面试官出难题:并发环境下单例怎么写性能最高
「最好」类问题是永无止境的,只有想办法做到更好。
要回答「怎样写单例最好」,我们要重新审视并发编程,并发编程有3个要素:
- 原子(atomic)
- 顺序(ordering)
- 可见(visibility)
我们平时讨论一致性实际上是有序的体现,讨论A发生在B前,实际上讨论的是对B,A的可见性。「原子」已学,这节课我们结合Java的happens-before关系和volatile讨论顺序和可见。
这节课我们关联的面试题有:
- 如何解释内存一致性模型?
- 什么是happens-before关系?
- 为什么要设计volatile关键字?
- volatile关键字原理是什么?
- 并发环境下单例怎么写?
- volatile的性能怎么样?
顺序体现:什么是内存一致性?
计算机程序就是一个读写内存+计算的模型——所有程序皆是如此,不断读取内存中的指令,不断执行指令,不断读写内存。指令无非就3中,读、写、计算。能影响内存的,就是读和写。从绝对的时间观来看,指令的读和写是有顺序的,并行是不存在的。好比两条并行写一个内存地址的指令,最后一定会分出先后,只有一条指令的结果可以留下来。这是因为我们今天的计算机,是基于经典物理模型制造的。如果是量子计算机,可以允许一个量子比特同时有多个状态,就好像平行宇宙一样。所以从经典的时空观去看指令的执行,一定会有顺序:

因此,并行是在竞争执行顺序,而不是真的并行(产生分歧的结果,像平行宇宙那样)。这样,从时间维度,内存就可以看做一个个版本,而触发版本变化的是写指令。比如2个线程并行的写一个内存地址,实际会给内存的历史增加两个版本。只是因为其中一个版本存在的时间过于短暂,最后人们看到的是竞争后的结果。

既然内存中存在大量短暂的版本,在某个时刻,如果线程1、线程2观察内存,会不会得到不同的版本呢?比如图中,线程2认为版本3的写操作已经发生;线程1认为版本3的写操作还没有发生。因此,产生分歧。事实上,我们的系统中存在大量的这类问题——我们称为内存不一致。如果在一个观察平面(某个时刻),线程对内存的历史版本理解一致,就们就称为内存一致。任何时刻,多个线程,对内存的理解总是一致的,我们就认为他们拥有共同的历史,称为线性一致(Sequential consistency)。如果只有其中部分确定的时刻是一致的,那么我们称为**弱一致(weak consistency)。**如果总是不一致,或者无规律可查,就称为没有一致性。
从编程模型上说,线性一致是最强的保证,程序员可以不用在意并发产生的一致性问题。弱一致性环境下,程序员要使用一些同步元语(primitives)——比如锁、信号量、阻塞队列、屏障等等,还有这节课要学习的happens-before和volatile关键字。总之,弱一致性下,程序员需要工具。 在不使用工具的情况下,程序语言一般只支持到弱一致性。
