概述
在学习 Containerd 之前我们有必要对 Docker 的发展历史做一个简单的回顾,因为这里面牵涉到的组件实战是有点多,有很多我们会经常听到,但是不清楚这些组件到底是干什么用的,比如 libcontainer、runc、containerd、CRI、OCI 等等。
Docker
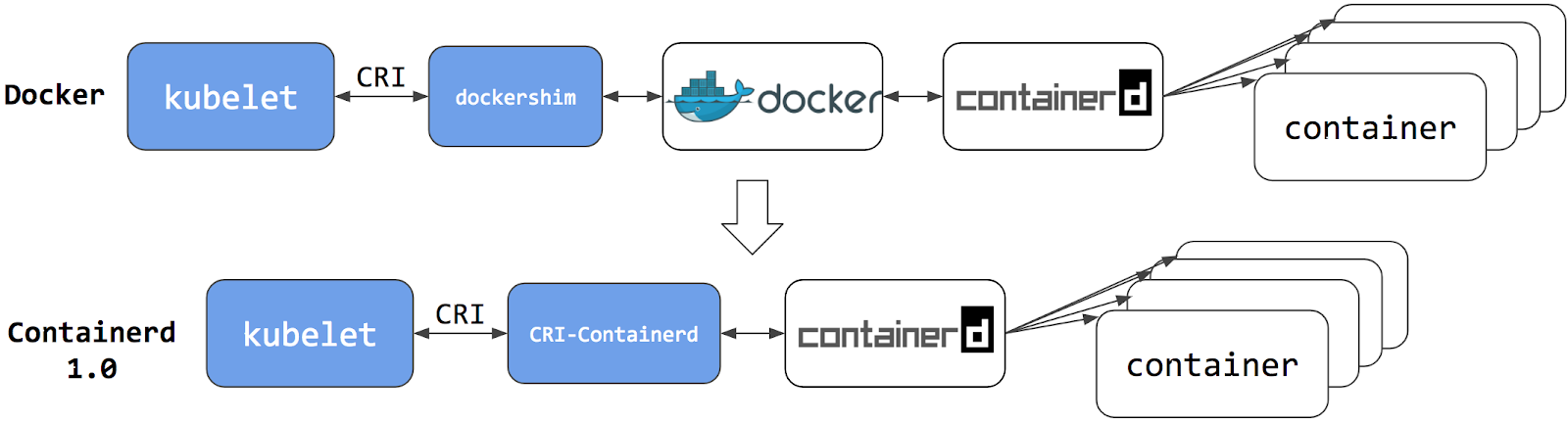
从 Docker 1.11 版本开始,Docker 容器运行就不是简单通过 Docker Daemon 来启动了,而是通过集成 containerd、runc 等多个组件来完成的。虽然 Docker Daemon 守护进程模块在不停的重构,但是基本功能和定位没有太大的变化,一直都是 CS 架构,守护进程负责和 Docker Client 端交互,并管理 Docker 镜像和容器。现在的架构中组件 containerd 就会负责集群节点上容器的生命周期管理,并向上为 Docker Daemon 提供 gRPC 接口。
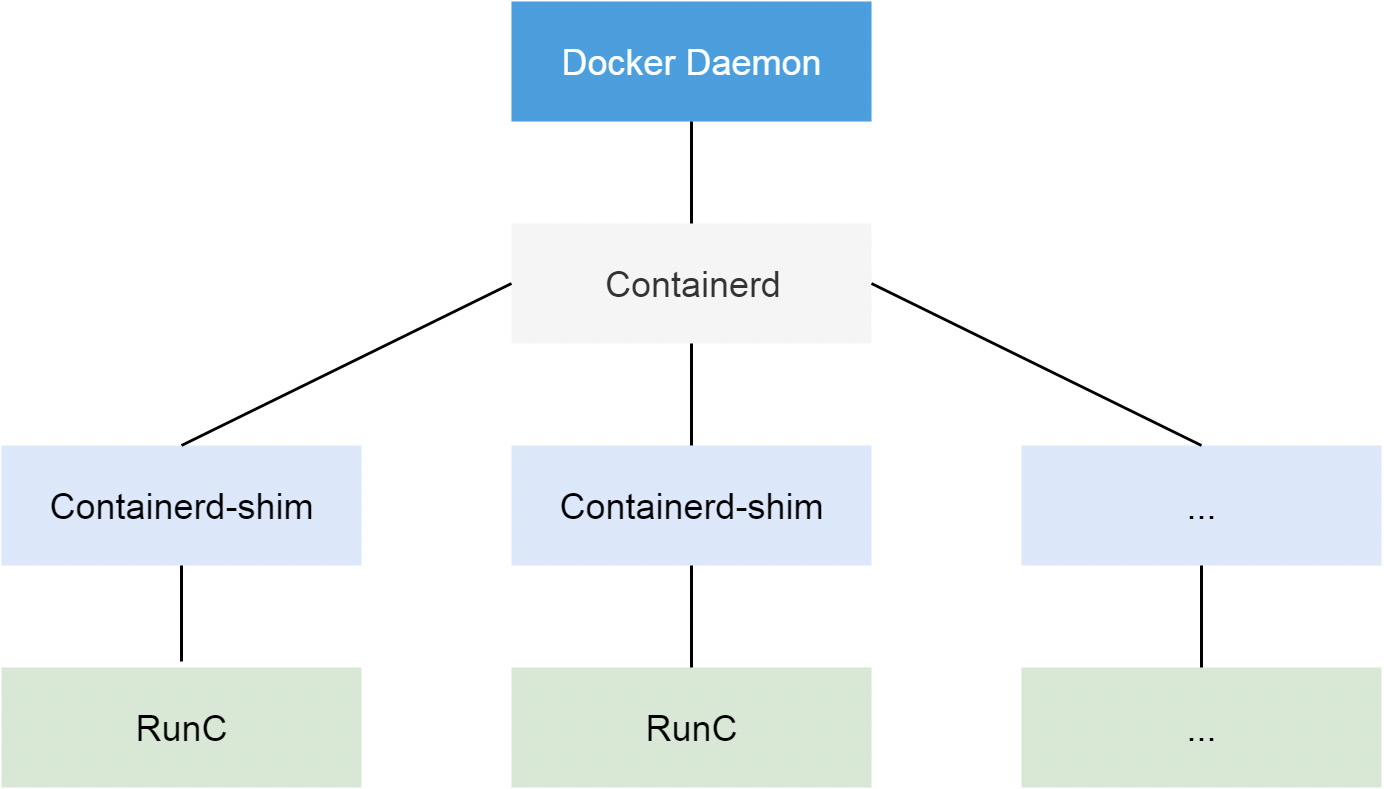
当我们要创建一个容器的时候,现在 Docker Daemon 并不能直接帮我们创建了,而是请求 containerd 来创建一个容器,containerd 收到请求后,也并不会直接去操作容器,而是创建一个叫做 containerd-shim 的进程,让这个进程去操作容器,我们指定容器进程是需要一个父进程来做状态收集、维持 stdin 等 fd 打开等工作的,假如这个父进程就是 containerd,那如果 containerd 挂掉的话,整个宿主机上所有的容器都得退出了,而引入 containerd-shim 这个垫片就可以来规避这个问题了。
然后创建容器需要做一些 namespaces 和 cgroups 的配置,以及挂载 root 文件系统等操作,这些操作其实已经有了标准的规范,那就是 OCI(开放容器标准),runc 就是它的一个参考实现(Docker 被逼无耐将 libcontainer 捐献出来改名为 runc 的),这个标准其实就是一个文档,主要规定了容器镜像的结构、以及容器需要接收哪些操作指令,比如 create、start、stop、delete 等这些命令。runc 就可以按照这个 OCI 文档来创建一个符合规范的容器,既然是标准肯定就有其他 OCI 实现,比如 Kata、gVisor 这些容器运行时都是符合 OCI 标准的。
所以真正启动容器是通过 containerd-shim 去调用 runc 来启动容器的,runc 启动完容器后本身会直接退出,containerd-shim 则会成为容器进程的父进程, 负责收集容器进程的状态, 上报给 containerd, 并在容器中 pid 为 1 的进程退出后接管容器中的子进程进行清理, 确保不会出现僵尸进程。
而 Docker 将容器操作都迁移到 containerd 中去是因为当前做 Swarm,想要进军 PaaS 市场,做了这个架构切分,让 Docker Daemon 专门去负责上层的封装编排,当然后面的结果我们知道 Swarm 在 Kubernetes 面前是惨败,然后 Docker 公司就把 containerd 项目捐献给了 CNCF 基金会,这个也是现在的 Docker 架构。
CRI
我们知道 Kubernetes 提供了一个 CRI 的容器运行时接口,那么这个 CRI 到底是什么呢?这个其实也和 Docker 的发展密切相关的。
在 Kubernetes 早期的时候,当时 Docker 实在是太火了,Kubernetes 当然会先选择支持 Docker,而且是通过硬编码的方式直接调用 Docker API,后面随着 Docker 的不断发展以及 Google 的主导,出现了更多容器运行时,Kubernetes 为了支持更多更精简的容器运行时,Google 就和红帽主导推出了 CRI 标准,用于将 Kubernetes 平台和特定的容器运行时(当然主要是为了干掉 Docker)解耦。
CRI(Container Runtime Interface 容器运行时接口)本质上就是 Kubernetes 定义的一组与容器运行时进行交互的接口,所以只要实现了这套接口的容器运行时都可以对接到 Kubernetes 平台上来。不过 Kubernetes 推出 CRI 这套标准的时候还没有现在的统治地位,所以有一些容器运行时可能不会自身就去实现 CRI 接口,于是就有了 shim(垫片), 一个 shim 的职责就是作为适配器将各种容器运行时本身的接口适配到 Kubernetes 的 CRI 接口上,其中 dockershim 就是 Kubernetes 对接 Docker 到 CRI 接口上的一个垫片实现。
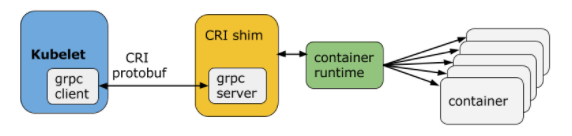
Kubelet 通过 gRPC 框架与容器运行时或 shim 进行通信,其中 kubelet 作为客户端,CRI shim(也可能是容器运行时本身)作为服务器。
CRI 定义的 API 主要包括两个 gRPC 服务,ImageService 和 RuntimeService,ImageService 服务主要是拉取镜像、查看和删除镜像等操作,RuntimeService 则是用来管理 Pod 和容器的生命周期,以及与容器交互的调用(exec/attach/port-forward)等操作,可以通过 kubelet 中的标志 --container-runtime-endpoint 和 --image-service-endpoint 来配置这两个服务的套接字。
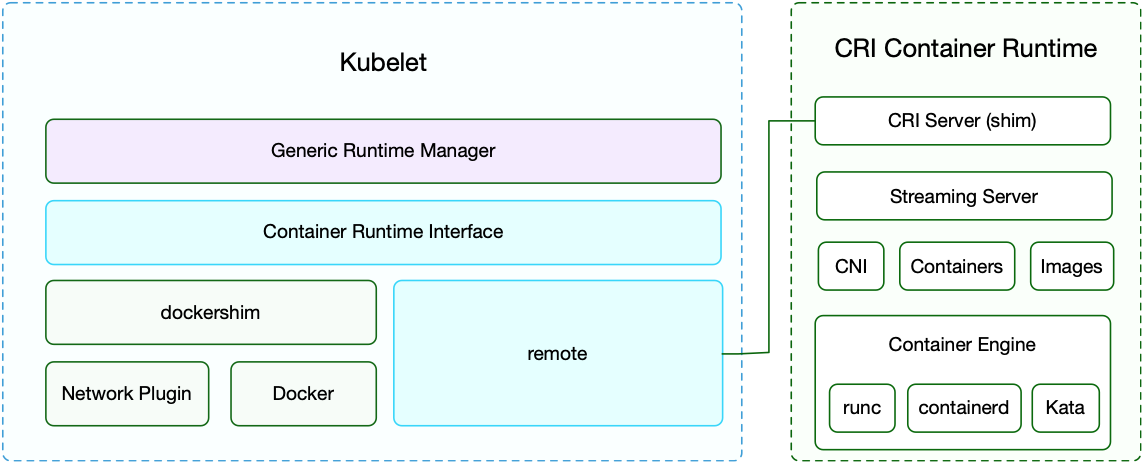
不过这里同样也有一个例外,那就是 Docker,由于 Docker 当时的江湖地位很高,Kubernetes 是直接内置了 dockershim 在 kubelet 中的,所以如果你使用的是 Docker 这种容器运行时的话是不需要单独去安装配置适配器之类的,当然这个举动似乎也麻痹了 Docker 公司。
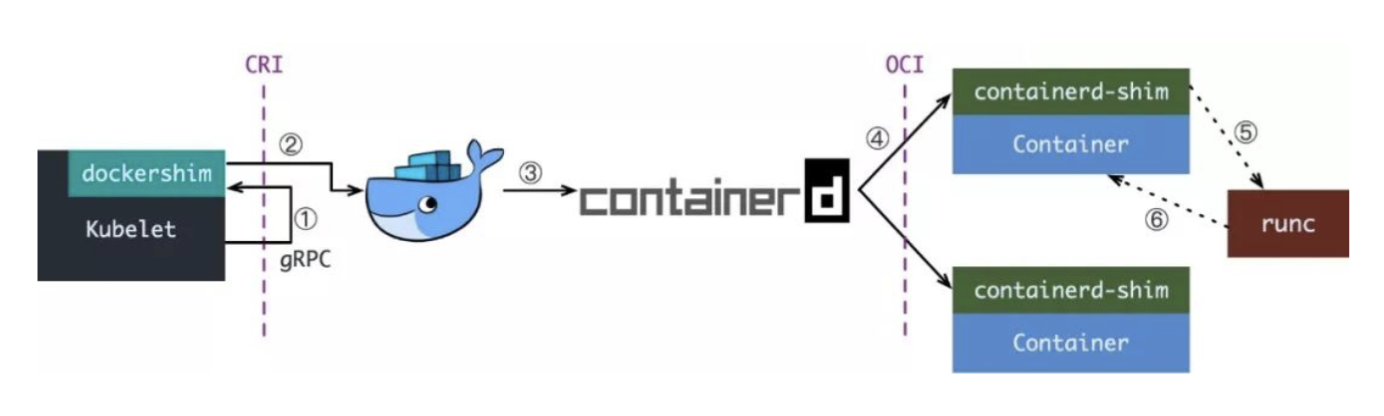
现在如果我们使用的是 Docker 的话,当我们在 Kubernetes 中创建一个 Pod 的时候,首先就是 kubelet 通过 CRI 接口调用 dockershim,请求创建一个容器,kubelet 可以视作一个简单的 CRI Client, 而 dockershim 就是接收请求的 Server,不过他们都是在 kubelet 内置的。
dockershim 收到请求后, 转化成 Docker Daemon 能识别的请求, 发到 Docker Daemon 上请求创建一个容器,请求到了 Docker Daemon 后续就是 Docker 创建容器的流程了,去调用 containerd,然后创建 containerd-shim 进程,通过该进程去调用 runc 去真正创建容器。
其实我们仔细观察也不难发现使用 Docker 的话其实是调用链比较长的,真正容器相关的操作其实 containerd 就完全足够了,Docker 太过于复杂笨重了,当然 Docker 深受欢迎的很大一个原因就是提供了很多对用户操作比较友好的功能,但是对于 Kubernetes 来说压根不需要这些功能,因为都是通过接口去操作容器的,所以自然也就可以将容器运行时切换到 containerd 来。
切换到 containerd 可以消除掉中间环节,操作体验也和以前一样,但是由于直接用容器运行时调度容器,所以它们对 Docker 来说是不可见的。 因此,你以前用来检查这些容器的 Docker 工具就不能使用了。
你不能再使用 docker ps 或 docker inspect 命令来获取容器信息。由于不能列出容器,因此也不能获取日志、停止容器,甚至不能通过 docker exec 在容器中执行命令。
当然我们仍然可以下载镜像,或者用 docker build 命令构建镜像,但用 Docker 构建、下载的镜像,对于容器运行时和 Kubernetes,均不可见。为了在 Kubernetes 中使用,需要把镜像推送到镜像仓库中去。
从上图可以看出在 containerd 1.0 中,对 CRI 的适配是通过一个单独的 CRI-Containerd 进程来完成的,这是因为最开始 containerd 还会去适配其他的系统(比如 swarm),所以没有直接实现 CRI,所以这个对接工作就交给 CRI-Containerd 这个 shim 了。
然后到了 containerd 1.1 版本后就去掉了 CRI-Containerd 这个 shim,直接把适配逻辑作为插件的方式集成到了 containerd 主进程中,现在这样的调用就更加简洁了。
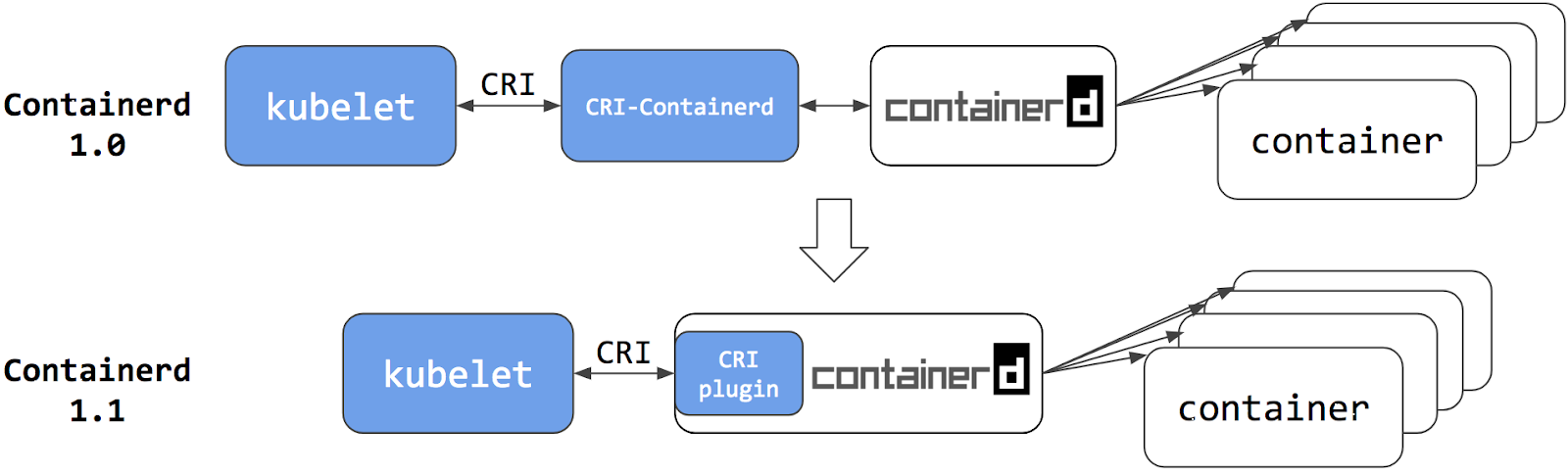
与此同时 Kubernetes 社区也做了一个专门用于 Kubernetes 的 CRI 运行时 CRI-O,直接兼容 CRI 和 OCI 规范。
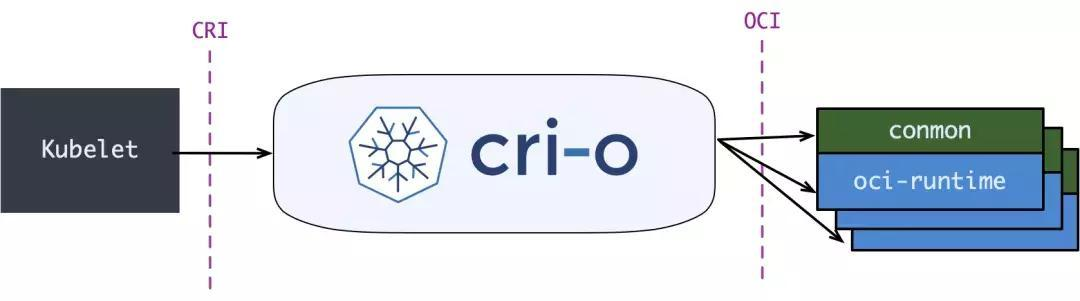
这个方案和 containerd 的方案显然比默认的 dockershim 简洁很多,不过由于大部分用户都比较习惯使用 Docker,所以大家还是更喜欢使用 dockershim 方案。
但是随着 CRI 方案的发展,以及其他容器运行时对 CRI 的支持越来越完善,Kubernetes 社区在 2020 年 7 月份就开始着手移除 dockershim 方案了:https://github.com/kubernetes/enhancements/tree/master/keps/sig-node/2221-remove-dockershim,现在的移除计划是在 1.20 版本中将 kubelet 中内置的 dockershim 代码分离,将内置的 dockershim 标记为维护模式,当然这个时候仍然还可以使用 dockershim,目标是在 1.23/1.24 版本发布没有 dockershim 的版本(代码还在,但是要默认支持开箱即用的 docker 需要自己构建 kubelet,会在某个宽限期过后从 kubelet 中删除内置的 dockershim 代码)。
那么这是否就意味这 Kubernetes 不再支持 Docker 了呢?当然不是的,这只是废弃了内置的 dockershim 功能而已,Docker 和其他容器运行时将一视同仁,不会单独对待内置支持,如果我们还想直接使用 Docker 这种容器运行时应该怎么办呢?可以将 dockershim 的功能单独提取出来独立维护一个 cri-dockerd 即可,就类似于 containerd 1.0 版本中提供的 CRI-Containerd,当然还有一种办法就是 Docker 官方社区将 CRI 接口内置到 Dockerd 中去实现。
但是我们也清楚 Dockerd 也是去直接调用的 Containerd,而 containerd 1.1 版本后就内置实现了 CRI,所以 Docker 也没必要再去单独实现 CRI 了,当 Kubernetes 不再内置支持开箱即用的 Docker 的以后,最好的方式当然也就是直接使用 Containerd 这种容器运行时,而且该容器运行时也已经经过了生产环境实践的,接下来我们就来学习下 Containerd 的使用。
Containerd 使用
我们知道很早之前的 Docker Engine 中就有了 containerd,只不过现在是将 containerd 从 Docker Engine 里分离出来,作为一个独立的开源项目,目标是提供一个更加开放、稳定的容器运行基础设施。分离出来的 containerd 将具有更多的功能,涵盖整个容器运行时管理的所有需求,提供更强大的支持。
containerd 是一个工业级标准的容器运行时,它强调简单性、健壮性和可移植性,containerd 可以负责干下面这些事情:
- 管理容器的生命周期(从创建容器到销毁容器)
- 拉取/推送容器镜像
- 存储管理(管理镜像及容器数据的存储)
- 调用 runc 运行容器(与 runc 等容器运行时交互)
- 管理容器网络接口及网络
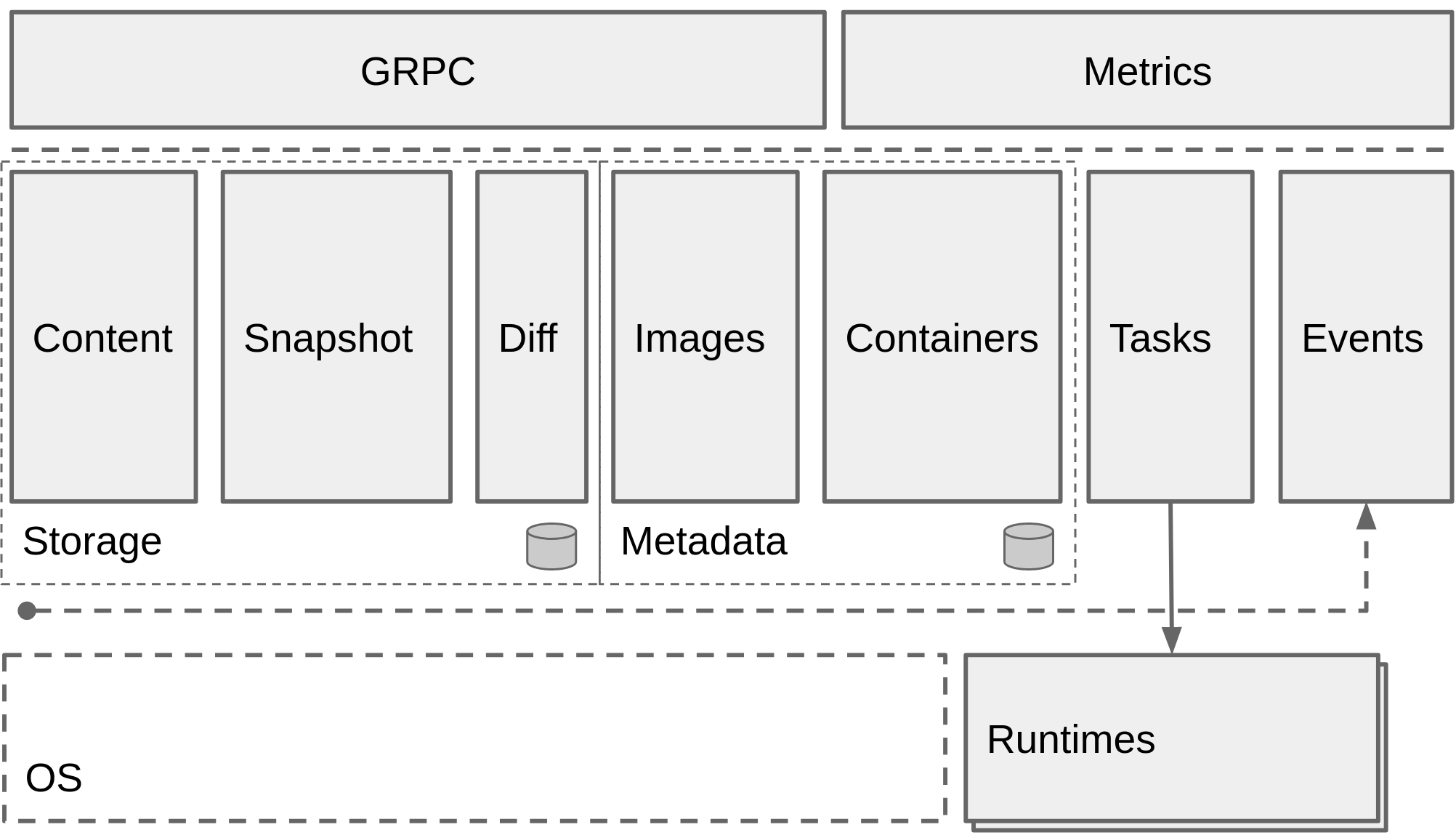
架构
containerd 可用作 Linux 和 Windows 的守护程序,它管理其主机系统完整的容器生命周期,从镜像传输和存储到容器执行和监测,再到底层存储到网络附件等等。
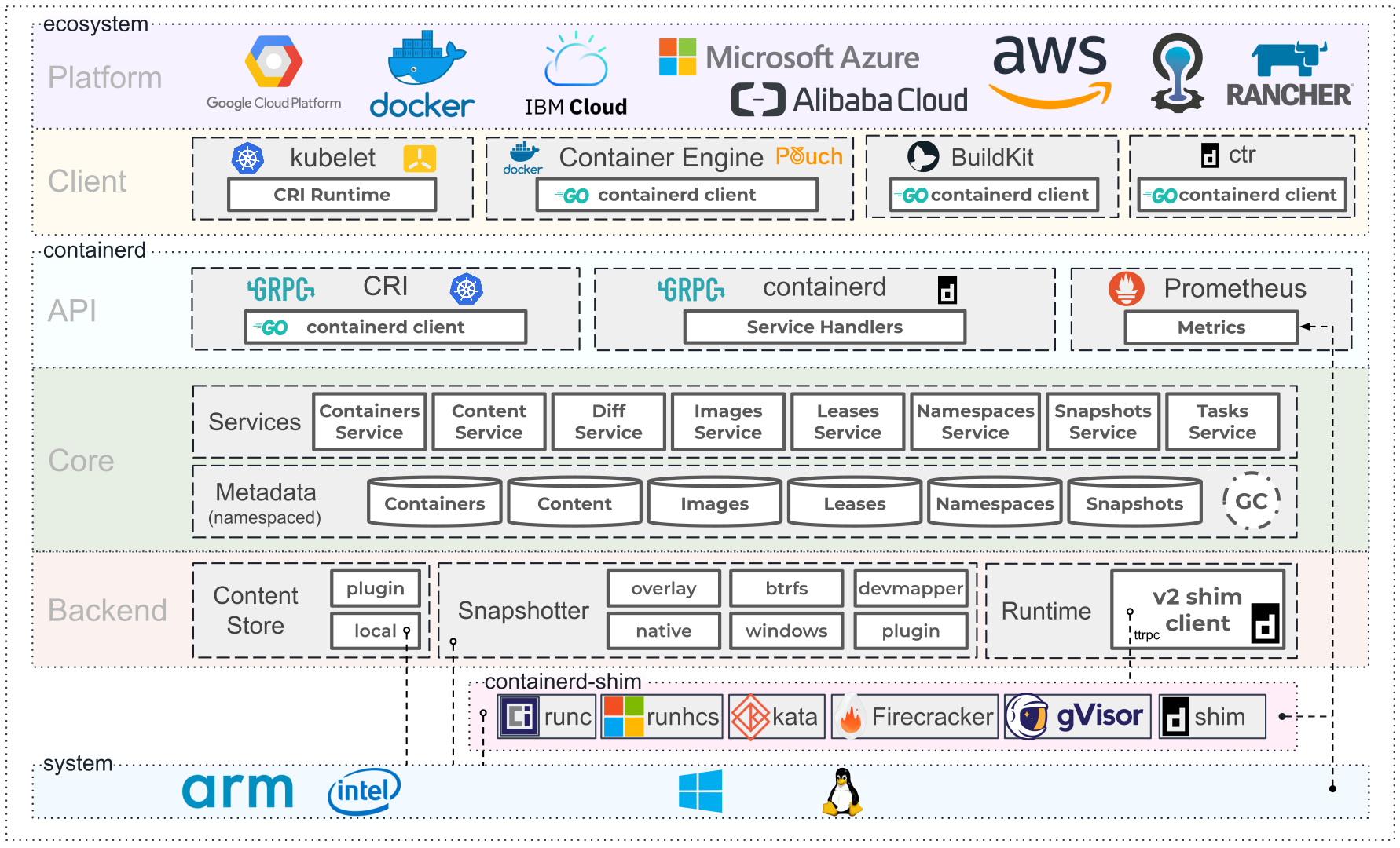
上图是 containerd 官方提供的架构图,可以看出 containerd 采用的也是 C/S 架构,服务端通过 unix domain socket 暴露低层的 gRPC API 接口出去,客户端通过这些 API 管理节点上的容器,每个 containerd 只负责一台机器,Pull 镜像,对容器的操作(启动、停止等),网络,存储都是由 containerd 完成。具体运行容器由 runc 负责,实际上只要是符合 OCI 规范的容器都可以支持。
为了解耦,containerd 将系统划分成了不同的组件,每个组件都由一个或多个模块协作完成(Core 部分),每一种类型的模块都以插件的形式集成到 Containerd 中,而且插件之间是相互依赖的,例如,上图中的每一个长虚线的方框都表示一种类型的插件,包括 Service Plugin、Metadata Plugin、GC Plugin、Runtime Plugin 等,其中 Service Plugin 又会依赖 Metadata Plugin、GC Plugin 和 Runtime Plugin。每一个小方框都表示一个细分的插件,例如 Metadata Plugin 依赖 Containers Plugin、Content Plugin 等。比如:
Content Plugin: 提供对镜像中可寻址内容的访问,所有不可变的内容都被存储在这里。Snapshot Plugin: 用来管理容器镜像的文件系统快照,镜像中的每一层都会被解压成文件系统快照,类似于 Docker 中的 graphdriver。
总体来看 containerd 可以分为三个大块:Storage、Metadata 和 Runtime。
安装
这里我使用的系统是 CentOS 7.6,首先需要安装 seccomp 依赖:
➜ ~ rpm -qa |grep libseccomp
libseccomp-2.3.1-4.el7.x86_64
# 如果没有安装 libseccomp 包则执行下面的命令安装依赖
➜ ~ yum install wget -y
➜ ~ wget http://mirror.centos.org/centos/7/os/x86_64/Packages/libseccomp-2.3.1-4.el7.x86_64.rpm
➜ ~ yum install libseccomp-2.3.1-4.el7.x86_64.rpm -y由于 containerd 需要调用 runc,所以我们也需要先安装 runc,不过 containerd 提供了一个包含相关依赖的压缩包 cri-containerd-cni-${VERSION}.${OS}-${ARCH}.tar.gz,可以直接使用这个包来进行安装。首先从 release 页面下载最新版本的压缩包,当前为 1.5.5 版本(最新的 1.5.7 版本在 CentOS7 下面执行 runc 会报错:https://github.com/containerd/containerd/issues/6091):
➜ ~ wget https://github.com/containerd/containerd/releases/download/v1.5.5/cri-containerd-cni-1.5.5-linux-amd64.tar.gz
# 如果有限制,也可以替换成下面的 URL 加速下载
# wget https://download.fastgit.org/containerd/containerd/releases/download/v1.5.5/cri-containerd-cni-1.5.5-linux-amd64.tar.gz可以通过 tar 的 -t 选项直接看到压缩包中包含哪些文件:
➜ ~ tar -tf cri-containerd-cni-1.5.5-linux-amd64.tar.gz
etc/
etc/cni/
etc/cni/net.d/
etc/cni/net.d/10-containerd-net.conflist
