Buffer的原理和使用场景+面试题解读
Buffer的原理和使用场景+面试题解读
缓冲区(Buffer)一直是一个面试热点,Buffer和流经常一起考。我先请大家思考一个问题。缓冲区是不是流? 当然不是,流代表的是随着时间到来的数据。缓冲区,顾名思义,肯定是用来做缓冲的。为什么要做缓冲?那是因为数据到来太快处理不过来。
比如键盘缓冲区,按键太快,处理不过来,把按键先存下来。比如磁盘缓冲区,磁盘写入太多,一次写入不完,先把要写入的数据缓冲下来。比如说网络缓冲区,网卡到来的数据太多。先把这些数据存下来。之后再处理。……
比如说理发店的缓冲区,其实就是理发店的等待坐席;饭店的缓冲区,就是饭店的排号。缓冲的本质是排队,流的本质是数据,是两个风马牛不相及的两个概念。
缓冲区这部分一共3堂课:
- 本节帮助你弄懂缓冲区的一切
- 下一节:同步、异步、阻塞、非阻塞概念区分
- 下下节:实战中文乱码处理和阿里面试题(并发处理算词频)
本节课关联的面试题目:
- 缓冲区是不是流?
- 缓冲区的几种操作含义:flip/rewind/clear?
- 缓冲区设置多大?
- NIO的Channel比缓冲区快吗?
- 缓冲过程中,中文乱码如何处理?
- 并发分析数据更快吗?
缓冲区的概念