我们在解决并发问题的时候,期望有序:任意时刻,不同线程观察到的历史是一致的(操作顺序是一致的——操作是相同的)。这个性质也称作有序性,更多的时候我们称为线性一致(Sequential consistency),代表历史没有产生分支,历史一致。
并发导致不一致示例
下面这段程序可以直接导致内存不一致。即便执行顺序是:
a=1;
println(b);
b=1;
println(a);

结果仍然可能是两个0 ,这是因为指令重排和分级缓存策略的存在。
分级缓存策略
现代计算机的设计中,每个CPU都有自己的缓存(L1,L2两层)。共享的L3缓存和内存。 这是因为在成本不变:速度越快的存储发热越大,容量越小。L1缓存读写可以在少数几个CPU周期内完成,L2读写也可以在个位数,L3缓存读写在2位数CPU周期内完成,内存读写会比L3慢10-100被,相当于100~1000个CPU周期。
读取指定内存地址的值,可以先从L1开始,然后L2,然后L3,都没有找到再去内存中读取。考虑到其中每一级都有80%的命中率,因此整体来说读取内存99%的操作都是在缓存中执行的。像这样,缓存根据读写速度不同分级,速度越快造价越高容量越小,速度越小造价越低容量越大,对数据的访问进行分级加速的模型,我们称为分级缓存策略。
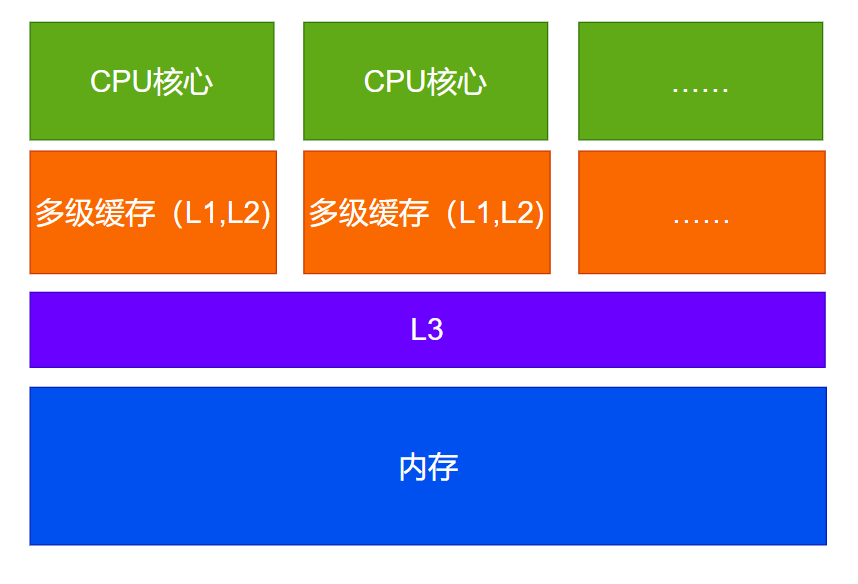
下图中,我们演示了写入a=1 的过程,需要先写L1、L2,再写L3,然后写内存。
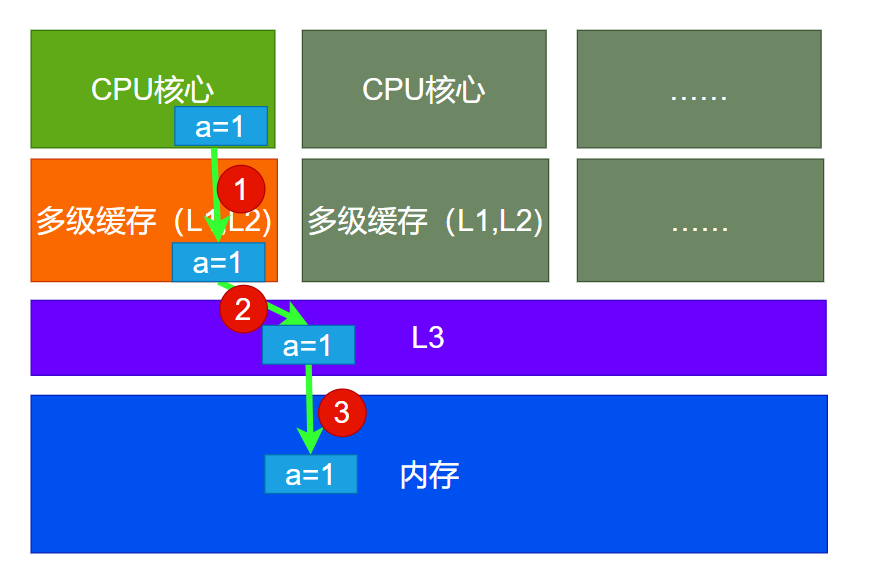
但是这也产生了一致性问题:在事件1完成后,同核心的线程就可以读到最新版本的a了,从L1中。但是跨CPU的线程,得从内存或者L3中读取,这个时候有可能读不到最新版本。所以尽管synchronized解决了两个线程不可能穿插执行,但是仍然会出现一致性问题。
观察到的一种现象:a=1执行完成后,线程B可能会print出a=0(不同CPU,并发),也可能print出a=1(同CPU)。
这样,同一时刻,多个线程对内存版本的理解就不一致了。
指令重排问题
面试题:举例一个指令重排的具体例子?
还有一个影响一致性的问题是指令重排,CPU是可以重排指令的。 比如:
read(a) -> Register1
read(b) -> Register2
Register1 + 1
Register2 + 1
读取a 如果没有命中缓存,读取b 命中了缓存。 可以考虑先执行Register2+1。
因此,Java虚拟机在模拟计算机,因此也引入了指令重排技术。部分指令Java虚拟机明确知道性能差异的情况下可以进行优化。
举个具体的Java例子,比如:
if(a == 0) {
// some code ...