etc/crictl.yaml
etc/systemd/
etc/systemd/system/
etc/systemd/system/containerd.service
usr/
usr/local/
usr/local/bin/
usr/local/bin/containerd-shim-runc-v2
usr/local/bin/ctr
usr/local/bin/containerd-shim
usr/local/bin/containerd-shim-runc-v1
usr/local/bin/crictl
usr/local/bin/critest
usr/local/bin/containerd
usr/local/sbin/
usr/local/sbin/runc
opt/
opt/cni/
opt/cni/bin/
opt/cni/bin/vlan
opt/cni/bin/host-local
opt/cni/bin/flannel
opt/cni/bin/bridge
opt/cni/bin/host-device
opt/cni/bin/tuning
opt/cni/bin/firewall
opt/cni/bin/bandwidth
opt/cni/bin/ipvlan
opt/cni/bin/sbr
opt/cni/bin/dhcp
opt/cni/bin/portmap
opt/cni/bin/ptp
opt/cni/bin/static
opt/cni/bin/macvlan
opt/cni/bin/loopback
opt/containerd/
opt/containerd/cluster/
opt/containerd/cluster/version
opt/containerd/cluster/gce/
opt/containerd/cluster/gce/cni.template
opt/containerd/cluster/gce/configure.sh
opt/containerd/cluster/gce/cloud-init/
opt/containerd/cluster/gce/cloud-init/master.yaml
opt/containerd/cluster/gce/cloud-init/node.yaml
opt/containerd/cluster/gce/env直接将压缩包解压到系统的各个目录中:
➜ ~ tar -C / -xzf cri-containerd-cni-1.5.5-linux-amd64.tar.gz当然要记得将 /usr/local/bin 和 /usr/local/sbin 追加到 ~/.bashrc 文件的 PATH 环境变量中:
export PATH=$PATH:/usr/local/bin:/usr/local/sbin然后执行下面的命令使其立即生效:
➜ ~ source ~/.bashrccontainerd 的默认配置文件为 /etc/containerd/config.toml,我们可以通过如下所示的命令生成一个默认的配置:
➜ ~ mkdir -p /etc/containerd
➜ ~ containerd config default > /etc/containerd/config.toml由于上面我们下载的 containerd 压缩包中包含一个 etc/systemd/system/containerd.service 的文件,这样我们就可以通过 systemd 来配置 containerd 作为守护进程运行了,内容如下所示:
➜ ~ cat /etc/systemd/system/containerd.service
[Unit]
Description=containerd container runtime
Documentation=https://containerd.io
After=network.target local-fs.target
[Service]
ExecStartPre=-/sbin/modprobe overlay
ExecStart=/usr/local/bin/containerd
Type=notify
Delegate=yes
KillMode=process
Restart=always
RestartSec=5
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNPROC=infinity
LimitCORE=infinity
LimitNOFILE=1048576
# Comment TasksMax if your systemd version does not supports it.
# Only systemd 226 and above support this version.
TasksMax=infinity
OOMScoreAdjust=-999
[Install]
WantedBy=multi-user.target这里有两个重要的参数:
Delegate: 这个选项允许 containerd 以及运行时自己管理自己创建容器的 cgroups。如果不设置这个选项,systemd 就会将进程移到自己的 cgroups 中,从而导致 containerd 无法正确获取容器的资源使用情况。KillMode: 这个选项用来处理 containerd 进程被杀死的方式。默认情况下,systemd 会在进程的 cgroup 中查找并杀死 containerd 的所有子进程。KillMode 字段可以设置的值如下。control-group(默认值):当前控制组里面的所有子进程,都会被杀掉process:只杀主进程mixed:主进程将收到 SIGTERM 信号,子进程收到 SIGKILL 信号none:没有进程会被杀掉,只是执行服务的 stop 命令
我们需要将 KillMode 的值设置为 process,这样可以确保升级或重启 containerd 时不杀死现有的容器。
现在我们就可以启动 containerd 了,直接执行下面的命令即可:
➜ ~ systemctl enable containerd --now启动完成后就可以使用 containerd 的本地 CLI 工具 ctr 了,比如查看版本:
配置
我们首先来查看下上面默认生成的配置文件 /etc/containerd/config.toml:
disabled_plugins = []
imports = []
oom_score = 0
plugin_dir = ""
required_plugins = []
root = "/var/lib/containerd"
state = "/run/containerd"
version = 2
[cgroup]
path = ""
[debug]
address = ""
format = ""
gid = 0
level = ""
uid = 0
[grpc]
address = "/run/containerd/containerd.sock"
gid = 0
max_recv_message_size = 16777216
max_send_message_size = 16777216
tcp_address = ""
tcp_tls_cert = ""
tcp_tls_key = ""
uid = 0
[metrics]
address = ""
grpc_histogram = false
[plugins]
[plugins."io.containerd.gc.v1.scheduler"]
deletion_threshold = 0
mutation_threshold = 100
pause_threshold = 0.02
schedule_delay = "0s"
startup_delay = "100ms"
[plugins."io.containerd.grpc.v1.cri"]
disable_apparmor = false
disable_cgroup = false
disable_hugetlb_controller = true
disable_proc_mount = false
disable_tcp_service = true
enable_selinux = false
enable_tls_streaming = false
ignore_image_defined_volumes = false
max_concurrent_downloads = 3
max_container_log_line_size = 16384
netns_mounts_under_state_dir = false
restrict_oom_score_adj = false
sandbox_image = "k8s.gcr.io/pause:3.5"
selinux_category_range = 1024
stats_collect_period = 10
stream_idle_timeout = "4h0m0s"
stream_server_address = "127.0.0.1"
stream_server_port = "0"
systemd_cgroup = false
tolerate_missing_hugetlb_controller = true
unset_seccomp_profile = ""
[plugins."io.containerd.grpc.v1.cri".cni]
bin_dir = "/opt/cni/bin"
conf_dir = "/etc/cni/net.d"
conf_template = ""
max_conf_num = 1
[plugins."io.containerd.grpc.v1.cri".containerd]
default_runtime_name = "runc"
disable_snapshot_annotations = true
discard_unpacked_layers = false
no_pivot = false
snapshotter = "overlayfs"
[plugins."io.containerd.grpc.v1.cri".containerd.default_runtime]
base_runtime_spec = ""
container_annotations = []
pod_annotations = []
privileged_without_host_devices = false
runtime_engine = ""
runtime_root = ""
runtime_type = ""
[plugins."io.containerd.grpc.v1.cri".containerd.default_runtime.options]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
base_runtime_spec = ""
container_annotations = []
pod_annotations = []
privileged_without_host_devices = false
runtime_engine = ""
runtime_root = ""
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
BinaryName = ""
CriuImagePath = ""
CriuPath = ""
CriuWorkPath = ""
IoGid = 0
IoUid = 0
NoNewKeyring = false
NoPivotRoot = false
Root = ""
ShimCgroup = ""
SystemdCgroup = false
[plugins."io.containerd.grpc.v1.cri".containerd.untrusted_workload_runtime]
base_runtime_spec = ""
container_annotations = []
pod_annotations = []
privileged_without_host_devices = false
runtime_engine = ""
runtime_root = ""
runtime_type = ""
[plugins."io.containerd.grpc.v1.cri".containerd.untrusted_workload_runtime.options]
[plugins."io.containerd.grpc.v1.cri".image_decryption]
key_model = "node"
[plugins."io.containerd.grpc.v1.cri".registry]
config_path = ""
[plugins."io.containerd.grpc.v1.cri".registry.auths]
[plugins."io.containerd.grpc.v1.cri".registry.configs]
[plugins."io.containerd.grpc.v1.cri".registry.headers]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".x509_key_pair_streaming]
tls_cert_file = ""
tls_key_file = ""
[plugins."io.containerd.internal.v1.opt"]
path = "/opt/containerd"
[plugins."io.containerd.internal.v1.restart"]
interval = "10s"
[plugins."io.containerd.metadata.v1.bolt"]
content_sharing_policy = "shared"
[plugins."io.containerd.monitor.v1.cgroups"]
no_prometheus = false
[plugins."io.containerd.runtime.v1.linux"]
no_shim = false
runtime = "runc"
runtime_root = ""
shim = "containerd-shim"
shim_debug = false
[plugins."io.containerd.runtime.v2.task"]
platforms = ["linux/amd64"]
[plugins."io.containerd.service.v1.diff-service"]
default = ["walking"]
[plugins."io.containerd.snapshotter.v1.aufs"]
root_path = ""
[plugins."io.containerd.snapshotter.v1.btrfs"]
root_path = ""
[plugins."io.containerd.snapshotter.v1.devmapper"]
async_remove = false
base_image_size = ""
pool_name = ""
root_path = ""
[plugins."io.containerd.snapshotter.v1.native"]
root_path = ""
[plugins."io.containerd.snapshotter.v1.overlayfs"]
root_path = ""
[plugins."io.containerd.snapshotter.v1.zfs"]
root_path = ""
[proxy_plugins]
[stream_processors]
[stream_processors."io.containerd.ocicrypt.decoder.v1.tar"]
accepts = ["application/vnd.oci.image.layer.v1.tar+encrypted"]
args = ["--decryption-keys-path", "/etc/containerd/ocicrypt/keys"]
env = ["OCICRYPT_KEYPROVIDER_CONFIG=/etc/containerd/ocicrypt/ocicrypt_keyprovider.conf"]