数据在缓冲区中排队,你先入先出的形式读写。先写入的数据先被读出来。所以看上去缓冲区像一个水管,数据流入缓冲区,然后再流出。

缓冲区内部是用于存储数据的数据结构。可能是数组、可能是链表、甚至可能是复杂的树结构,比如哈希表、树等等都有可能。
你可能会问,数据进入缓冲区,然后再离开缓冲区到底有什么价值呢?数据有没有发生变化?又没有数据的监控和沉淀结果。此后什么都没有发生。那么价值是什么?

核心的价值当然是缓冲了。设想一个设备高速产生数据,而处理节点想处理这些数据。你可以思考,如果处理节点处理不完,这些数据会发生什么?比如用户按键太快,应用程序响应不过来会发生什么?我们这里有一个假设,用户不会一直按键都那么快,因为用户会累。当用户按键实在太快的时候,系统就发出一声beep,用户听到警报声就停止乱按键。这声beep就是因为缓冲区已经满了,后面用户的按键就会被拒绝。我没有缓冲区呢?如果用单线程去处理用户按键。用户只要按两个键就会被拒绝一个。如果有一个大小为1024的缓冲区,用户至少要按1025个键,才会导致处理节点处理不过来,才会触发拒绝(beep)。所以缓冲区的成本很低,但是实现的效果却很好。
因此我们在实现系统的架构时。理论上,系统的对接都应该存在缓冲。一个系统将自己的输出作为另一个系统的输入,那么在处理输入的系统内,就应该有一个专门接收数据的缓冲区的设计。