}
return a;
如果some code 中没有明确看到对a 的修改,那么对Java编译器而言a=0 对a 的读取, 和return 对a 的读取顺序是可以重排的。但是如果考虑到并发环境,其他线程在some code 执行的过程中修改了a ,那么会导致两次读取到a 的值不一致。比如其他地方设置了a=1,可能有a=0 没执行,但是return a 返回0 的情况。
阶段小结
内存一不一致,是相对的——需要确定观察者。我们通常以线程位观察者,比较多个线程的结果,来思考内存满不满足一致性。分级缓存策略和指令重排是触发内存不一致的两大原因,那么入门该如何来避免这个问题呢?
happens-before关系:解决内存一致性问题
为了解决内存一致性模型,Java提供了一些控制执行顺序和可见性关系的元语,我们称为happens-before 。
happens-before和volatile关键字
考虑下面的程序:
static int a = 0;
public static void main(String[] argv) {
Runnable r1 = () -> {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
a = 10000;
System.out.println("a="+a);
};
Runnable r2 = () -> {
System.out.println("enter a =" + a);
while(a < 100) {
}
System.out.println("end" + a);
};
new Thread(r1).start();
new Thread(r2).start();
}
上面程序中a=10000 可能不会被线程2观察到, 进入无限循环。
原因分析:第一个线程写入内存的值,只写了自己的缓存和内存,但是没有写其他CPU的缓存。第二个Runnable 观察时,总是看的自己CPU的缓存,导致两个线程对数据理解不一致,违反了内存一致性。
再思考本质一点,是因为a=10000 这个写入操作,从逻辑上是应该会早于1s以后a<100 对a的读取操作——而实际的情况,a<100 并没有看到a=10000 这次写入。要解决这个问题,Java提供了happens-before规则:如果事件A逻辑上发生早于事件B,那么事件B发生时应该可以看到事件A的结果。
具体解决这个问题,Java提供的叫做volatile happens-before规则。volatile保证如果逻辑上,volatile变量的写在读之前发生,那么能够确保观察到的结果,写也在读之前发生。
因此只需要将a 设置为volatile 就可以了。
volatile static int a = 0;
这样如果写入事件a=10000 从时间上早于读取时间a<100 ,那么最终观察到的结果就是a=10000 。
volatile 确保语义上对变 量的读、写操作顺序被观察到(确保可见性)。事实上实现volatile 需要做三件事:
- 对volatile变量的读、写不会被重排到对它后续的读写之后(阻止指令重排)
- 保证写入的值可以马上同步到CPU缓存中(写入后要求CPU马上刷新缓存)
- 保证读取值时能读到最新版本(比如读L3-Cache,读内存,甚至更复杂的策略,这个和平台实现都有关,超出讨论范围。如果面试官问,可以这样回答)
volatile应用举例:双检查单例模型
考虑一个单例程序:
class Foo {
static DbConnection mysqlConnection;
public static DbConnection getDb(){
if(mysqlConnection == null) {
mysqlConnection = new MysqlConnection(...);
}
return mysqlConnection;
}
}
如果考虑到并发场景:
class Foo {
static DbConnection mysqlConnection;
public static DbConnection getDb(){
synchronized(Foo.class) {
if(mysqlConnection == null) {
