手写链表算法
链表是最简单的跳跃结构。 跳跃结构是相对于连续结构而言的,比如数组就是连续结构,内存本身和数组能够1-1对应,内存是一种随机存取结构,同时内存也是连续的。在内存中1个单元紧挨着1个单元。
今天的计算机遵循冯诺依曼体系,我们所有的数据结构,都会建立在连续结构(内存)之上。有的内存地址存储了数据,有的内存地址存储的是指针。指针是什么?内存单元没有存储数据,而是存储了其他的地址,就是指针。
下图中就是一个指针:内存地址0存储的数据4,实际上是指向内存地址4的指针。通过这种方式就可以构造跳跃结构。特别简单的去理解,跳跃结构就是有指针的数据结构。
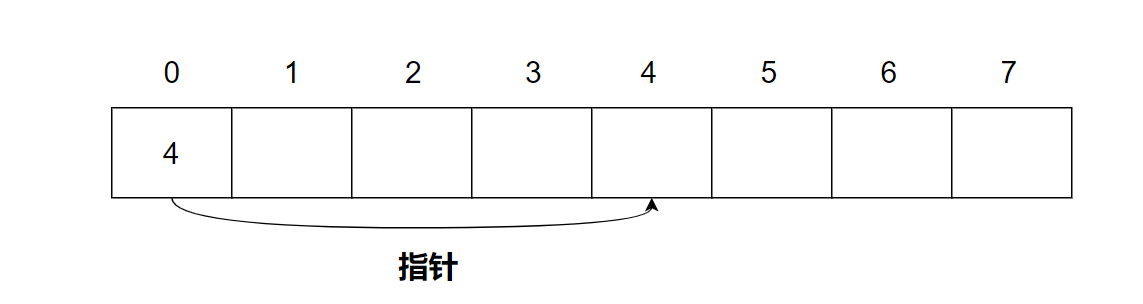
跳跃结构通常是无界(unbounded)的,使用者不太需要关注数据结构的存储的上限。这并不是说真的没有上线,比如把内存空间都用完了,会产生内存不足的问题。这里说的无界,是因为跳跃结构分配空间的成本较低——只要能找到一个很小的内存区域就可以分配几个节点。
我们程序语言的设计当中,通过有界且连续的数据结构(栈),组织函数的调用、程序的执行……然后通过无界的数据结构(堆)来为对象分配内存。简单理解,程序执行在栈上,数据分配在堆上。
数据结构中最复杂的跳跃结构是图(Graph)。
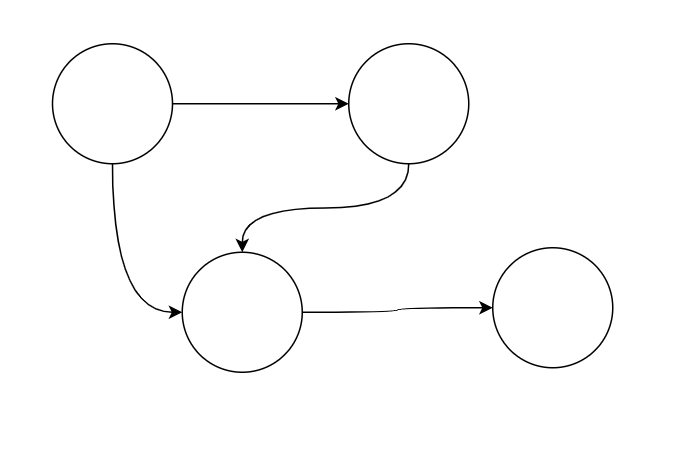
在图中对于元素的指向没有任何要求,一个节点可以指向多个节点,多个节点也可以指向一个节点。
树是一种特殊的图,每个节点可以有多个出去的路径,但是只能有一条进入的路径。
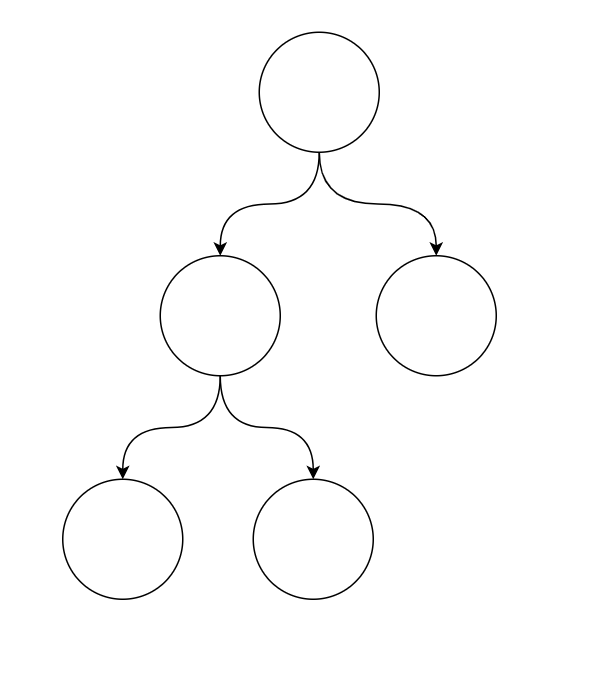
从某种意义上来说,链表是一种特殊的树,每个节点出去、进入的路径都只能有1个。
抽象数据结构
什么是数据结构?简单理解就是聚合了数据和操作的容器。
研究数据结构通常有两个维度。抽象数据结构简单理解就是数据结构的接口,研究的是数据结构的功能和作用,约定数据结构有哪些方法?有哪样的能力?另一个维度是底层的维,研究的是数据结构,具体应该如何去实现。