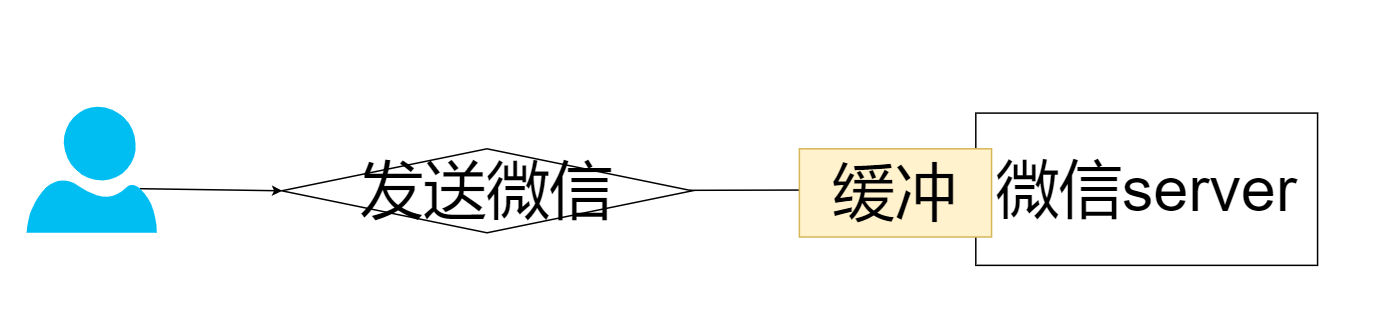
比如一个聊天服务,在处理用户发送的消息时,例如微信,一定不能马上处理这条消息。而是应该先缓冲。如果你马上处理这些消息,当并发量高的时候,总有你处理不过来的时候。而你对消息进行了缓冲有很多的好处,首先是避免了瓶颈的出现(运算性能的瓶颈。Io性能的瓶颈)。其次,有时候批量处理数据的成本更低。比如批量写入磁盘。批量发送网络请求。可以更好的利用底层的设施,比如批量写入磁盘数据就比单个一点点写入快很多很多,这些都是缓冲区的价值。
I/O的成本
在理解缓冲区的过程当中。通常我们都是结合I/O。所以你要弄清楚I/O的成本。
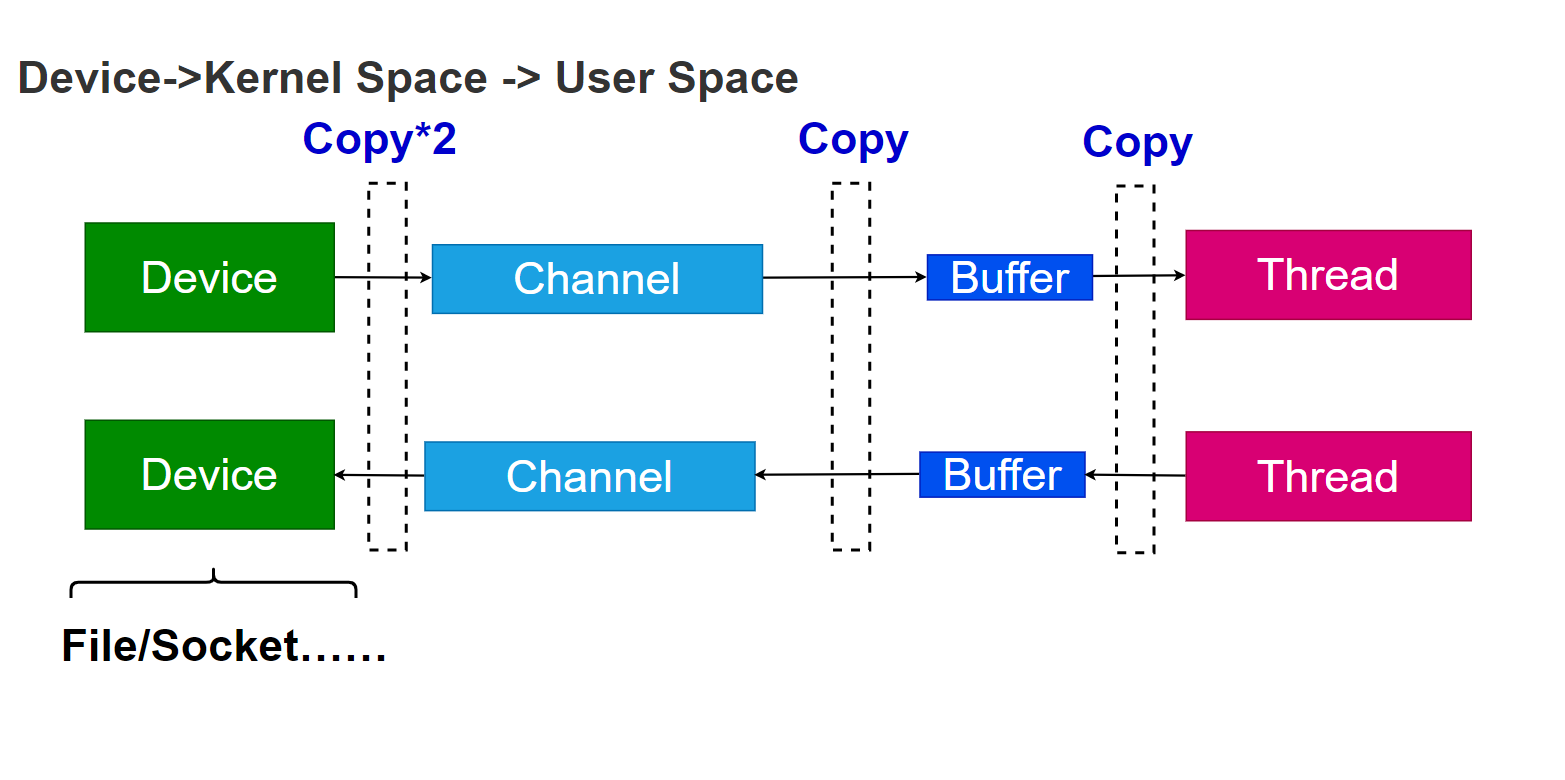
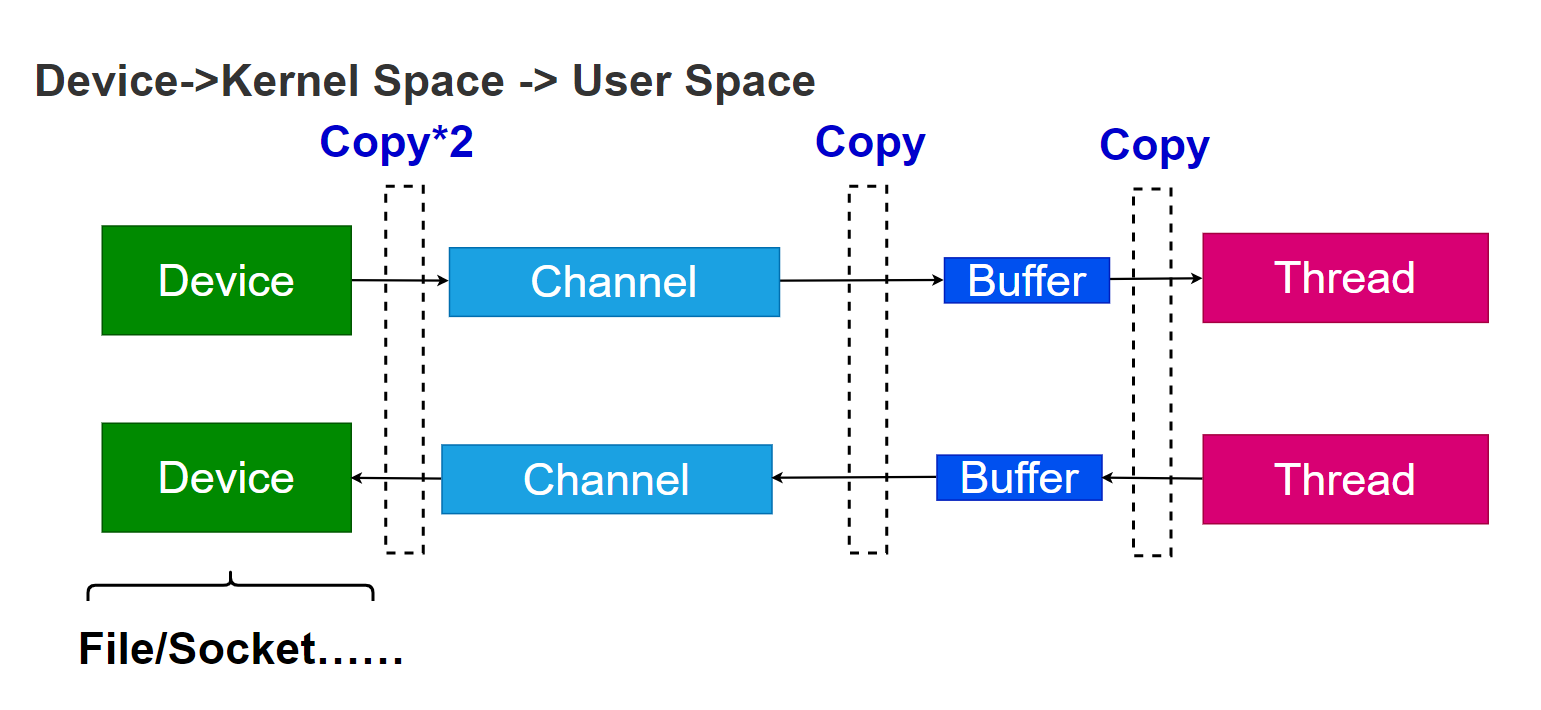
上图在演示数据从设备到处理线程中的拷贝次数。比如从网卡接收到数据,一直到处理的线程经过的拷贝次数。
当设备收到数据的时候,首先要拷贝到操作系统内核空间。内核空间。也是内存的一部分。这部分拷贝可能是基于硬件的。在主板上有一个小型的设备,叫做DMA(Direct Memory Access),这个设备可以帮助我们将数据拷贝到内存,却不消耗CPU资源。
接下来,我们需要将内核空间的数据,拷贝到用户空间。这是因为应用程序的权限是不可以访问内核空间中的数据的。