mysqlConnection = new MysqlConnection(...);
}
}
}
}
// 或
class Foo {
static DbConnection mysqlConnection;
public synchronized static DbConnection getDb(){
if(mysqlConnection == null) {
mysqlConnection = new MysqlConnection(...);
}
}
}
如果希望减少使用锁的范围,这个称为lockless 设计。翻译成少锁设计,无锁设计后面我们会专门讨论,叫做lock-free 。
class Foo {
static DbConnection mysqlConnection;
public static DbConnection getDb(){
if(mysqlConnection == null) {
synchronized(Foo.class) {
if(mysqlConnection == null) {
mysqlConnection = new MysqlConnection(...);
}
}
}
return mysqlConnection;
}
}
上面程序进行了判断null ,如果并发量大,减少对锁的争夺。但是上面程序会有一个问题——java 允许部分构造的类。也就是说,一个线程获得锁成功初始化了mysqlConnection 时,另一个线程可能会看到mysqlConnection 不是null 但是如果它尝试使用mysqlConnection 会报错。
这个时候java 可以用happens-before 关系进行管理。保证对类型使用发生在对类型初始化完成后。这个也是用volatile 关键字。
static volatile DbConnection mysqlConnection;
增加了volatile 的程序:
class Foo {
static volatile DbConnection mysqlConnection;
public static DbConnection getDb(){
if(mysqlConnection == null) {
synchronized(Foo.class) {
if(mysqlConnection == null) {
mysqlConnection = new MysqlConnection(...);
}
}
}
return mysqlConnection;
}
}
上面程序还有一个性能问题,就是mysqlConnection 多次读取volatile 变量,指令不能重排,读取也会慢一些。可以考虑增加本地引用:
class Foo {
static volatile DbConnection mysqlConnection;
public static DbConnection getDb(){
DbConnection localRef = mysqlConnection;
if(localRef == null) {
synchronized(Foo.class) {
localRef = mysqlConnection;
if(localRef == null) {
mysqlConnection = localRef = new MysqlConnection(...);
}
}
}
return mysqlConnection;
}
}
另外,其实有一个更好的做法,是利用Atomic 类。Atomic 利用cas 直接可以让进程进步,例如这样实现:
static AtomicReference<DbConnection> ref = new AtomicReference<>();
public static DbConnection getDb(){
// 读取当前的ref内存中的真实值
var localRef = ref.getAcquire();
if(localRef == null) {
synchronized (Foo.class) {
localRef = ref.getAcquire();
if(localRef == null) {