所以我这里想请问大家一个问题:对于程序员而言,哪个维度更重要?显然是抽象数据结构的维度更重要。理解了抽象数据结构,你就会用数据结构。因为多数情况下,很多数据结构,是由专业度非常高的程序员在设计。而专业度相对较低,从事业务开发的程序员,更多是理解的是数据结构的功能——类似学会用计算器。
但是对于想进入优秀团队的程序员们来说,这两件事情就是同等的重要。因为作为优秀的程序员需要对业务进行建模,而业务进行建模的本质就是将业务逻辑本身能抽象成数据结构。领域驱动开发归根结底,是将领域对象核对领域对象的操作方法聚合在一起。有生命力的对象自己会自己做事情,这就需要扎实的数据结构设计功底。
链表是一种抽象数据结构,从底层看链表,又有一定的算法实现在里面。作为入门算法和数据结构的知识再合适不过。而且链表的使用范围非常的广泛,Java的设计者就大量使用的链表。所以为了大家能够听懂后续的课程,链表是必修课。如果你对链表已经足够的熟悉,就可以跳过这一部分的内容。
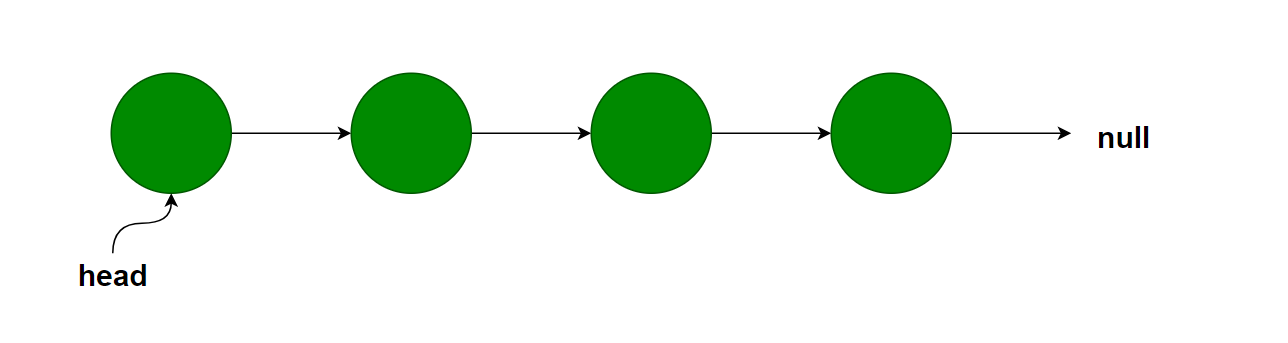
链表的表示
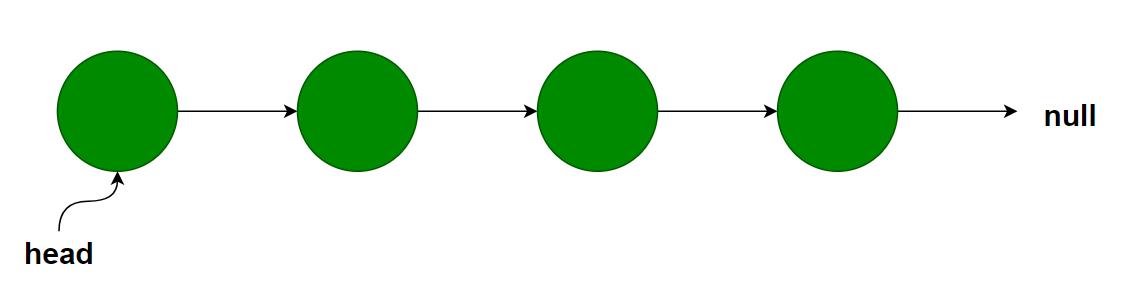
链表有两种,一种是单向链表。像下面这样,每个链表的节点都有一个next指针,指向下一个节点。
public class List<T> {
static class Node<T> {
Node<T> next = null;
T data;
public Node(T data){
this.data = data;
}
}
Node<T> head = null;
}用程序表示,就是上面这样。链表整体作为一个类, 泛型T代表链表中数据的类型。每个节点又抽象成一个子类,每个节点有T类型的数据和next指针。 然后链表类中有一个头(head)指针,指向链表的第一元素。
另一种是双向链表(LinkedList)。