这是对内存的一种保护策略。试想,如果应用程序可以访问内核空间,那么应用程序就可以随意的修改操作系统的任何配置,这是一件极其危险的事情。
那你可能会问,那么为什么不直接将设备的数据拷贝到用户空间呢?这是因为,多个应用可能会复用设备。比如说如果有十个线程,都需要使用同一个设备的数据,那么我们将这个设备数据,拷贝到哪个用户空间呢?因为每个进程拥有的用户空间是不同的,相当于每个进程拥有的内存区域是不互相重叠。这就是为什么需要先拷贝到内核空间。
还有一个重要的原因,我们不希望设备直接沟通用户空间,这是一种安全策略,设备直接沟通用户空间也是很危险的。因为多数的设备是经单线程的设计,多线程的访问,需要驱动程序承接。
所以上面的两次拷贝:设备到内核空间,由内核空间到用户空间,是不可省略的。接下来还要进行一次拷贝,数据会先存在于缓冲区当中,需要拷贝到处理的线程。反过,我们将数据从用户空间中写回去,写到内核空间,也需要经过缓冲区。缓冲区的数据需要读出来才能用所以这又是一次拷贝。
上面的这个模型中,每次I/O数据至少会经过三次拷贝。在这三次拷贝当中,只有第一次可以利用DMA技术,是可以不需要CPU资源的。后面两次都是消耗CPU资源的。看上去很傻:一个比特,一个比特去拷贝。但是实际情况就是如此,I/O的成本非常的高。网卡接收到一G数据,需要把一G数据经过多次拷贝,拷贝到线程去处理。