path = "ctd-decoder"
returns = "application/vnd.oci.image.layer.v1.tar"
[stream_processors."io.containerd.ocicrypt.decoder.v1.tar.gzip"]
accepts = ["application/vnd.oci.image.layer.v1.tar+gzip+encrypted"]
args = ["--decryption-keys-path", "/etc/containerd/ocicrypt/keys"]
env = ["OCICRYPT_KEYPROVIDER_CONFIG=/etc/containerd/ocicrypt/ocicrypt_keyprovider.conf"]
path = "ctd-decoder"
returns = "application/vnd.oci.image.layer.v1.tar+gzip"
[timeouts]
"io.containerd.timeout.shim.cleanup" = "5s"
"io.containerd.timeout.shim.load" = "5s"
"io.containerd.timeout.shim.shutdown" = "3s"
"io.containerd.timeout.task.state" = "2s"
[ttrpc]
address = ""
gid = 0
uid = 0这个配置文件比较复杂,我们可以将重点放在其中的 plugins 配置上面,仔细观察我们可以发现每一个顶级配置块的命名都是 plugins."io.containerd.xxx.vx.xxx" 这种形式,每一个顶级配置块都表示一个插件,其中 io.containerd.xxx.vx 表示插件的类型,vx 后面的 xxx 表示插件的 ID,我们可以通过 ctr 查看插件列表:
➜ ~ ctr plugin ls
ctr plugin ls
TYPE ID PLATFORMS STATUS
io.containerd.content.v1 content - ok
io.containerd.snapshotter.v1 aufs linux/amd64 ok
io.containerd.snapshotter.v1 btrfs linux/amd64 skip
io.containerd.snapshotter.v1 devmapper linux/amd64 error
io.containerd.snapshotter.v1 native linux/amd64 ok
io.containerd.snapshotter.v1 overlayfs linux/amd64 ok
io.containerd.snapshotter.v1 zfs linux/amd64 skip
io.containerd.metadata.v1 bolt - ok
io.containerd.differ.v1 walking linux/amd64 ok
io.containerd.gc.v1 scheduler - ok
io.containerd.service.v1 introspection-service - ok
io.containerd.service.v1 containers-service - ok
io.containerd.service.v1 content-service - ok
io.containerd.service.v1 diff-service - ok
io.containerd.service.v1 images-service - ok
io.containerd.service.v1 leases-service - ok
io.containerd.service.v1 namespaces-service - ok
io.containerd.service.v1 snapshots-service - ok
io.containerd.runtime.v1 linux linux/amd64 ok
io.containerd.runtime.v2 task linux/amd64 ok
io.containerd.monitor.v1 cgroups linux/amd64 ok
io.containerd.service.v1 tasks-service - ok
io.containerd.internal.v1 restart - ok
io.containerd.grpc.v1 containers - ok
io.containerd.grpc.v1 content - ok
io.containerd.grpc.v1 diff - ok
io.containerd.grpc.v1 events - ok
io.containerd.grpc.v1 healthcheck - ok
io.containerd.grpc.v1 images - ok
io.containerd.grpc.v1 leases - ok
io.containerd.grpc.v1 namespaces - ok
io.containerd.internal.v1 opt - ok
io.containerd.grpc.v1 snapshots - ok
io.containerd.grpc.v1 tasks - ok
io.containerd.grpc.v1 version - ok
io.containerd.grpc.v1 cri linux/amd64 ok顶级配置块下面的子配置块表示该插件的各种配置,比如 cri 插件下面就分为 containerd、cni 和 registry 的配置,而 containerd 下面又可以配置各种 runtime,还可以配置默认的 runtime。比如现在我们要为镜像配置一个加速器,那么就需要在 cri 配置块下面的 registry 配置块下面进行配置 registry.mirrors:
[plugins."io.containerd.grpc.v1.cri".registry]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://bqr1dr1n.mirror.aliyuncs.com"]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."k8s.gcr.io"]
endpoint = ["https://registry.aliyuncs.com/k8sxio"]registry.mirrors."xxx": 表示需要配置 mirror 的镜像仓库,例如registry.mirrors."docker.io"表示配置 docker.io 的 mirror。endpoint: 表示提供 mirror 的镜像加速服务,比如我们可以注册一个阿里云的镜像服务来作为 docker.io 的 mirror。
另外在默认配置中还有两个关于存储的配置路径:
root = "/var/lib/containerd"
state = "/run/containerd"其中 root 是用来保存持久化数据,包括 Snapshots, Content, Metadata 以及各种插件的数据,每一个插件都有自己单独的目录,Containerd 本身不存储任何数据,它的所有功能都来自于已加载的插件。
而另外的 state 是用来保存运行时的临时数据的,包括 sockets、pid、挂载点、运行时状态以及不需要持久化的插件数据。
使用
我们知道 Docker CLI 工具提供了需要增强用户体验的功能,containerd 同样也提供一个对应的 CLI 工具:ctr,不过 ctr 的功能没有 docker 完善,但是关于镜像和容器的基本功能都是有的。接下来我们就先简单介绍下 ctr 的使用。
帮助
直接输入 ctr 命令即可获得所有相关的操作命令使用方式:
➜ ~ ctr
NAME:
ctr -
__
_____/ /______
/ ___/ __/ ___/
/ /__/ /_/ /
\___/\__/_/
containerd CLI
USAGE:
ctr [global options] command [command options] [arguments...]
VERSION:
v1.5.5
DESCRIPTION:
ctr is an unsupported debug and administrative client for interacting
with the containerd daemon. Because it is unsupported, the commands,
options, and operations are not guaranteed to be backward compatible or
stable from release to release of the containerd project.
COMMANDS:
plugins, plugin provides information about containerd plugins
version print the client and server versions
containers, c, container manage containers
content manage content
events, event display containerd events
images, image, i manage images
leases manage leases
namespaces, namespace, ns manage namespaces
pprof provide golang pprof outputs for containerd
run run a container
snapshots, snapshot manage snapshots
tasks, t, task manage tasks
install install a new package
oci OCI tools
shim interact with a shim directly
help, h Shows a list of commands or help for one command
GLOBAL OPTIONS:
--debug enable debug output in logs
--address value, -a value address for containerd's GRPC server (default: "/run/containerd/containerd.sock") [$CONTAINERD_ADDRESS]
--timeout value total timeout for ctr commands (default: 0s)
--connect-timeout value timeout for connecting to containerd (default: 0s)
--namespace value, -n value namespace to use with commands (default: "default") [$CONTAINERD_NAMESPACE]
--help, -h show help
--version, -v print the version镜像操作
拉取镜像
拉取镜像可以使用 ctr image pull 来完成,比如拉取 Docker Hub 官方镜像 nginx:alpine,需要注意的是镜像地址需要加上 docker.io Host 地址:
➜ ~ ctr image pull docker.io/library/nginx:alpine
docker.io/library/nginx:alpine: resolved |++++++++++++++++++++++++++++++++++++++|
index-sha256:bead42240255ae1485653a956ef41c9e458eb077fcb6dc664cbc3aa9701a05ce: exists |++++++++++++++++++++++++++++++++++++++|
manifest-sha256:ce6ca11a3fa7e0e6b44813901e3289212fc2f327ee8b1366176666e8fb470f24: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:9a6ac07b84eb50935293bb185d0a8696d03247f74fd7d43ea6161dc0f293f81f: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:e82f830de071ebcda58148003698f32205b7970b01c58a197ac60d6bb79241b0: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:d7c9fa7589ae28cd3306b204d5dd9a539612593e35df70f7a1d69ff7548e74cf: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:bf2b3ee132db5b4c65432e53aca69da4e609c6cb154e0d0e14b2b02259e9c1e3: done |++++++++++++++++++++++++++++++++++++++|
config-sha256:7ce0143dee376bfd2937b499a46fb110bda3c629c195b84b1cf6e19be1a9e23b: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:3c1eaf69ff492177c34bdbf1735b6f2e5400e417f8f11b98b0da878f4ecad5fb: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:29291e31a76a7e560b9b7ad3cada56e8c18d50a96cca8a2573e4f4689d7aca77: done |++++++++++++++++++++++++++++++++++++++|
elapsed: 11.9s total: 8.7 Mi (748.1 KiB/s)
unpacking linux/amd64 sha256:bead42240255ae1485653a956ef41c9e458eb077fcb6dc664cbc3aa9701a05ce...
done: 410.86624ms也可以使用 --platform 选项指定对应平台的镜像。当然对应的也有推送镜像的命令 ctr image push,如果是私有镜像则在推送的时候可以通过 --user 来自定义仓库的用户名和密码。
列出本地镜像
➜ ~ ctr image ls
REF TYPE DIGEST SIZE PLATFORMS LABELS
docker.io/library/nginx:alpine application/vnd.docker.distribution.manifest.list.v2+json sha256:bead42240255ae1485653a956ef41c9e458eb077fcb6dc664cbc3aa9701a05ce 9.5 MiB linux/386,linux/amd64,linux/arm/v6,linux/arm/v7,linux/arm64/v8,linux/ppc64le,linux/s390x -
➜ ~ ctr image ls -q
docker.io/library/nginx:alpine使用 -q(--quiet) 选项可以只打印镜像名称。
检测本地镜像
➜ ~ ctr image check
REF TYPE DIGEST STATUS SIZE UNPACKED