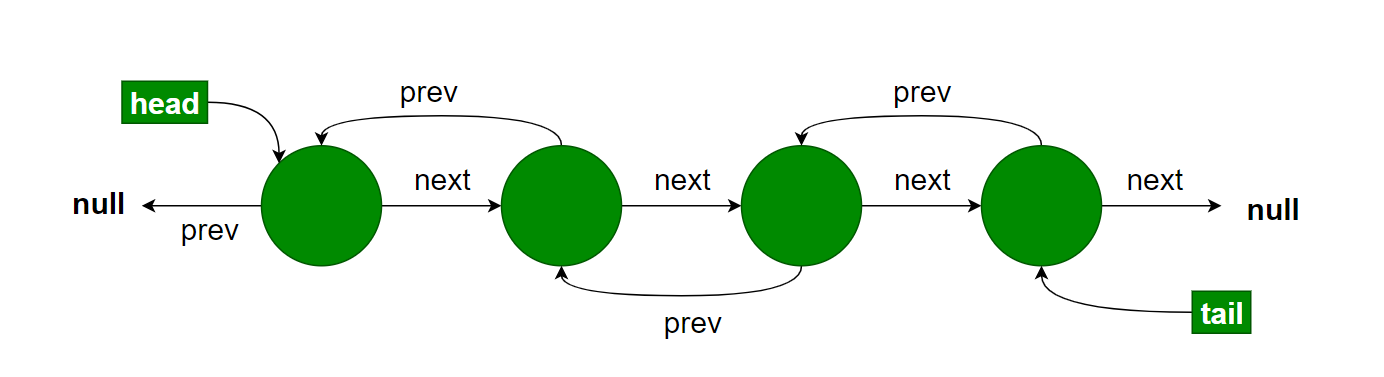
每一个节点都有一个向前的next指针。和一个向后的prev(ious)指针。链表本身有一个head指针指向第一个元素,有一个tail指针指向最后一个元素。具体程序表示如下:
public class LinkedList<T> {
static class Node<T> {
Node<T> next = null;
Node<T> prev = null;
T data;
}
Node<T> head = null;
Node<T> tail = null;
}增删改查
作为一个数据结构,通常需要实现增删改查。作为链表,修改数据可以建立在查询之上,不用专门提供接口。
插入(头插法)
单向链表通常通过头插法插入元素,只需要将head指向新元素,新元素指向原来的head就行。
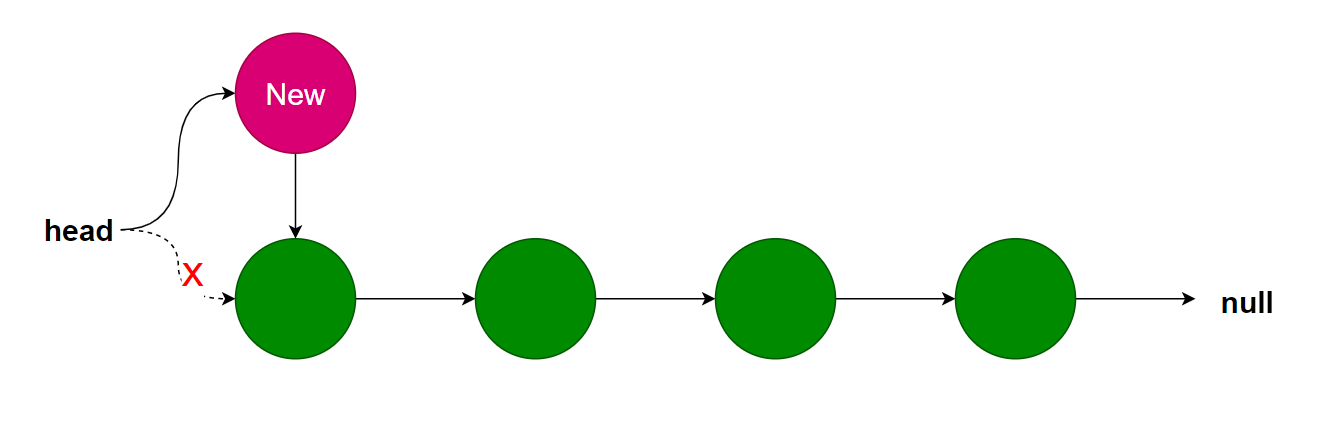
具体程序如下:
// O(1)
public void insert(T data) {
var node = new Node<>(data);
node.next = head;
head = node;
}这段程序的时间复杂度是O(1)。上面程序在head=null的情况下,依然可以正常工作。
插入的测试用例:
@Test
public void test_insert(){
var list = new List<Integer>();
list.insert(1);
list.insert(2);
list.insert(3);
var p = list.head;
for(Integer i = 3; p != null ; i--) {
assertEquals(i, p.data);
p = p.next;
}
}size()操作符
链表中计算元素的个数,需要一个个数。
public Integer size(){
var p = head;
Integer c = 0;