这是一个最基本的理解模型,这个模型不理解,其实是理解不了I/O。同步异步,都不重要。先要理解,I/O成本到底高在哪里?这样才好进行优化,同步、异步只是编程的模型,程序写对了,性能上并无任何差异。
这部分知识。还关联了一些高并发网络请求应该如何处理?这部分我将在后面讨论Linux和网络的那一章和大家讲解。
缓冲区的实现原理
缓冲区的实现方式就多了,通常的我们会用线性结构去实现缓冲区:比如说数组、链表。
数组实现缓冲区是最常见的。因为数组和内存形式上是统一的,都是连续紧密的数据结构。
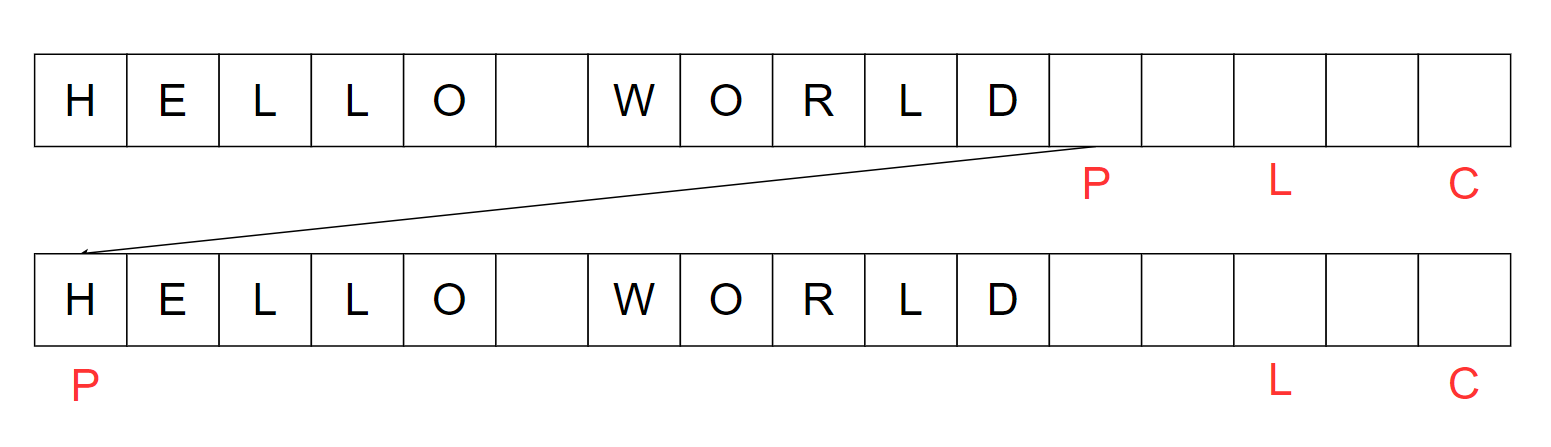
下图中是一个常见的单向缓冲区数据结构,P代表下一个写入的位置,每次写入P向右移动。
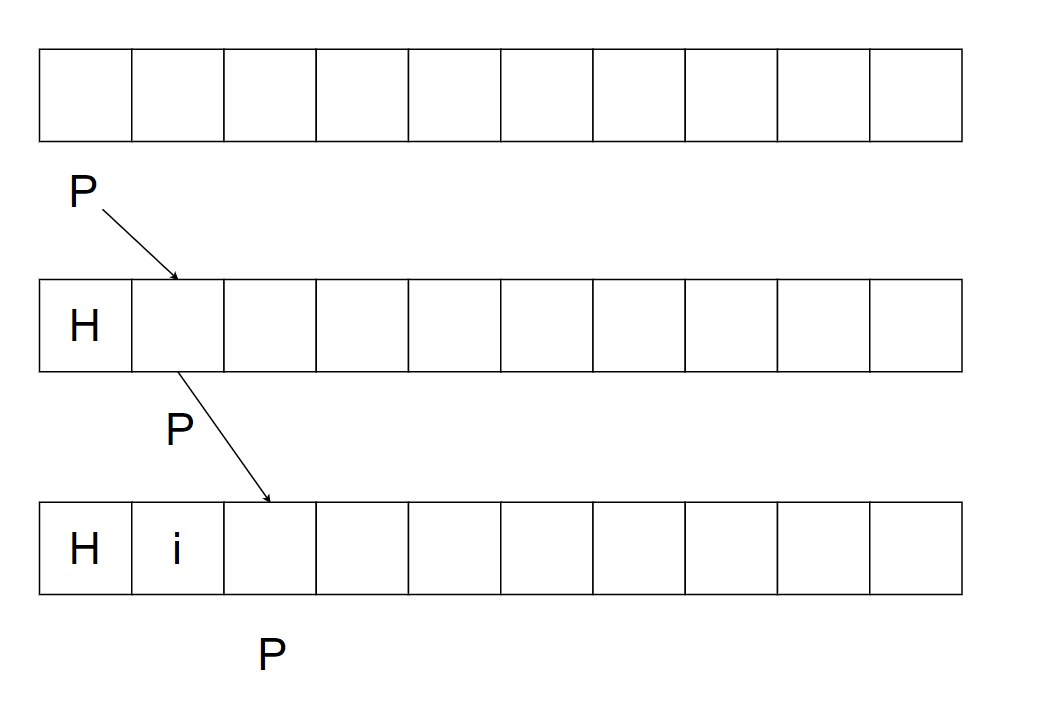
实现写入的代码类似:
put(int v) {
data[P++] = v;
}
通常的,我们用3个值来控制缓冲区:

如上图:
- P(position),代表下一个可读写的位置
- L(limit),代表不可读写位置的开始
- C(Capacity),代表缓冲区的大小
有朋友可能会问:那么这个缓冲区如何读取呢?
