功后,客户端发送hello消息:
JSON
{
"type": "hello",
"version": 1,
"transport": "websocket",
"audio_params": {
"format": "opus",
"sample_rate": 16000,
"channels": 1,
"frame_duration": 60
}
}- 服务端响应hello消息:
JSON
{
"type": "hello",
"transport": "websocket",
"audio_params": {
"format": "opus",
"sample_rate": 24000,
"channels": 1,
"frame_duration": 60
}
}Websocket协议不返回 session_id,所以消息中的会话ID可设置为空。
消息类型
1. 语音识别相关消息
开始监听
JSON
{
"session_id": "<会话ID>",
"type": "listen",
"state": "start",
"mode": "<监听模式>"
}监听模式:
- "auto": 自动停止
- "manual": 手动停止
- "realtime": 持续监听
auto 与 realtime 是服务器端 VAD 的两种工作模式,realtime 需要 AEC 支持。
停止监听
JSON
{
"session_id": "<会话ID>",
"type": "listen",
"state": "stop"
}唤醒词检测
JSON
{
"session_id": "<会话ID>",
"type": "listen",
"state": "detect",
"text": "<唤醒词>"
}2. 语音合成相关消息
服务端发送的TTS状态消息:
JSON
{
"type": "tts",
"state": "<状态>",
"text": "<文本内容>" // 仅在 sentence_start 时携带
}状态类型:
- "start": 开始播放
- "stop": 停止播放
- "sentence_start": 新句子开始
3. 中止消息
JSON
{
"session_id": "<会话ID>",
"type": "abort",