localRef = new DbConnection();
// 设置新的ref
ref.setRelease(localRef);
}
}
}
return localRef;
}
程序中的ref.getAcquire,ref.setRelease 通过底层实现保证了happens-before顺序。相比volatile 阻止指令重排,acquire 和release 允许一定范围的指令重排,比如:
指令1
指令2
acquire/release/volatile
指令3
指令4
- 上面的场景中
volatile会保证执行顺序:1,2,volatile,3,4 - acquire/release只保证自己在1,2之后,在3,4之前
我们也称这种行为是relaxed atomics 。因为允许一定范围的指令重排,因此acquire/release 性能更好。
面试官:还有哪些Happens-before关系?
单线程规则:单线程内,总是符合happens-before规则。

Monitor规则:synchronized对锁的释放 happens-before 对锁的获取
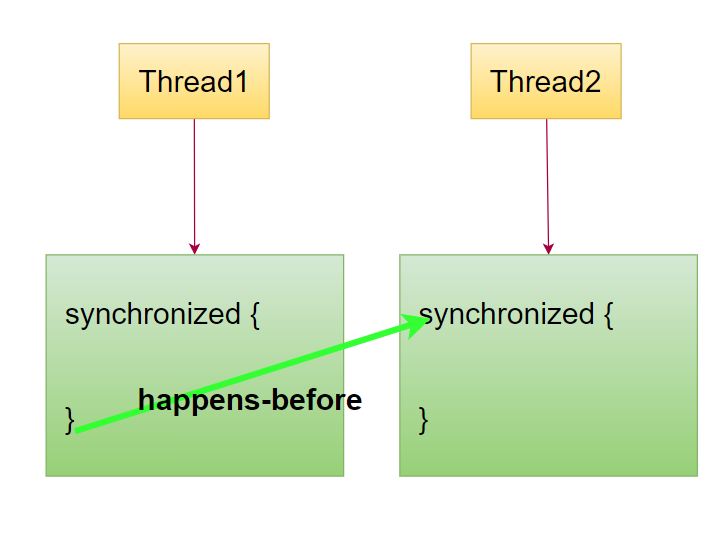
volatile规则:volatile变量的操作happens-before对它的后续操作(并且周围指令不会重排)
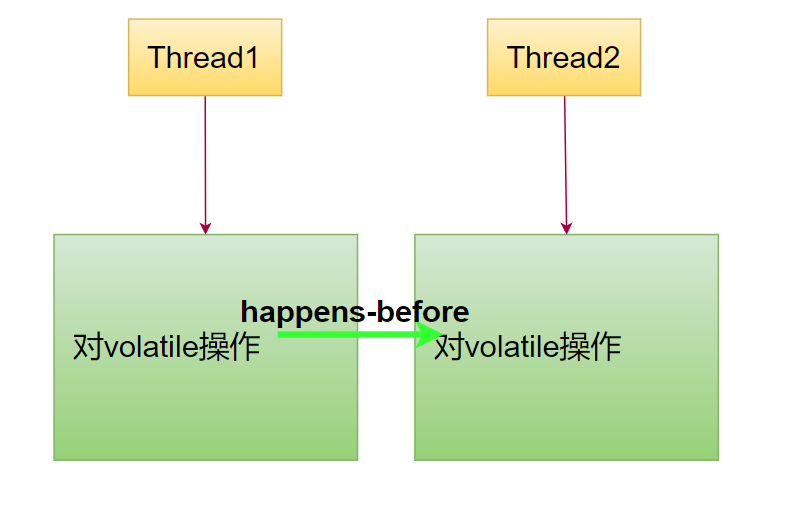
Relaxed Atomics acquire/release规则(Java 9):getAcquire和setRelease操作 happens-before 后续的操作。
操作1
操作2
acquire/release
操作3
操作4
操作1,2可以重排,操作3,4可以重排,操作1,3不可以重排。
Thread Start规则:start()调用前的操作 happens-before 线程内的程序
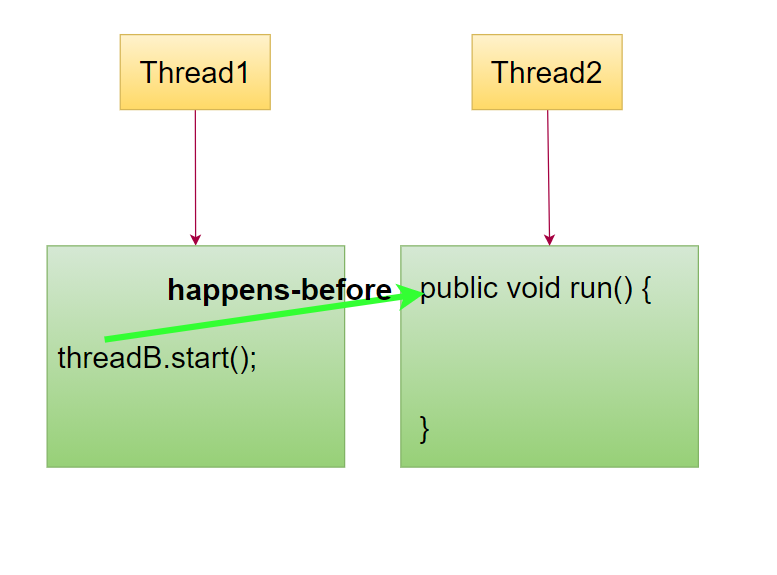
Thread.join规则:线程的最后一条指令 happens-before join后的第一条指令
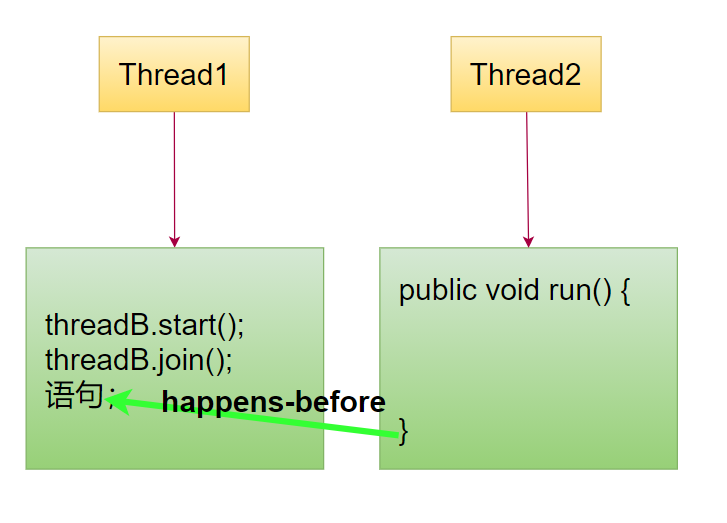
happens-before传递性:如果A happens-before B, B happens-before C,那么A happens-before C
总结
总结一下,happens before不是时间关系,happens before是发生顺序和观察到的结果关系。类似因果关系。happens-before是操作顺序和可见性的关系。
通常我们说解决并发问题有3个要素:
- 原子性
- 有序性
- 可见性
那么我们之前学习的cas 是为了解决原子性。今天我们学习的happens-before 是为了解决有序性和可见性。
最后A happens-before B,可以读做:如果A在B前发生,那么A带来的变化在B可以观察到(对B时刻在观察的线程可见)。
happens-before是partial ordering(部分有序)。参考Relaxed Atomics,重要的顺序保证,其他仍然可以重排。
我希望大家通过学习happens-before ,去思考Java语言的设计。 规则是什么?规则就是可以重复利用,来处理相似问题的方法。happens-before 这样的规则设计出来,从实现上,应该是统一的。并不是为volatile,为synchronized等去实现它们每个人的happens-before,从实现层面,我们应该通过规则去配置出volatile和synchronized,甚至更多的happens-before规则。 这样的设计,才能称为一个规则。 业务是灵活多变的,业务规则应该是统一完整的。从规则角度实现业务,应该可以做到配置化。这些,是我希望大家进一步思考的内容。处理1-2个happens-before问题,具体问题具体分析;处理更多的happens-before问题,应该思考happens-before的明确对应,并且实现规则引擎和相关算法。
好的,这节课就到这里,下一节课,我们将学习并发数据结构——Java的5种同步队列。