flip操作
读取这样的缓冲区就需要进行缓冲区的翻转,也就是flip操作。
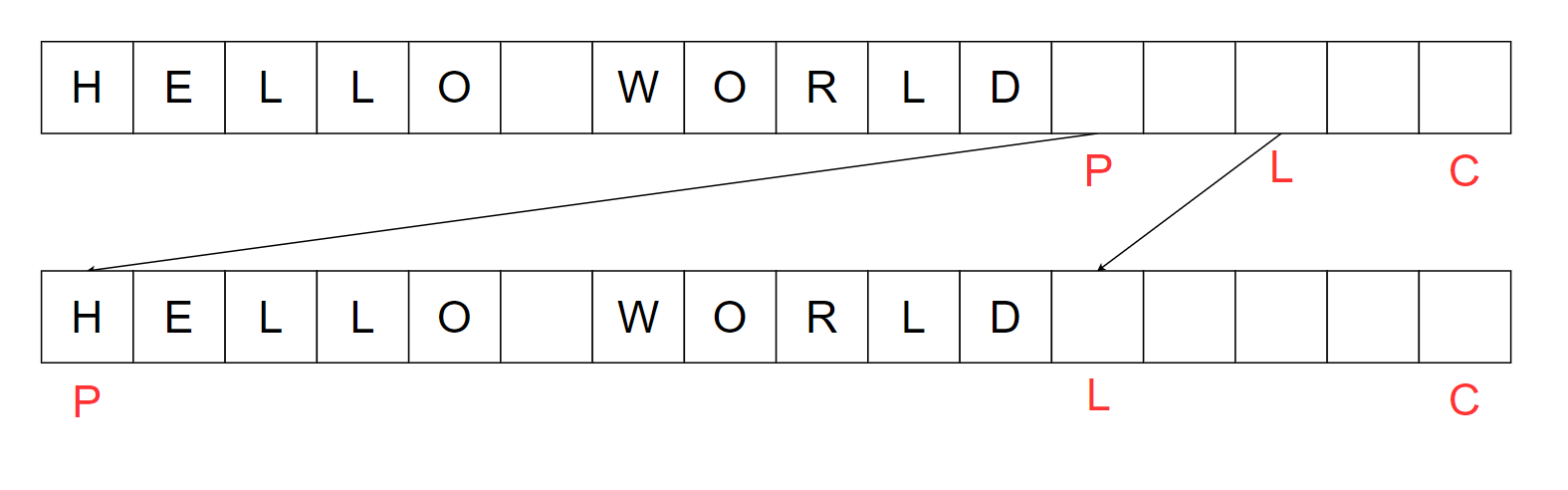
上图中的flip操作,将position设置为0,limit设置为position的位置。这样就从一个写入缓冲区,切换到了读取缓冲区。接下来,我们就通过指针P就可以读取缓冲区的内容,而limit左边的就是有数据的。
所以flip操作的作用是帮助缓冲区在读写之间切换。
通过这个例子,你会发现,limit才缓冲区的实际数据范围,Capacity是一个物理限制。
clear操作
当缓冲区使用完可以进行清空。清空操作将缓冲区恢复到初始状态。也就是position=0,Limit=Capacity的状态。这个操作称之为clear操作,如下图所示。

rewind操作
另外,有时候我们需要重新读取流中的数据。这个时候,就像倒带(rewind)一样,需要将position置0,其他不变。
实战举例
友情提示。所有的实战建议大家都看一下视频。视频里的讲解深度一行一行带你敲的感觉和文档是不一样的。
我用下面这段程序,生成一个有10亿个英文单词的文件。你会看到我这里用了BufferedOutputStream 去包裹FileOutputStream,这样每次写入都会将内容先写入一个1024*1024的缓冲区中。缓冲区满了,才会将内容写入磁盘。
当所有的内容都写入完毕之后,这个时候缓冲区可能还会剩余一些数据。因此最后需要调用flush 方法将剩余的数据也写入磁盘。
@Test
public void gen() throws IOException {
Random r = new Random();
var bufferSize = 1024*1024;
var fileName = "word";
var fout = new BufferedOutputStream(new FileOutputStream(fileName), bufferSize);
// var fout = new FileOutputStream(fileName);
var start = System.currentTimeMillis();
for(int i = 0; i < 100000000; i++) {
for (int j = 0; j < 5; j++) {
fout.write(97 + r.nextInt(5));
}
fout.write(' ');
}
fout.flush();
fout.close();
System.out.println(System.currentTimeMillis() - start);
}
你可以尝试调节bufferSize 观察不同缓冲区大小的写入速度。上面的程序会比没有缓冲区的写入快很多倍。这是因为,写入磁盘的操作速度很慢,写入内存的速度很快,所以应该尽量将数据写入内存,向磁盘一次多写入一些数据。如果没有缓冲区,上面的程序,每次会上磁盘中写入一个字符,这样做是非常慢的。
下面我们没有缓冲区进行读取,你会发现速度非常的慢。
@Test
public void read_test() throws IOException {
var fileName = "word";
var in = new FileInputStream(fileName);
var start = System.currentTimeMillis();
int b;
var sb = new StringBuilder();
while((b = in.read()) != -1) {
sb.appendCodePoint(b);
}
var end = System.currentTimeMillis();
System.out.println((end - start) + "ms " + sb.length());
in.close();
}
好几十秒都无法完成。
接下来我们用缓冲区去改进。用BufferedInputStream 去包裹FileInputStream 。
@Test
public void read_test_withBuffer() throws IOException {
var fileName = "word";
var in = new BufferedInputStream(new FileInputStream(fileName));
var chb = CharBuffer.allocate(1024*1024);
var start = System.currentTimeMillis();
int b = -1;
var sb = new StringBuilder();
var bytes = new byte[1024];
while((b = in.read(bytes)) != -1) {
// sb.appendCodePoint(b);
}