"reason": "wake_word_detected" // 可选
}4. IoT设备相关消息
设备描述
JSON
{
"session_id": "<会话ID>",
"type": "iot",
"descriptors": <设备描述JSON>
}设备状态
JSON
{
"session_id": "<会话ID>",
"type": "iot",
"states": <状态JSON>
}5. 情感状态消息
服务端发送:
JSON
{
"type": "llm",
"emotion": "<情感类型>"
}状态流程图
Manual 模式
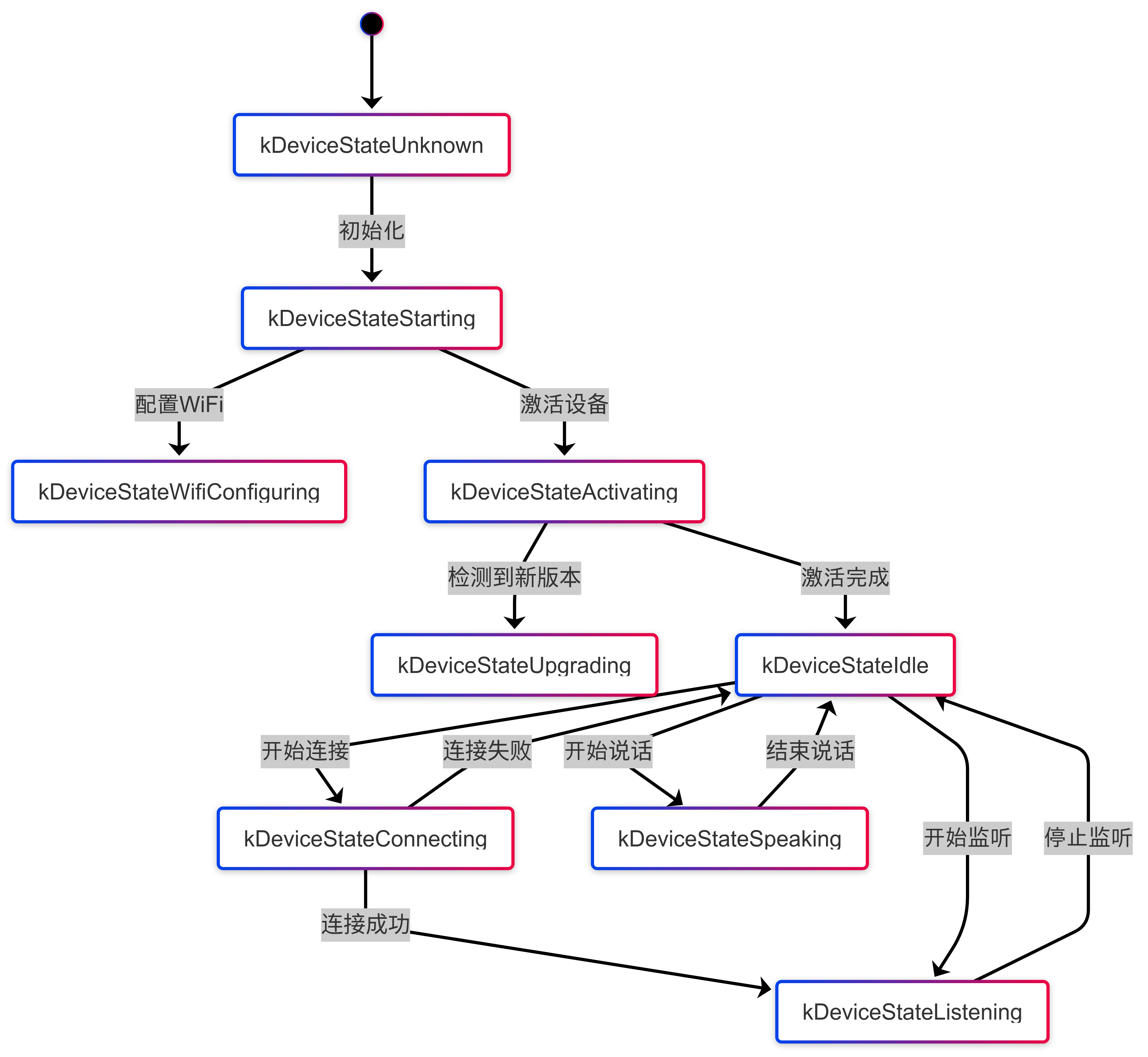
Auto 模式
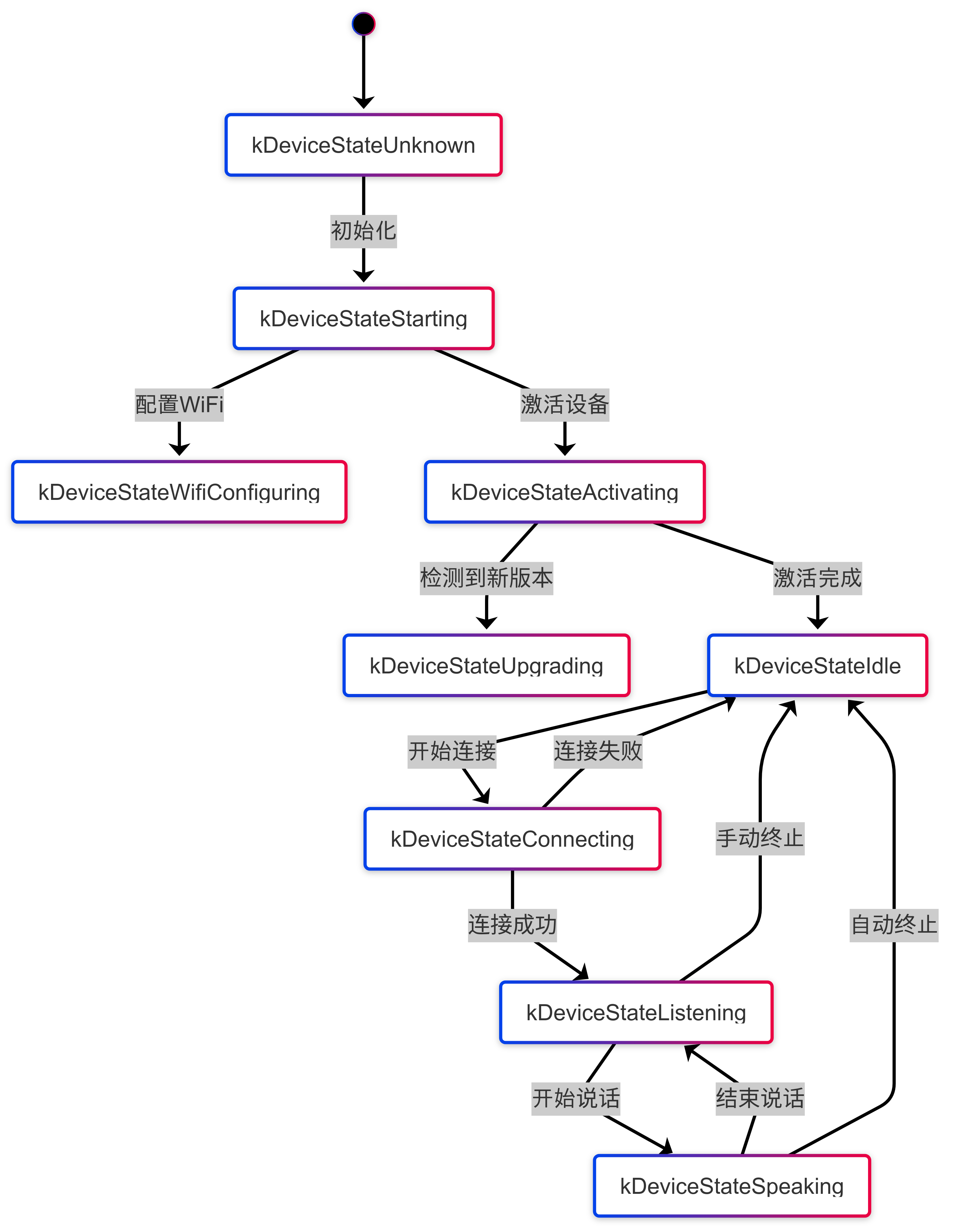
二进制数据传输
- 音频数据使用二进制帧传输
- 客户端发送OPUS编码的音频数据
- 服务端返回OPUS编码的TTS音频数据
错误处理
当发生网络错误时,客户端会收到错误消息并关闭连接。客户端需要实现重连机制。
会话流程
- 建立Websocket连接
- 交换hello消息
- 开始语音交互:
- 发送开始监听
- 发送音频数据
- 接收识别结果
- 接收TTS音频
- 结束会话时关闭连接
通信协议:Emoji 心情显示
大语言模型会使用 1 个 token 来输出 emoji 来表示当前的心情,这个 emoji 不会被 TTS 朗读出来,但是会被以独立数据类型进行返回。
示例:
JSON
{"type":"llm", "text": "😊", "emotion": "smile"}以下是常用的 emoji 列表。
- 😶 - neutral
- 🙂 - happy
- 😆 - laughing
- 😂 - funny
- 😔 - sad
- 😠 - angry
- 😭 - crying
- 😍 - loving
- 😳 - embarrassed
- 😲 - surprised
- 😱 - shocked
- 🤔 - thinking
- 😉 - winking
- 😎 - cool
- 😌 - relaxed
- 🤤 - delicious
- 😘 - kissy
- 😏 - confident
- 😴 - sleepy
- 😜 - silly
- 🙄 - confused