docker.io/library/nginx:alpine application/vnd.docker.distribution.manifest.list.v2+json sha256:bead42240255ae1485653a956ef41c9e458eb077fcb6dc664cbc3aa9701a05ce complete (7/7) 9.5 MiB/9.5 MiB true主要查看其中的 STATUS,complete 表示镜像是完整可用的状态。
重新打标签
同样的我们也可以重新给指定的镜像打一个 Tag:
➜ ~ ctr image tag docker.io/library/nginx:alpine harbor.k8s.local/course/nginx:alpine
harbor.k8s.local/course/nginx:alpine
➜ ~ ctr image ls -q
docker.io/library/nginx:alpine
harbor.k8s.local/course/nginx:alpine删除镜像
不需要使用的镜像也可以使用 ctr image rm 进行删除:
➜ ~ ctr image rm harbor.k8s.local/course/nginx:alpine
harbor.k8s.local/course/nginx:alpine
➜ ~ ctr image ls -q
docker.io/library/nginx:alpine加上 --sync 选项可以同步删除镜像和所有相关的资源。
将镜像挂载到主机目录
➜ ~ ctr image mount docker.io/library/nginx:alpine /mnt
sha256:c3554b2d61e3c1cffcaba4b4fa7651c644a3354efaafa2f22cb53542f6c600dc
/mnt
➜ ~ tree -L 1 /mnt
/mnt
├── bin
├── dev
├── docker-entrypoint.d
├── docker-entrypoint.sh
├── etc
├── home
├── lib
├── media
├── mnt
├── opt
├── proc
├── root
├── run
├── sbin
├── srv
├── sys
├── tmp
├── usr
└── var
18 directories, 1 file将镜像从主机目录上卸载
➜ ~ ctr image unmount /mnt
/mnt将镜像导出为压缩包
➜ ~ ctr image export --all-platforms nginx.tar.gz docker.io/library/nginx:alpine从压缩包导入镜像
➜ ~ ctr image import nginx.tar.gz直接导入可能会出现类似于 ctr: content digest sha256:xxxxxx not found 的错误,要解决这个办法需要 pull 所有平台镜像:
➜ ~ ctr i pull --all-platforms docker.io/library/nginx:alpine
➜ ~ ctr i export --all-platforms nginx.tar.gz docker.io/library/nginx:alpine
➜ ~ ctr i rm docker.io/library/nginx:alpine
➜ ~ ctr i import nginx.tar.gz容器操作
容器相关操作可以通过 ctr container 获取。
创建容器
➜ ~ ctr container create docker.io/library/nginx:alpine nginx列出容器
➜ ~ ctr container ls
CONTAINER IMAGE RUNTIME
nginx docker.io/library/nginx:alpine io.containerd.runc.v2同样可以加上 -q 选项精简列表内容:
➜ ~ ctr container ls -q
nginx查看容器详细配置
类似于 docker inspect 功能。
➜ ~ ctr container info nginx
{
"ID": "nginx",
"Labels": {
"io.containerd.image.config.stop-signal": "SIGQUIT"
},
"Image": "docker.io/library/nginx:alpine",
"Runtime": {
"Name": "io.containerd.runc.v2",
"Options": {
"type_url": "containerd.runc.v1.Options"
}
},
"SnapshotKey": "nginx",
"Snapshotter": "overlayfs",
"CreatedAt": "2021-08-12T08:23:13.792871558Z",
"UpdatedAt": "2021-08-12T08:23:13.792871558Z",
"Extensions": null,
"Spec": {
......删除容器
➜ ~ ctr container rm nginx
➜ ~ ctr container ls
CONTAINER IMAGE RUNTIME除了使用 rm 子命令之外也可以使用 delete 或者 del 删除容器。
任务
上面我们通过 container create 命令创建的容器,并没有处于运行状态,只是一个静态的容器。一个 container 对象只是包含了运行一个容器所需的资源及相关配置数据,表示 namespaces、rootfs 和容器的配置都已经初始化成功了,只是用户进程还没有启动。
一个容器真正运行起来是由 Task 任务实现的,Task 可以为容器设置网卡,还可以配置工具来对容器进行监控等。
Task 相关操作可以通过 ctr task 获取,如下我们通过 Task 来启动容器:
➜ ~ ctr task start -d nginx
/docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
/docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/启动容器后可以通过 task ls 查看正在运行的容器:
➜ ~ ctr task ls
TASK PID STATUS
nginx 3630 RUNNING同样也可以使用 exec 命令进入容器进行操作:
➜ ~ ctr task exec --exec-id 0 -t nginx sh
/ #不过这里需要注意必须要指定 --exec-id 参数,这个 id 可以随便写,只要唯一就行。
暂停容器,和 docker pause 类似的功能:
➜ ~ ctr task pause nginx暂停后容器状态变成了 PAUSED:
➜ ~ ctr task ls
TASK PID STATUS
nginx 3630 PAUSED同样也可以使用 resume 命令来恢复容器:
➜ ~ ctr task resume nginx
➜ ~ ctr task ls
TASK PID STATUS
nginx 3630 RUNNING不过需要注意 ctr 没有 stop 容器的功能,只能暂停或者杀死容器。杀死容器可以使用 task kill 命令:
➜ ~ ctr task kill nginx
➜ ~ ctr task ls
TASK PID STATUS
nginx 3630 STOPPED杀掉容器后可以看到容器的状态变成了 STOPPED。同样也可以通过 task rm 命令删除 Task:
➜ ~ ctr task rm nginx
➜ ~ ctr task ls
TASK PID STATUS除此之外我们还可以获取容器的 cgroup 相关信息,可以使用 task metrics 命令用来获取容器的内存、CPU 和 PID 的限额与使用量。
# 重新启动容器
➜ ~ ctr task metrics nginx
ID TIMESTAMP
nginx 2021-08-12 08:50:46.952769941 +0000 UTC
METRIC VALUE
memory.usage_in_bytes 8855552
memory.limit_in_bytes 9223372036854771712
memory.stat.cache 0
cpuacct.usage 22467106
cpuacct.usage_percpu [2962708 860891 1163413 1915748 1058868 2888139 6159277 5458062]
pids.current 9
pids.limit 0还可以使用 task ps 命令查看容器中所有进程在宿主机中的 PID:
➜ ~ ctr task ps nginx
PID INFO
3984 -
4029 -
4030 -
4031 -
4032 -
4033 -
4034 -
4035 -
4036 -
➜ ~ ctr task ls
TASK PID STATUS
nginx 3984 RUNNING其中第一个 PID 3984 就是我们容器中的 1 号进程。
命名空间
另外 Containerd 中也支持命名空间的概念,比如查看命名空间:
➜ ~ ctr ns ls
NAME LABELS
default如果不指定,ctr 默认使用的是 default 空间。同样也可以使用 ns create 命令创建一个命名空间:
➜ ~ ctr ns create test
➜ ~ ctr ns ls
NAME LABELS
default
test使用 remove 或者 rm 可以删除 namespace:
➜ ~ ctr ns rm test
test
➜ ~ ctr ns ls
NAME LABELS
default有了命名空间后就可以在操作资源的时候指定 namespace,比如查看 test 命名空间的镜像,可以在操作命令后面加上 -n test 选项:
➜ ~ ctr -n test image ls
REF TYPE DIGEST SIZE PLATFORMS LABELS我们知道 Docker 其实也是默认调用的 containerd,事实上 Docker 使用的 containerd 下面的命名空间默认是 moby,而不是 default,所以假如我们有用 docker 启动容器,那么我们也可以通过 ctr -n moby 来定位下面的容器:
➜ ~ ctr -n moby container ls同样 Kubernetes 下使用的 containerd 默认命名空间是 k8s.io,所以我们可以使用 ctr -n k8s.io 来查看 Kubernetes 下面创建的容器。
Containerd 命令行工具 nerdctl
前面我们介绍了可以使用 ctr 操作管理 containerd 镜像容器,但是大家都习惯了使用 docker cli,ctr 使用起来可能还是不太顺手,为了能够让大家更好的转到 containerd 上面来,社区提供了一个新的命令行工具:nerdctl。nerdctl 是一个与 docker cli 风格兼容的 containerd 客户端工具,而且直接兼容 docker compose 的语法的,这就大大提高了直接将 containerd 作为本地开发、测试或者单机容器部署使用的效率。
安装
同样直接在 GitHub Release 页面下载对应的压缩包解压到 PATH 路径下即可:
# 如果没有安装 containerd,则可以下载 nerdctl-full-<VERSION>-linux-amd64.tar.gz 包进行安装
➜ ~ wget https://github.com/containerd/nerdctl/releases/download/v0.12.1/nerdctl-0.12.1-linux-amd64.tar.gz
# 如果有限制,也可以替换成下面的 URL 加速下载
# wget https://download.fastgit.org/containerd/nerdctl/releases/download/v0.12.1/nerdctl-0.12.1-linux-amd64.tar.gz
➜ ~ mkdir -p /usr/local/containerd/bin/ && tar -zxvf nerdctl-0.12.1-linux-amd64.tar.gz nerdctl && mv nerdctl /usr/local/containerd/bin/
➜ ~ ln -s /usr/local/containerd/bin/nerdctl /usr/local/bin/nerdctl
➜ ~ nerdctl version
Client:
Version: v0.12.1
Git commit: c802f934791f83dacf20a041cd1c865f8fac954e
Server:
containerd:
Version: v1.5.5
Revision: 72cec4be58a9eb6b2910f5d10f1c01ca47d231c0安装完成后接下来学习下 nerdctl 命令行工具的使用。
命令
Run&Exec
🐳nerdctl run
和 docker run 类似可以使用 nerdctl run 命令运行容器,例如:
➜ ~ nerdctl run -d -p 80:80 --name=nginx --restart=always nginx:alpine
docker.io/library/nginx:alpine: resolved |++++++++++++++++++++++++++++++++++++++|
index-sha256:bead42240255ae1485653a956ef41c9e458eb077fcb6dc664cbc3aa9701a05ce: done |++++++++++++++++++++++++++++++++++++++| manifest-sha256:ce6ca11a3fa7e0e6b44813901e3289212fc2f327ee8b1366176666e8fb470f24: done |++++++++++++++++++++++++++++++++++++++| config-sha256:7ce0143dee376bfd2937b499a46fb110bda3c629c195b84b1cf6e19be1a9e23b: done |++++++++++++++++++++++++++++++++++++++| elapsed: 5.3 s total: 3.1 Ki (606.0 B/s) 6e489777d2f73dda8a310cdf8da9df38353c1aa2021d3c2270b30eff1806bcf8可选的参数使用和 docker run 基本一直,比如 -i、-t、--cpus、--memory 等选项,可以使用 nerdctl run --help 获取可使用的命令选项:
➜ ~ nerdctl run --help
NAME:
nerdctl run - Run a command in a new container
USAGE:
nerdctl run [command options] [arguments...]
OPTIONS:
--help show help (default: false)
--tty, -t (Currently -t needs to correspond to -i) (default: false)
--interactive, -i Keep STDIN open even if not attached (default: false)
--detach, -d Run container in background and print container ID (default: false)
--restart value Restart policy to apply when a container exits (implemented values: "no"|"always") (default: "no")
--rm Automatically remove the container when it exits (default: false)
--pull value Pull image before running ("always"|"missing"|"never") (default: "missing")