var end = System.currentTimeMillis();
System.out.println((end - start) + "ms " + sb.length());
in.close();
}
上面程序在我的机器上,可以在1s 以内完成。这就是有缓冲区和没有缓冲区的性能差异,核心是因为读写磁盘的速度慢,读写内存的速度快。当我们读写磁盘的时候,就尽量每次多读或者多写一些数据。这也是为什么如果有很多条Sql语句在插入数据,应该尽量合并成一条批量操作的原因。
使用NIO读写
另外也可以使用Java的NIO进行处理。NIO的"N",是New的意思,就是新IO技术的意思。 所以它不是某个具体的技术,是一系列新I/O技术的集合。
比如说NIO提供了Channel处理读、写。Channel是对I/O的抽象,可以双向工作。一方面Channel连接设备,一方面Channel连接Buffer。要读取(接收)数据的时候。可以从Channel中读取数据到Buffer。在写入(发送)数据的时候,可以将数据写入Buffer,提供给Channel。
所以从这个角度去看,Channel是一种只接收Buffer进行读写的API。如果没有Channel,用户可以使用Buffer,也可以不使用Buffer。尽管不使用Buffer会很慢,有性能问题,但是用户可以这样做。可是,用户用了Channel,就必须用Buffer。所以Channel是一种规范化的l/O接口。
比如下面这段程序,用channel.read 就可以读取数据进buff非常的方便。为了实现这个过程,NIO专门读取文件的channel——FileChannel。除了专门读取文件的channel,用来读取网络请求、发送响应的Channel——SocketChannel。
@Test
public void read_test_nio() throws IOException {
var fileName = "word";
var fin = new FileInputStream(fileName);
fin.getChannel();
var reader = new InputStreamReader(fin, StandardCharsets.UTF_8);
var channel = new FileInputStream(fileName).getChannel();
var buff = ByteBuffer.allocate(1024*1024);
System.out.println(channel.size());
var start = System.currentTimeMillis();
while(channel.read(buff) != -1) {
buff.flip();
buff.clear();
}
System.out.format("%dms, %d \n", System.currentTimeMillis() - start, channel.size());
}
全部示例程序(讲解见视频)
package coding.buffer;
import org.junit.Test;
import java.io.*;
import java.nio.Buffer;
import java.nio.ByteBuffer;
import java.nio.CharBuffer;
import java.nio.IntBuffer;
import java.nio.channels.AsynchronousFileChannel;
import java.nio.channels.Channel;
import java.nio.channels.FileChannel;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.StandardOpenOption;
import java.util.Arrays;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class BufferExamples {
@Test
public void gen() throws IOException {
Random r = new Random();
var bufferSize = 1024*1024;
var fileName = "word";
var fout = new BufferedOutputStream(new FileOutputStream(fileName), bufferSize);
// var fout = new FileOutputStream(fileName);
var start = System.currentTimeMillis();
for(int i = 0; i < 100000000; i++) {