while(p != null) { p = p.next; c++; }
return c;
}上面这段程序的复杂度是O(n)。这里我给你提一个问题,作为一名秀的设计者,如果提高size的速度?
提示:可以提供一个整数型的计数器,在insert的时候++, 在remove的时候--。
查询
链表中查询一个元素,只有从头找起。 注意我这里用了Predicate<T>,这是复用Java的能力。
// O(n)
public Node<T> find(Predicate<T> predicate) {
var p = head;
while(p != null) {
if(predicate.test(p.data)) {
return p;
}
p = p.next;
}
return null;
}上面程序的时间复杂度是O(n)。
删除
删除分成3种情况:
- 链表是空的(直接返回)
- 头指针指向需要删除的元素(head = head.next)
- 一个个找需要删除的元素
// O(n)
public void remove(Node<T> node){
if(head == null) {
return;
}
if(head == node) {
head = head.next;
return;
}
Node<T> slow = head;
var fast = head.next;
while(fast != node && fast != null) {
slow = fast;
fast = fast.next;
}
if(fast != null)
slow.next = fast.next;
}情况3中,慢指针(slow),总是比快指针(fast)慢一个元素。当快指针指向需要删除的元素时,通过操作slow.next = fast.next删除掉这个元素。
上面程序的时间复杂度是O(n)。
思考:关于内存的回收?上面程序没有考虑内存的回收,那么需不需要增加一些辅助内存回收的代码?