--network value, --net value Connect a container to a network ("bridge"|"host"|"none") (default: "bridge")
--dns value Set custom DNS servers (default: "8.8.8.8", "1.1.1.1")
--publish value, -p value Publish a container's port(s) to the host
--hostname value, -h value Container host name
--cpus value Number of CPUs (default: 0)
--memory value, -m value Memory limit
--pid value PID namespace to use
--pids-limit value Tune container pids limit (set -1 for unlimited) (default: -1)
--cgroupns value Cgroup namespace to use, the default depends on the cgroup version ("host"|"private") (default: "host")
--cpuset-cpus value CPUs in which to allow execution (0-3, 0,1)
--cpu-shares value CPU shares (relative weight) (default: 0)
--device value Add a host device to the container
--user value, -u value Username or UID (format: <name|uid>[:<group|gid>])
--security-opt value Security options
--cap-add value Add Linux capabilities
--cap-drop value Drop Linux capabilities
--privileged Give extended privileges to this container (default: false)
--runtime value Runtime to use for this container, e.g. "crun", or "io.containerd.runsc.v1" (default: "io.containerd.runc.v2")
--sysctl value Sysctl options
--gpus value GPU devices to add to the container ('all' to pass all GPUs)
--volume value, -v value Bind mount a volume
--read-only Mount the container's root filesystem as read only (default: false)
--rootfs The first argument is not an image but the rootfs to the exploded container (default: false)
--entrypoint value Overwrite the default ENTRYPOINT of the image
--workdir value, -w value Working directory inside the container
--env value, -e value Set environment variables
--env-file value Set environment variables from file
--name value Assign a name to the container
--label value, -l value Set meta data on a container
--label-file value Read in a line delimited file of labels
--cidfile value Write the container ID to the file
--shm-size value Size of /dev/shm🐳nerdctl exec
同样也可以使用 exec 命令执行容器相关命令,例如:
➜ ~ nerdctl exec -it nginx /bin/sh
/ # date
Thu Aug 19 06:43:19 UTC 2021
/ #容器管理
🐳nerdctl ps:列出容器
使用 nerdctl ps 命令可以列出所有容器。
➜ ~ nerdctl ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6e489777d2f7 docker.io/library/nginx:alpine "/docker-entrypoint.…" 10 minutes ago Up 0.0.0.0:80->80/tcp nginx同样可以使用 -a 选项显示所有的容器列表,默认只显示正在运行的容器,不过需要注意的是 nerdctl ps 命令并没有实现 docker ps 下面的 --filter、--format、--last、--size 等选项。
🐳nerdctl inspect:获取容器的详细信息。
➜ ~ nerdctl inspect nginx
[
{
"Id": "6e489777d2f73dda8a310cdf8da9df38353c1aa2021d3c2270b30eff1806bcf8",
"Created": "2021-08-19T06:35:46.403464674Z",
"Path": "/docker-entrypoint.sh",
"Args": [
"nginx",
"-g",
"daemon off;"
],
"State": {
"Status": "running",
"Running": true,
"Paused": false,
"Pid": 2002,
"ExitCode": 0,
"FinishedAt": "0001-01-01T00:00:00Z"
},
"Image": "docker.io/library/nginx:alpine",
"ResolvConfPath": "/var/lib/nerdctl/1935db59/containers/default/6e489777d2f73dda8a310cdf8da9df38353c1aa2021d3c2270b30eff1806bcf8/resolv.conf",
"LogPath": "/var/lib/nerdctl/1935db59/containers/default/6e489777d2f73dda8a310cdf8da9df38353c1aa2021d3c2270b30eff1806bcf8/6e489777d2f73dda8a310cdf8da9df38353c1aa2021d3c2270b30eff1806bcf8-json.log",
"Name": "nginx",
"Driver": "overlayfs",
"Platform": "linux",
"AppArmorProfile": "nerdctl-default",
"NetworkSettings": {
"Ports": {
"80/tcp": [
{
"HostIp": "0.0.0.0",
"HostPort": "80"
}
]
},
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"IPAddress": "10.4.0.3",
"IPPrefixLen": 24,
"MacAddress": "f2:b1:8e:a2:fe:18",
"Networks": {
"unknown-eth0": {
"IPAddress": "10.4.0.3",
"IPPrefixLen": 24,
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"MacAddress": "f2:b1:8e:a2:fe:18"
}
}
}
}
]可以看到显示结果和 docker inspect 也基本一致的。
🐳nerdctl logs:获取容器日志
查看容器日志是我们平时经常会使用到的一个功能,同样我们可以使用 nerdctl logs 来获取日志数据:
➜ ~ nerdctl logs -f nginx
......
2021/08/19 06:35:46 [notice] 1#1: start worker processes
2021/08/19 06:35:46 [notice] 1#1: start worker process 32
2021/08/19 06:35:46 [notice] 1#1: start worker process 33同样支持 -f、-t、-n、--since、--until 这些选项。
🐳nerdctl stop:停止容器
➜ ~ nerdctl stop nginx
nginx
➜ ~ nerdctl ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
➜ ~ nerdctl ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6e489777d2f7 docker.io/library/nginx:alpine "/docker-entrypoint.…" 20 minutes ago Up 0.0.0.0:80->80/tcp nginx🐳nerdctl rm:删除容器
➜ ~ nerdctl rm nginx
You cannot remove a running container f4ac170235595f28bf962bad68aa81b20fc83b741751e7f3355bd77d8016462d. Stop the container before attempting removal or force remove
➜ ~ nerdctl rm -f ginx
nginx
➜ ~ nerdctl ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES要强制删除同样可以使用 -f 或 --force 选项来操作。
镜像管理
🐳nerdctl images:镜像列表
➜ ~ nerdctl images
REPOSITORY TAG IMAGE ID CREATED SIZE
alpine latest eb3e4e175ba6 6 days ago 5.9 MiB
nginx alpine bead42240255 29 minutes ago 16.0 KiB也需要注意的是没有实现 docker images 的一些选项,比如 --all、--digests、--filter、--format。
🐳nerdctl pull:拉取镜像
➜ ~ docker.io/library/busybox:latest:
resolved |++++++++++++++++++++++++++++++++++++++|
index-sha256:0f354ec1728d9ff32edcd7d1b8bbdfc798277ad36120dc3dc683be44524c8b60: done |++++++++++++++++++++++++++++++++++++++| manifest-sha256:dca71257cd2e72840a21f0323234bb2e33fea6d949fa0f21c5102146f583486b: done |++++++++++++++++++++++++++++++++++++++| config-sha256:69593048aa3acfee0f75f20b77acb549de2472063053f6730c4091b53f2dfb02: done |++++++++++++++++++++++++++++++++++++++| layer-sha256:b71f96345d44b237decc0c2d6c2f9ad0d17fde83dad7579608f1f0764d9686f2: done |++++++++++++++++++++++++++++++++++++++| elapsed: 5.9 s total: 752.8 (127.5 KiB/s)🐳nerdctl push:推送镜像
当然在推送镜像之前也可以使用 nerdctl login 命令登录到镜像仓库,然后再执行 push 操作。
可以使用 nerdctl login --username xxx --password xxx 进行登录,使用 nerdctl logout 可以注销退出登录。
🐳nerdctl tag:镜像标签
使用 tag 命令可以为一个镜像创建一个别名镜像:
➜ ~ nerdctl images
REPOSITORY TAG IMAGE ID CREATED SIZE
busybox latest 0f354ec1728d 6 minutes ago 1.3 MiB
nginx alpine bead42240255 41 minutes ago 16.0 KiB
➜ ~ nerdctl tag nginx:alpine harbor.k8s.local/course/nginx:alpine
➜ ~ nerdctl images
REPOSITORY TAG IMAGE ID CREATED SIZE
busybox latest 0f354ec1728d 7 minutes ago 1.3 MiB
nginx alpine bead42240255 41 minutes ago 16.0 KiB
harbor.k8s.local/course/nginx alpine bead42240255 2 seconds ago 16.0 KiB🐳nerdctl save:导出镜像
使用 save 命令可以导出镜像为一个 tar 压缩包。
➜ ~ nerdctl save -o busybox.tar.gz busybox:latest
➜ ~ ls -lh busybox.tar.gz
-rw-r--r-- 1 root root 761K Aug 19 15:19 busybox.tar.gz🐳nerdctl rmi:删除镜像
➜ ~ nerdctl rmi busybox
Untagged: docker.io/library/busybox:latest@sha256:0f354ec1728d9ff32edcd7d1b8bbdfc798277ad36120dc3dc683be44524c8b60
Deleted: sha256:5b8c72934dfc08c7d2bd707e93197550f06c0751023dabb3a045b723c5e7b373🐳nerdctl load:导入镜像
使用 load 命令可以将上面导出的镜像再次导入:
➜ ~ nerdctl load -i busybox.tar.gz
unpacking docker.io/library/busybox:latest (sha256:0f354ec1728d9ff32edcd7d1b8bbdfc798277ad36120dc3dc683be44524c8b60)...done使用 -i 或 --input 选项指定需要导入的压缩包。
镜像构建
镜像构建是平时我们非常重要的一个需求,我们知道 ctr 并没有构建镜像的命令,而现在我们又不使用 Docker 了,那么如何进行镜像构建了,幸运的是 nerdctl 就提供了 nerdctl build 这样的镜像构建命令。
🐳nerdctl build:从 Dockerfile 构建镜像
比如现在我们定制一个 nginx 镜像,新建一个如下所示的 Dockerfile 文件:
FROM nginx
RUN echo 'Hello Nerdctl From Containerd' > /usr/share/nginx/html/index.html然后在文件所在目录执行镜像构建命令:
➜ ~ nerdctl build -t nginx:nerdctl -f Dockerfile .