for (int j = 0; j < 5; j++) {
fout.write(97 + r.nextInt(5));
}
fout.write(' ');
}
fout.flush();
fout.close();
System.out.println(System.currentTimeMillis() - start);
}
@Test
public void read_test() throws IOException {
var fileName = "word";
var in = new FileInputStream(fileName);
var start = System.currentTimeMillis();
int b;
var sb = new StringBuilder();
while((b = in.read()) != -1) {
sb.appendCodePoint(b);
}
var end = System.currentTimeMillis();
System.out.println((end - start) + "ms " + sb.length());
in.close();
}
@Test
public void read_test_withBuffer() throws IOException {
var fileName = "word";
var in = new BufferedInputStream(new FileInputStream(fileName));
var chb = CharBuffer.allocate(1024*1024);
var start = System.currentTimeMillis();
int b = -1;
var sb = new StringBuilder();
var bytes = new byte[1024];
while((b = in.read(bytes)) != -1) {
sb.appendCodePoint(b);
}
var end = System.currentTimeMillis();
System.out.println((end - start) + "ms " + sb.length());
in.close();
}
@Test
public void read_test_nio() throws IOException {
var fileName = "word";
var fin = new FileInputStream(fileName);
fin.getChannel();
var reader = new InputStreamReader(fin, StandardCharsets.UTF_8);
var channel = new FileInputStream(fileName).getChannel();
var buff = ByteBuffer.allocate(1024*1024);
System.out.println(channel.size());
var start = System.currentTimeMillis();
while(channel.read(buff) != -1) {
buff.flip();
buff.clear();
}
System.out.format("%dms, %d \n", System.currentTimeMillis() - start, channel.size());
}
@Test
public void test_async_read() throws IOException, ExecutionException, InterruptedException {
var fileName = "word";
var channel = AsynchronousFileChannel.open(Path.of(fileName), StandardOpenOption.READ);
var buf = ByteBuffer.allocate(1024);
Future<Integer> operation = channel.read(buf, 0);
var numReads = operation.get();
buf.flip();
var chars = new String(buf.slice().array());
System.out.println(chars);
}
}
总结
缓冲区的作用是缓冲。系统的衔接没有缓冲,是危险的。网络、磁盘的I/O没有缓冲是低效的。在高速和低速之间提供一片缓冲区,可以提高效率,这是因为批量处理的效率高于逐个处理;也更安全,有缓冲可以避免突然遇到计算能力瓶颈。所以我们在设计系统的时候要注重缓冲区的衔接,遇到高并发——交易、聊天、搜索、服务对接……先设置缓冲区,再思考如何去处批量处理。