FATA[0000] `buildctl` needs to be installed and `buildkitd` needs to be running, see https://github.com/moby/buildkit: exec: "buildctl": executable file not found in $PATH可以看到有一个错误提示,需要我们安装 buildctl 并运行 buildkitd,这是因为 nerdctl build 需要依赖 buildkit 工具。
buildkit 项目也是 Docker 公司开源的一个构建工具包,支持 OCI 标准的镜像构建。它主要包含以下部分:
- 服务端
buildkitd:当前支持 runc 和 containerd 作为 worker,默认是 runc,我们这里使用 containerd - 客户端
buildctl:负责解析 Dockerfile,并向服务端 buildkitd 发出构建请求
buildkit 是典型的 C/S 架构,客户端和服务端是可以不在一台服务器上,而 nerdctl 在构建镜像的时候也作为 buildkitd 的客户端,所以需要我们安装并运行 buildkitd。
所以接下来我们先来安装 buildkit:
➜ ~ wget https://github.com/moby/buildkit/releases/download/v0.9.1/buildkit-v0.9.1.linux-amd64.tar.gz
# 如果有限制,也可以替换成下面的 URL 加速下载
# wget https://download.fastgit.org/moby/buildkit/releases/download/v0.9.1/buildkit-v0.9.1.linux-amd64.tar.gz
➜ ~ tar -zxvf buildkit-v0.9.1.linux-amd64.tar.gz -C /usr/local/containerd/
bin/
bin/buildctl
bin/buildkit-qemu-aarch64
bin/buildkit-qemu-arm
bin/buildkit-qemu-i386
bin/buildkit-qemu-mips64
bin/buildkit-qemu-mips64el
bin/buildkit-qemu-ppc64le
bin/buildkit-qemu-riscv64
bin/buildkit-qemu-s390x
bin/buildkit-runc
bin/buildkitd
➜ ~ ln -s /usr/local/containerd/bin/buildkitd /usr/local/bin/buildkitd
➜ ~ ln -s /usr/local/containerd/bin/buildctl /usr/local/bin/buildctl这里我们使用 Systemd 来管理 buildkitd,创建如下所示的 systemd unit 文件:
➜ ~ cat /etc/systemd/system/buildkit.service
[Unit]
Description=BuildKit
Documentation=https://github.com/moby/buildkit
[Service]
ExecStart=/usr/local/bin/buildkitd --oci-worker=false --containerd-worker=true
[Install]
WantedBy=multi-user.target然后启动 buildkitd:
➜ ~ systemctl daemon-reload
➜ ~ systemctl enable buildkit --now
Created symlink /etc/systemd/system/multi-user.target.wants/buildkit.service → /etc/systemd/system/buildkit.service.
➜ ~ systemctl status buildkit
● buildkit.service - BuildKit
Loaded: loaded (/etc/systemd/system/buildkit.service; enabled; vendor preset: enabled)
Memory: 8.6M
CGroup: /system.slice/buildkit.service
└─5779 /usr/local/bin/buildkitd --oci-worker=false --containerd-worker=true
Aug 19 16:03:10 ydzsio systemd[1]: Started BuildKit.
Aug 19 16:03:10 ydzsio buildkitd[5779]: time="2021-08-19T16:03:10+08:00" level=warning msg="using host network as the default"
Aug 19 16:03:10 ydzsio buildkitd[5779]: time="2021-08-19T16:03:10+08:00" level=info msg="found worker \"euznuelxhxb689bc5of7pxmbc\", labels>
Aug 19 16:03:10 ydzsio buildkitd[5779]: time="2021-08-19T16:03:10+08:00" level=info msg="found 1 workers, default=\"euznuelxhxb689bc5of7pxm>
Aug 19 16:03:10 ydzsio buildkitd[5779]: time="2021-08-19T16:03:10+08:00" level=warning msg="currently, only the default worker can be used."
Aug 19 16:03:10 ydzsio buildkitd[5779]: time="2021-08-19T16:03:10+08:00" level=info msg="running server on /run/buildkit/buildkitd.sock"
~现在我们再来重新构建镜像:
构建完成后查看镜像是否构建成功:
➜ ~ nerdctl images
WARN[0000] unparsable image name "overlayfs@sha256:d5b9b9e4c930f30340650cb373f62f97c93ee3b92c83f01c6e00b7b87d62c624"
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx latest 4d4d96ac750a 4 minutes ago 16.0 KiB
nginx nerdctl d5b9b9e4c930 About a minute ago 24.0 KiB我们可以看到已经有我们构建的 nginx:nerdctl 镜像了。接下来使用上面我们构建的镜像来启动一个容器进行测试:
➜ ~ nerdctl run -d -p 80:80 --name=nginx --restart=always nginx:nerdctl
f8f639cb667926023231b13584226b2c7b856847e0a25bd5f686b9a6e7e3cacd
➜ ~ nerdctl ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f8f639cb6679 docker.io/library/nginx:nerdctl "/docker-entrypoint.…" 1 second ago Up 0.0.0.0:80->80/tcp nginx
➜ ~ curl localhost
This is a nerdctl build's nginx image base on containerd这样我们就使用 nerdctl + buildkitd 轻松完成了容器镜像的构建。
当然如果你还想在单机环境下使用 Docker Compose,在 containerd 模式下,我们也可以使用 nerdctl 来兼容该功能。同样我们可以使用 nerdctl compose、nerdctl compose up、nerdctl compose logs、nerdctl compose build、nerdctl compose down 等命令来管理 Compose 服务。这样使用 containerd、nerdctl 结合 buildkit 等工具就完全可以替代 docker 在镜像构建、镜像容器方面的管理功能了。
CGroups 与 Namespaces
本节我们来一起了解下容器背后的两个核心技术:CGroups 和 Namespace。
CGroups 概述
CGroups 全称为 Linux Control Group,其作用是限制一组进程使用的资源(CPU、内存等)上限,CGroups 也是 Containerd 容器技术的核心实现原理之一,首先我们需要先了解几个 CGroups 的基本概念:
- Task: 在 cgroup 中,task 可以理解为一个进程,但这里的进程和一般意义上的操作系统进程不太一样,实际上是进程 ID 和线程 ID 列表。
- CGroup: 即控制组,一个控制组就是一组按照某种标准划分的 Tasks,可以理解为资源限制是以进程组为单位实现的,一个进程加入到某个控制组后,就会受到相应配置的资源限制。
- Hierarchy: cgroup 的层级组织关系,cgroup 以树形层级组织,每个 cgroup 子节点默认继承其父 cgroup 节点的配置属性,这样每个 Hierarchy 在初始化会有 root cgroup。
- Subsystem: 即子系统,子系统表示具体的资源配置,如 CPU 使用,内存占用等,Subsystem 附加到 Hierarchy 上后可用。
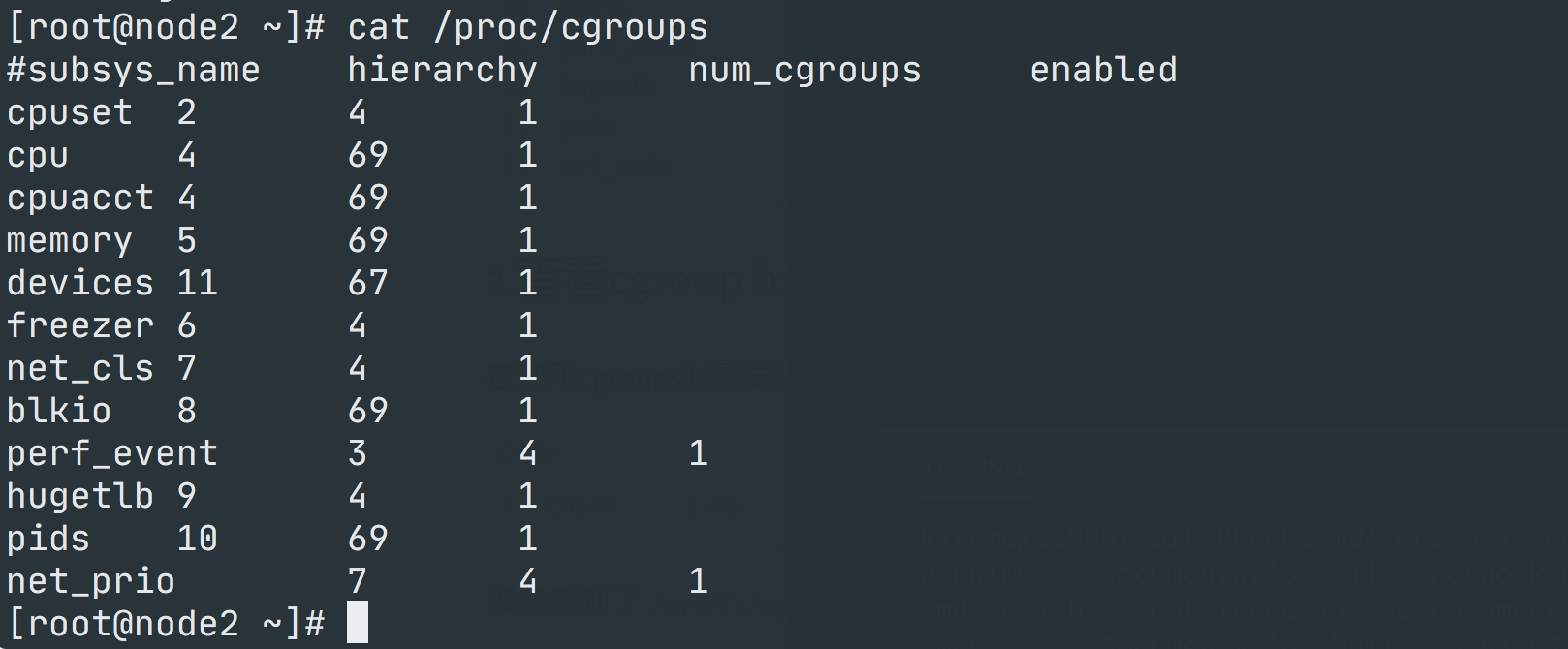
CGroups 支持的子系统包含以下几类,即为每种可以控制的资源定义了一个子系统:
cpuset: 为 cgroup 中的进程分配单独的 CPU 节点,即可以绑定到特定的 CPUcpu: 限制 cgroup 中进程的 CPU 使用份额cpuacct: 统计 cgroup 中进程的 CPU 使用情况memory: 限制 cgroup 中进程的内存使用,并能报告内存使用情况devices: 控制 cgroup 中进程能访问哪些文件设备(设备文件的创建、读写)freezer: 挂起或恢复 cgroup 中的 tasknet_cls: 可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic contro)对数据包进行控制blkio: 限制 cgroup 中进程的块设备 IOperf_event: 监控 cgroup 中进程的 perf 时间,可用于性能调优hugetlb: hugetlb 的资源控制功能pids: 限制 cgroup 中可以创建的进程数net_prio: 允许管理员动态的通过各种应用程序设置网络传输的优先级
通过上面的各个子系统,可以看出使用 CGroups 可以控制的资源有: CPU、内存、网络、IO、文件设备等。CGroups 具有以下几个特点:
- CGroups 的 API 以一个伪文件系统(/sys/fs/cgroup/)的实现方式,用户的程序可以通过文件系统实现 CGroups 的组件管理
- CGroups 的组件管理操作单元可以细粒度到线程级别,用户可以创建和销毁 CGroups,从而实现资源载分配和再利用
- 所有资源管理的功能都以子系统(cpu、cpuset 这些)的方式实现,接口统一子任务创建之初与其父任务处于同一个 CGroups 的控制组
我们可以通过查看 /proc/cgroups 文件来查找当前系统支持的 CGroups 子系统:
在使用 CGroups 时需要先挂载,我们可以使用 df -h | grep cgroup 命令进行查看:
➜ ~ df -h | grep cgroup
tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup可以看到被挂载到了 /sys/fs/cgroup,cgroup 其实是一种文件系统类型,所有的操作都是通过文件来完成的,我们可以使用 mount --type cgroup命令查看当前系统挂载了哪些 cgroup:
➜ ~ mount --type cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)/sys/fs/cgroup 目录下的每个子目录就对应着一个子系统,cgroup 是以目录形式组织的,/ 是 cgroup 的根目录,但是这个根目录可以被挂载到任意目录,例如 CGroups 的 memory 子系统的挂载点是 /sys/fs/cgroup/memory,那么 /sys/fs/cgroup/memory/ 对应 memory 子系统的根目录,我们可以列出该目录下面的文件:
➜ ~ ll /sys/fs/cgroup/memory/
total 0
-rw-r--r-- 1 root root 0 Oct 21 10:10 cgroup.clone_children
--w--w--w- 1 root root 0 Oct 21 10:10 cgroup.event_control
-rw-r--r-- 1 root root 0 Oct 21 10:10 cgroup.procs
-r--r--r-- 1 root root 0 Oct 21 10:10 cgroup.sane_behavior
drwxr-xr-x 4 root root 0 Oct 21 10:10 kubepods.slice
-rw-r--r-- 1 root root 0 Oct 21 10:10 memory.failcnt
--w------- 1 root root 0 Oct 21 10:10 memory.force_empty
-rw-r--r-- 1 root root 0 Oct 21 10:10 memory.kmem.failcnt
-rw-r--r-- 1 root root 0 Oct 21 10:10 memory.kmem.limit_in_bytes
-rw-r--r-- 1 root root 0 Oct 21 10:10 memory.kmem.max_usage_in_bytes
-r--r--r-- 1 root root 0 Oct 21 10:10 memory.kmem.slabinfo
-rw-r--r-- 1 root root 0 Oct 21 10:10 memory.kmem.tcp.failcnt
-rw-r--r-- 1 root root 0 Oct 21 10:10 memory.kmem.tcp.limit_in_bytes
-rw-r--r-- 1 root root 0 Oct 21 10:10 memory.kmem.tcp.max_usage_in_bytes
-r--r--r-- 1 root root 0 Oct 21 10:10 memory.kmem.tcp.usage_in_bytes
-r--r--r-- 1 root root 0 Oct 21 10:10 memory.kmem.usage_in_bytes
-rw-r--r-- 1 root root 0 Oct 21 10:10 memory.limit_in_bytes
-rw-r--r-- 1 root root 0 Oct 21 10:10 memory.max_usage_in_bytes
-rw-r--r-- 1 root root 0 Oct 21 10:10 memory.memsw.failcnt
-rw-r--r-- 1 root root 0 Oct 21 10:10 memory.memsw.limit_in_bytes
-rw-r--r-- 1 root root 0 Oct 21 10:10 memory.memsw.max_usage_in_bytes
-r--r--r-- 1 root root 0 Oct 21 10:10 memory.memsw.usage_in_bytes
-rw-r--r-- 1 root root 0 Oct 21 10:10 memory.move_charge_at_immigrate
-r--r--r-- 1 root root 0 Oct 21 10:10 memory.numa_stat
-rw-r--r-- 1 root root 0 Oct 21 10:10 memory.oom_control
---------- 1 root root 0 Oct 21 10:10 memory.pressure_level
-rw-r--r-- 1 root root 0 Oct 21 10:10 memory.soft_limit_in_bytes
-r--r--r-- 1 root root 0 Oct 21 10:10 memory.stat
-rw-r--r-- 1 root root 0 Oct 21 10:10 memory.swappiness
-r--r--r-- 1 root root 0 Oct 21 10:10 memory.usage_in_bytes
-rw-r--r-- 1 root root 0 Oct 21 10:10 memory.use_hierarchy
-rw-r--r-- 1 root root 0 Oct 21 10:10 notify_on_release
-rw-r--r-- 1 root root 0 Oct 21 10:10 release_agent
drwxr-xr-x 65 root root 0 Oct 21 10:25 system.slice
-rw-r--r-- 1 root root 0 Oct 21 10:10 tasks
drwxr-xr-x 2 root root 0 Oct 21 10:10 user.slice上面包含 kubepods.slice、system.slice、user.slice 等目录,这些目录下可能还会有子目录,相当于一颗有层级关系的树来进行组织:
/
├── kubepods.slice
├── system.slice
└── user.slice例如我在节点上使用 systemd 管理了一个 Prometheus 的应用,我们可以使用 systemctl status prometheus 命令查看 Prometheus 进程所在的 cgroup 为 /system.slice/prometheus.service:
➜ ~ systemctl status prometheus
● prometheus.service - prometheus service
Loaded: loaded (/etc/systemd/system/prometheus.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2021-10-21 10:10:12 CST; 1h 40min ago
Docs: https://prometheus.io
Main PID: 1065 (prometheus)
Tasks: 10
Memory: 167.4M
CGroup: /system.slice/prometheus.service
└─1065 /root/p8strain/prometheus-2.30.2.linux-amd64/prometheus --config.file=/root/p8strain/prometheu...上面显示的 CGroup 只是一个相对的路径,实际的文件系统目录是在对应的子系统下面,比如 /sys/fs/cgroup/cpu/system.slice/prometheus.service、/sys/fs/cgroup/memory/system.slice/prometheus.service 目录:
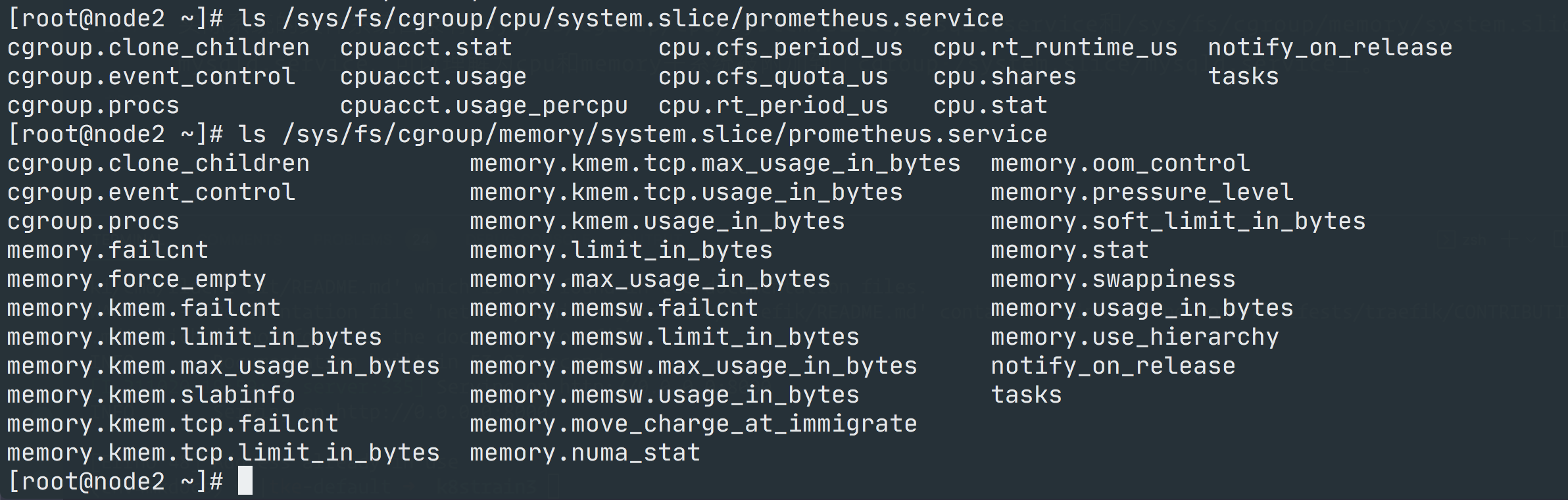
这其实可以理解为 cpu 和 memory 子系统被附加到了 /system.slice/prometheus.service 这个 cgroup 上。
如果 linux 系统使用 systemd 初始化系统,初始化进程会生成一个 root cgroup,每个
systemd unit都将会被分配一个 cgroup,同样可以配置容器运行时如 containerd 选择使用 cgroupfs 或 systemd 作为 cgroup 驱动,containerd 默认使用的是 cgroupfs,但对于使用了 systemd 的 linux 发行版来说就同时存在两个 cgroup 管理器,对于该服务器上启动的容器使用的是 cgroupfs,而对于其他 systemd 管理的进程使用的是 systemd,这样在服务器资源负载高的情况下可能会变的不稳定。因此对于使用了 systemd 的 linux 系统,推荐将容器运行时的 cgroup 驱动使用 systemd。
CGroup 测试
接下来我们来尝试手动设置下 cgroup,以 CPU 这个子系统为例进行说明,首先我们在 /sys/fs/cgroup/cpu 目录下面创建一个名为 ydzs.test 的目录:
➜ ~ mkdir -p /sys/fs/cgroup/cpu/ydzs.test
➜ ~ ls /sys/fs/cgroup/cpu/ydzs.test/
cgroup.clone_children cpuacct.stat cpu.cfs_period_us cpu.rt_runtime_us notify_on_release
cgroup.event_control cpuacct.usage cpu.cfs_quota_us cpu.shares tasks
cgroup.procs cpuacct.usage_percpu cpu.rt_period_us cpu.stat我们可以看到目录创建完成后,下面就会已经自动创建 cgroup 的相关文件,这里我们重点关注 cpu.cfs_period_us 和 cpu.cfs_quota_us 这两个文件,前面一个是用来配置 CPU 时间周期长度的,默认为 100000us,后者用来设置在此时间周期长度内所能使用的 CPU 时间数,默认值为-1,表示不受时间限制。
➜ ~ cat /sys/fs/cgroup/cpu/ydzs.test/cpu.cfs_period_us
100000
➜ ~ cat /sys/fs/cgroup/cpu/ydzs.test/cpu.cfs_quota_us
-1现在我们写一个简单的 Python 脚本来消耗 CPU:
# cgroup.py
while True:
pass直接执行这个死循环脚本即可:
➜ ~ python cgroup.py &
[1] 2113使用 top 命令可以看到进程号 2113 的 CPU 使用率达到了 100%
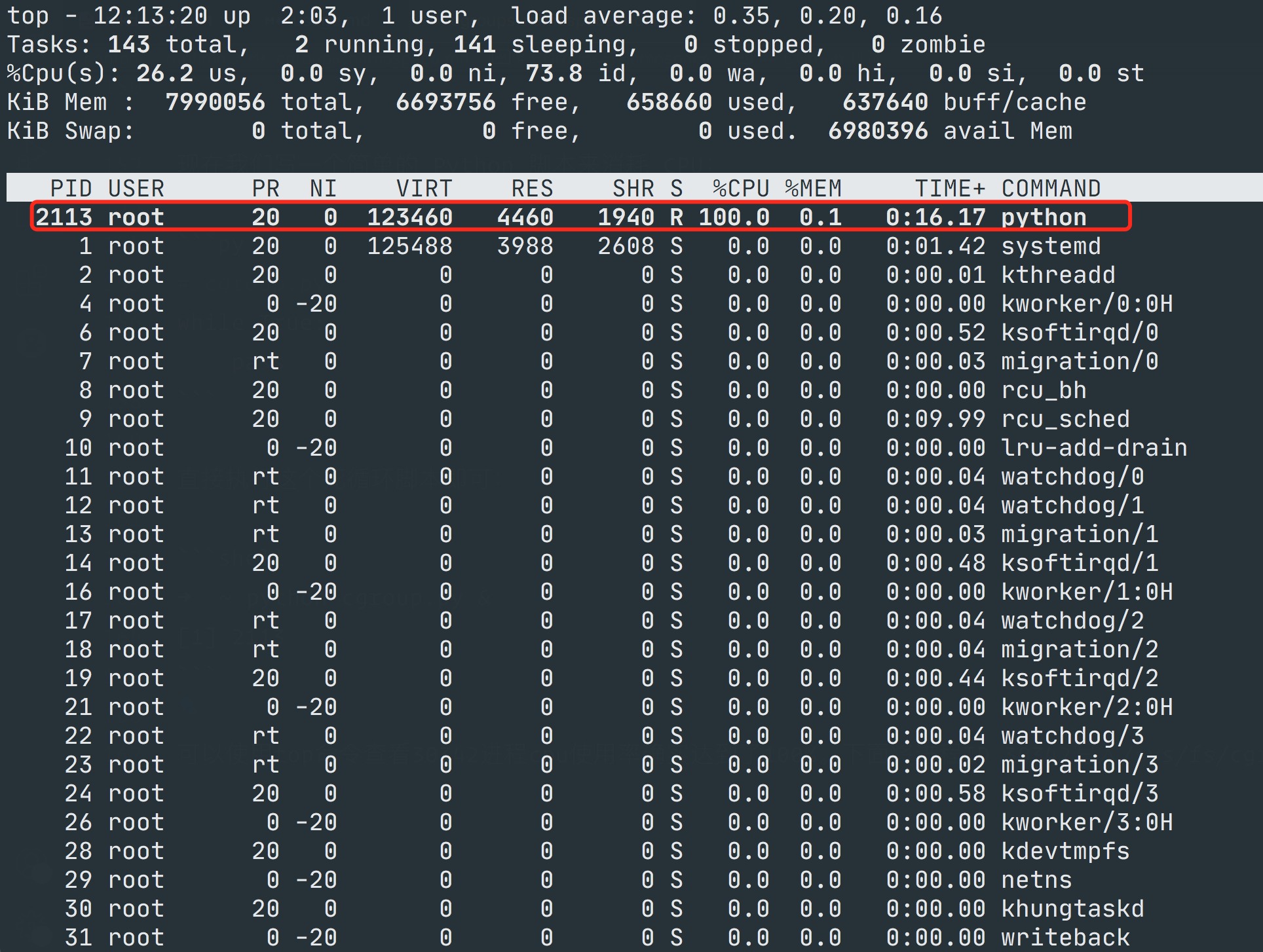
现在我们将这个进程 ID 写入到 /sys/fs/cgroup/cpu/ydzs.test/tasks 文件下面去,然后设置 /sys/fs/cgroup/cpu/ydzs.test/cpu.cfs_quota_us 为 10000us,因为 cpu.cfs_period_us 默认值为 100000us,所以这表示我们要限制 CPU 使用率为 10%:
➜ ~ echo 2113 > /sys/fs/cgroup/cpu/ydzs.test/tasks
➜ ~ echo 10000 > /sys/fs/cgroup/cpu/ydzs.test/cpu.cfs_quota_us设置完过后上面我们的测试进程 CPU 就会被限制在 10% 左右了,再次使用 top 命令查看该进程可以验证。
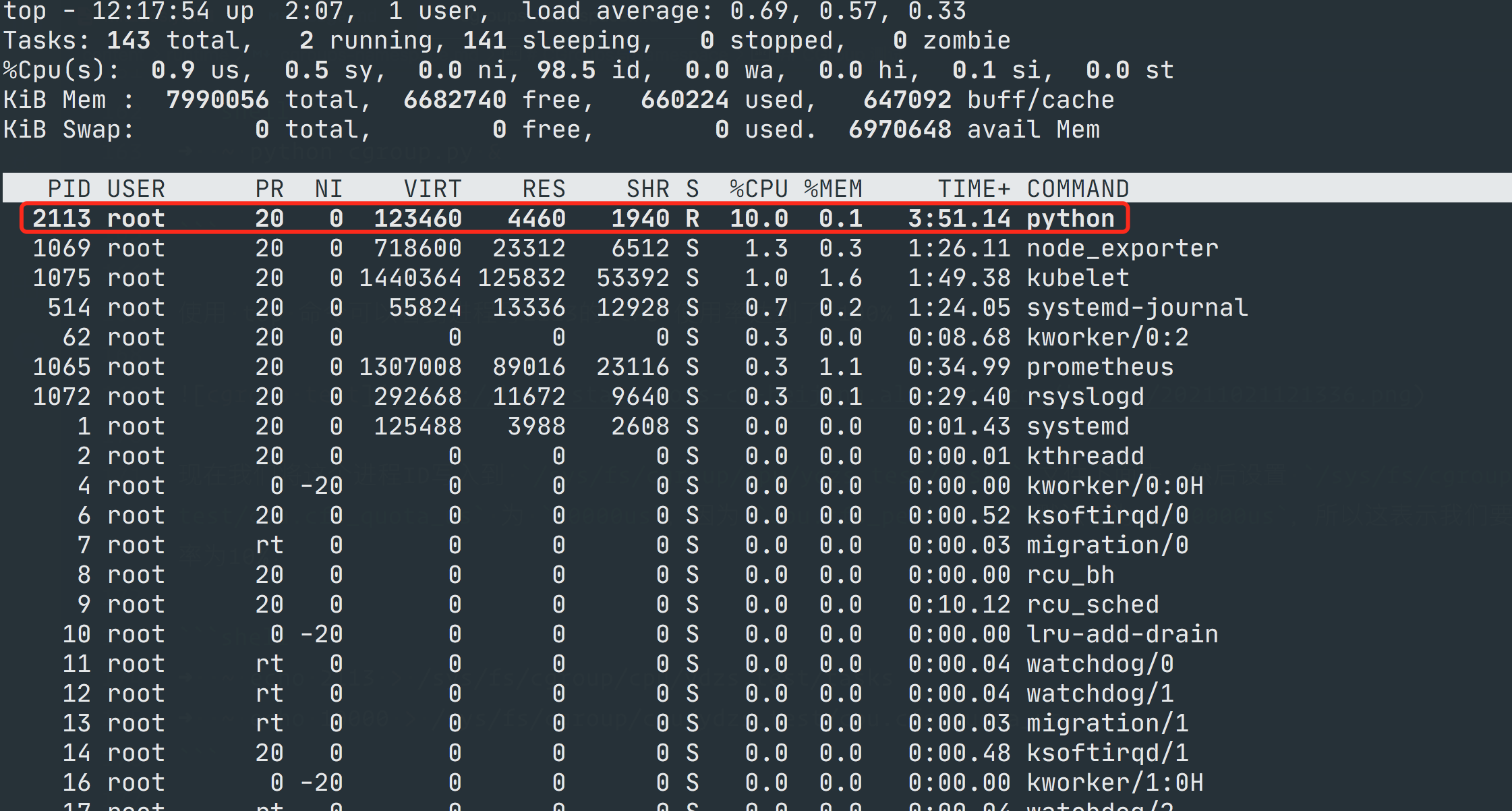
如果要限制内存等其他资源的话,同样去对应的子系统下面设置资源,并将进程 ID 加入 tasks 中即可。如果要删除这个 cgroup,直接删除文件夹是不行的,需要使用 libcgroup 工具:
➜ ~ yum install libcgroup libcgroup-tools
➜ ~ cgdelete cpu:ydzs.test
➜ ~ ls /sys/fs/cgroup/cpu/ydzs.test
ls: cannot access /sys/fs/cgroup/cpu/ydzs.test: No such file or directory在容器中使用 CGroups
上面我们测试了一个普通应用如何配置 cgroup,接下来我们在 Containerd 的容器中来使用 cgroup,比如使用 nerdctl 启动一个 nginx 容器,并限制其使用内存为 50M:
➜ ~ nerdctl run -d -m 50m --name nginx nginx:alpine
8690c7dba4ffe03d63983555c594e2784c146b5f9939de1195a9626339c9129c
➜ ~ nerdctl ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8690c7dba4ff docker.io/library/nginx:alpine "/docker-entrypoint.…" 53 seconds ago Up nginx在使用 nerdctl run 启动容器的时候可以使用 -m 或 --memory 参数来现在内存,启动完成后该容器的 cgroup 会出现在 名为 default 的目录下面,比如查看内存子系统的目录:
➜ ~ ll /sys/fs/cgroup/memory/default/
total 0
drwxr-xr-x 2 root root 0 Oct 21 15:01 8690c7dba4ffe03d63983555c594e2784c146b5f9939de1195a9626339c9129c
-rw-r--r-- 1 root root 0 Oct 21 15:01 cgroup.clone_children
--w--w--w- 1 root root 0 Oct 21 15:01 cgroup.event_control
-rw-r--r-- 1 root root 0 Oct 21 15:01 cgroup.procs
......上面我们启动的 nginx 容器 ID 的目录会出现在 /sys/fs/cgroup/memory/default/ 下面,该文件夹下面有很多和内存相关的 cgroup 配置文件,要进行相关的配置就需要在该目录下对应的文件中去操作:
➜ ~ ll /sys/fs/cgroup/memory/default/8690c7dba4ffe03d63983555c594e2784c146b5f9939de1195a9626339c9129c
total 0
-rw-r--r-- 1 root root 0 Oct 21 15:01 cgroup.clone_children
--w--w--w- 1 root root 0 Oct 21 15:01 cgroup.event_control
-rw-r--r-- 1 root root 0 Oct 21 15:01 cgroup.procs
-rw-r--r-- 1 root root 0 Oct 21 15:01 memory.failcnt
--w------- 1 root root 0 Oct 21 15:01 memory.force_empty
-rw-r--r-- 1 root root 0 Oct 21 15:01 memory.kmem.failcnt
-rw-r--r-- 1 root root 0 Oct 21 15:01 memory.kmem.limit_in_bytes
-rw-r--r-- 1 root root 0 Oct 21 15:01 memory.kmem.max_usage_in_bytes
-r--r--r-- 1 root root 0 Oct 21 15:01 memory.kmem.slabinfo
-rw-r--r-- 1 root root 0 Oct 21 15:01 memory.kmem.tcp.failcnt
-rw-r--r-- 1 root root 0 Oct 21 15:01 memory.kmem.tcp.limit_in_bytes
-rw-r--r-- 1 root root 0 Oct 21 15:01 memory.kmem.tcp.max_usage_in_bytes
-r--r--r-- 1 root root 0 Oct 21 15:01 memory.kmem.tcp.usage_in_bytes
-r--r--r-- 1 root root 0 Oct 21 15:01 memory.kmem.usage_in_bytes
-rw-r--r-- 1 root root 0 Oct 21 15:01 memory.limit_in_bytes
-rw-r--r-- 1 root root 0 Oct 21 15:01 memory.max_usage_in_bytes
-rw-r--r-- 1 root root 0 Oct 21 15:01 memory.memsw.failcnt
-rw-r--r-- 1 root root 0 Oct 21 15:01 memory.memsw.limit_in_bytes
-rw-r--r-- 1 root root 0 Oct 21 15:01 memory.memsw.max_usage_in_bytes
-r--r--r-- 1 root root 0 Oct 21 15:01 memory.memsw.usage_in_bytes
-rw-r--r-- 1 root root 0 Oct 21 15:01 memory.move_charge_at_immigrate
-r--r--r-- 1 root root 0 Oct 21 15:01 memory.numa_stat
-rw-r--r-- 1 root root 0 Oct 21 15:01 memory.oom_control
---------- 1 root root 0 Oct 21 15:01 memory.pressure_level
-rw-r--r-- 1 root root 0 Oct 21 15:01 memory.soft_limit_in_bytes
-r--r--r-- 1 root root 0 Oct 21 15:01 memory.stat
-rw-r--r-- 1 root root 0 Oct 21 15:01 memory.swappiness
-r--r--r-- 1 root root 0 Oct 21 15:01 memory.usage_in_bytes
-rw-r--r-- 1 root root 0 Oct 21 15:01 memory.use_hierarchy
-rw-r--r-- 1 root root 0 Oct 21 15:01 notify_on_release
-rw-r--r-- 1 root root 0 Oct 21 15:01 tasks我们这里需要关心的是 memory.limit_in_bytes 文件,该文件就是用来设置内存大小的,正常应该是 50M 的内存限制:
➜ ~ cat /sys/fs/cgroup/memory/default/8690c7dba4ffe03d63983555c594e2784c146b5f9939de1195a9626339c9129c/memory.limit_in_bytes
52428800同样我们的 nginx 容器进程 ID 也会出现在上面的 tasks 文件中:
➜ ~ cat /sys/fs/cgroup/memory/default/8690c7dba4ffe03d63983555c594e2784c146b5f9939de1195a9626339c9129c/tasks
2686
2815
2816
2817
2818我们可以通过如下命令过滤该进程号,可以看出第一行的 2686 就是 nginx 进程在主机上的进程 ID,下面几个是这个进程下的线程:
➜ ~ ps -ef | grep 2686
root 2686 2656 0 15:01 ? 00:00:00 nginx: master process nginx -g daemon off;
101 2815 2686 0 15:01 ? 00:00:00 nginx: worker process
101 2816 2686 0 15:01 ? 00:00:00 nginx: worker process
101 2817 2686 0 15:01 ? 00:00:00 nginx: worker process
101 2818 2686 0 15:01 ? 00:00:00 nginx: worker process
root 2950 1976 0 15:36 pts/0 00:00:00 grep --color=auto 2686我们删除这个容器后,/sys/fs/cgroup/memory/default/ 目录下的容器 ID 文件夹也会自动删除。
Namespaces
namespace 也称命名空间,是 Linux 为我们提供的用于隔离进程树、网络接口、挂载点以及进程间通信等资源的方法。在日常使用个人 PC 时,我们并没有运行多个完全分离的服务器的需求,但是如果我们在服务器上启动了多个服务,这些服务其实会相互影响的,每一个服务都能看到其他服务的进程,也可以访问宿主机器上的任意文件,一旦服务器上的某一个服务被入侵,那么入侵者就能够访问当前机器上的所有服务和文件,这是我们不愿意看到的,我们更希望运行在同一台机器上的不同服务能做到完全隔离,就像运行在多台不同的机器上一样。而我们这里的容器其实就通过 Linux 的 Namespaces 技术来实现的对不同的容器进行隔离。
linux 共有 6(7)种命名空间:
ipc namespace: 管理对 IPC 资源(进程间通信(信号量、消息队列和共享内存)的访问net namespace: 网络设备、网络栈、端口等隔离mnt namespace: 文件系统挂载点隔离pid namespace: 用于进程隔离user namespace: 用户和用户组隔离(3.8 以后的内核才支持)uts namespace: 主机和域名隔离cgroup namespace:用于 cgroup 根目录隔离(4.6 以后版本的内核才支持)
我们可以通过 lsns 命令查看当前系统已经创建的命名空间:
➜ ~ lsns
NS TYPE NPROCS PID USER COMMAND
4026531836 pid 143 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026531837 user 143 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026531838 uts 143 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026531839 ipc 143 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026531840 mnt 138 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026531856 mnt 1 28 root kdevtmpfs
4026531956 net 143 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026532503 mnt 2 728 root /usr/sbin/NetworkManager --no-daemon
4026532504 mnt 1 745 chrony /usr/sbin/chronyd
4026532642 mnt 1 1076 grafana /usr/sbin/grafana-server --config=/etc/grafana/grafana.ini --pidfile=/var/run要查看一个进程所属的命名空间信息,可以到 /proc/<pid>/ns 目录下查看:
➜ ~ ps -ef | grep prometheus
root 1065 1 0 10:10 ? 00:01:13 /root/p8strain/prometheus-2.30.2.linux-amd64/prometheus --config.file=/root/p8strain/prometheus-2.30.2.linux-amd64/prometheus.yml
➜ ~ ll /proc/1065/ns
total 0
lrwxrwxrwx 1 root root 0 Oct 21 15:58 ipc -> ipc:[4026531839]
lrwxrwxrwx 1 root root 0 Oct 21 15:58 mnt -> mnt:[4026531840]
lrwxrwxrwx 1 root root 0 Oct 21 15:58 net -> net:[4026531956]
lrwxrwxrwx 1 root root 0 Oct 21 15:58 pid -> pid:[4026531836]
lrwxrwxrwx 1 root root 0 Oct 21 15:58 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Oct 21 15:58 uts -> uts:[4026531838]这些 namespace 都是链接文件, 格式为 namespaceType:[inode number],inode number 用来标识一个 namespace,可以理解为 namespace id,如果两个进程的某个命名空间的链接文件指向同一个,那么其相关资源在同一个命名空间中,也就没有隔离了。比如同样针对上面运行的 nginx 容器,我们查看其命名空间:
➜ ~ lsns |grep nginx
4026532505 mnt 5 3171 root nginx: master process nginx -g daemon off
4026532506 uts 5 3171 root nginx: master process nginx -g daemon off
4026532507 ipc 5 3171 root nginx: master process nginx -g daemon off
4026532508 pid 5 3171 root nginx: master process nginx -g daemon off
4026532510 net 5 3171 root nginx: master process nginx -g daemon off可以看出 nginx 容器启动后,已经为该容器自动创建了单独的 mtn、uts、ipc、pid、net 命名空间,也就是这个容器在这些方面是独立隔离的,其他容器想要和该容器共享某一个命名空间,那么就需要指向同一个命名空间。