查找删除的测试用例:
@Test
public void test_find_remove(){
var list = new List<String>();
list.insert("C++");
list.insert("Java");
list.insert("C");
list.insert("C#");
list.insert("python");
var node = list.find(x -> x == "Java");
assertEquals("Java", node.data);
var node2 = list.find(x -> x == "ruby");
assertEquals(null, node2);
list.remove(node);
assertEquals(Integer.valueOf(4), list.size());
assertEquals(null, list.find(x -> x == "Java"));
}反转链表
反转一个链表的难点在于如果只用两个指针不太好进行操作:
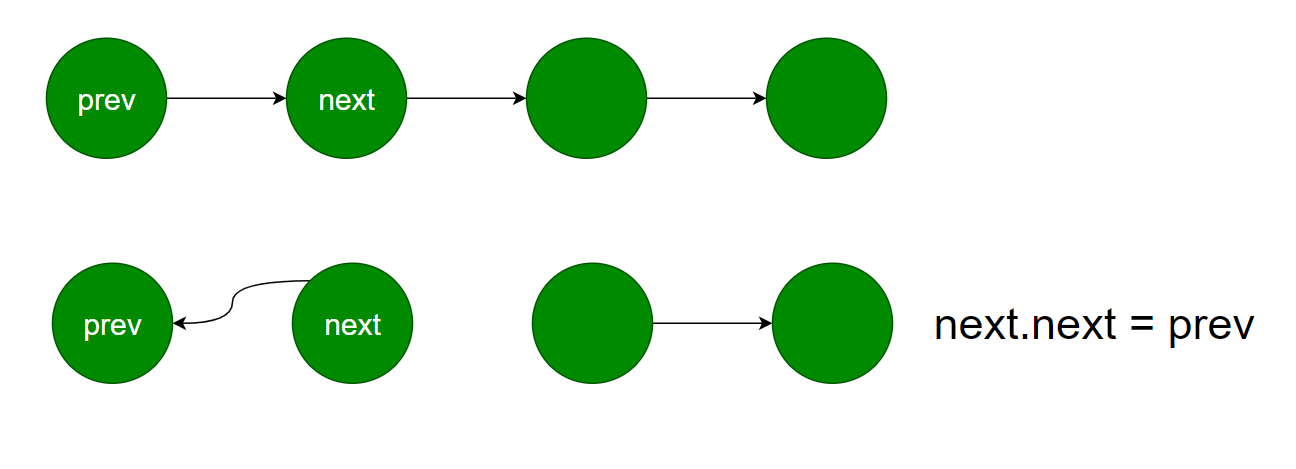
上图中,如果用双指针(快慢指针),进行一次反转操作后,next指针无法继续向右。
3指针法
第一种思路是利用3个指针:

每次是将current.next = prev,执行完后,还有一个next 指针可用于构造下一组<prev, current, next>。
程序如下:
public void reverse(){
// prev | current | next
Node<T> prev = null;
var current = head;
Node<T> next;
while (current != null) {
next = current.next;
current.next = prev;
prev = current;
current = next;
}
head = prev;
}测试用例如下:
@Test
public void test_reverse() {
var list = new List<Integer>();
list.insert(1);
list.insert(2);
list.insert(3);
list.reverse();
var p = list.head;
for (Integer i = 1; p != null; i++) {
assertEquals(i, p.data);
p = p.next;
}
}递归法
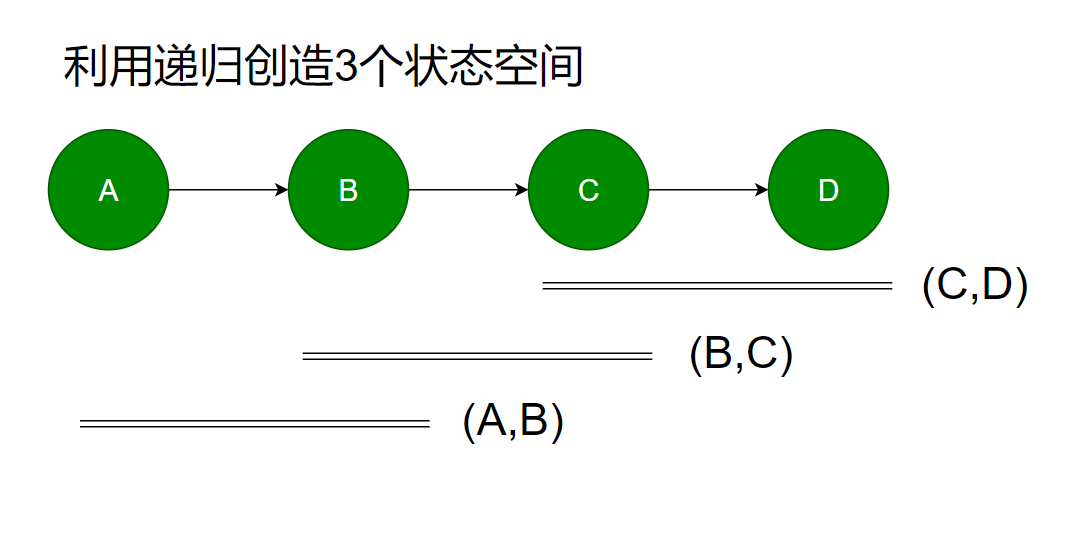
这种方法有很强代表性,利用递归形成的状态空间。
什么是状态空间?每次递归的调用,递归的参数都会被拷贝一次,这样每次递归就是一个空间,称之为递归的状态空间。
下图是我们反转一个有4个元素的链表,可以用递归构造出3个状态空间,每个空间中刚好有要反转的两个节点。
另外一种思考方式是基于递归的语义,递归就是把规模更小重复的子结构按照相同的方式进行处理。
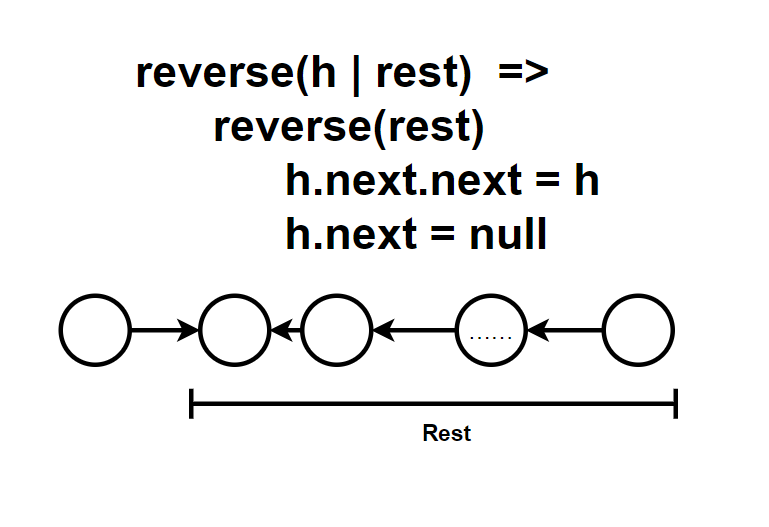
从语义上来说,如果我们要反转一个链表。我们先将链表分成两个部分,头元素h和剩余的链表rest,分成3个步骤:
- 将rest反转
- 将头元素h下一个元素指向h:h.next.next = h
- 将头元素指空作为尾元素: h.next = null
以上是两种递归的分析方法,下面是递归的程序:
private Node<T> _reverse2(Node<T> head) {
if(head == null || head.next == null) {
return head;
}
Node<T> rest = _reverse2(head.next);
head.next.next = head;
head.next = null;
return rest;
}
public void reverse2() {
head = _reverse2(head);
}环状检测
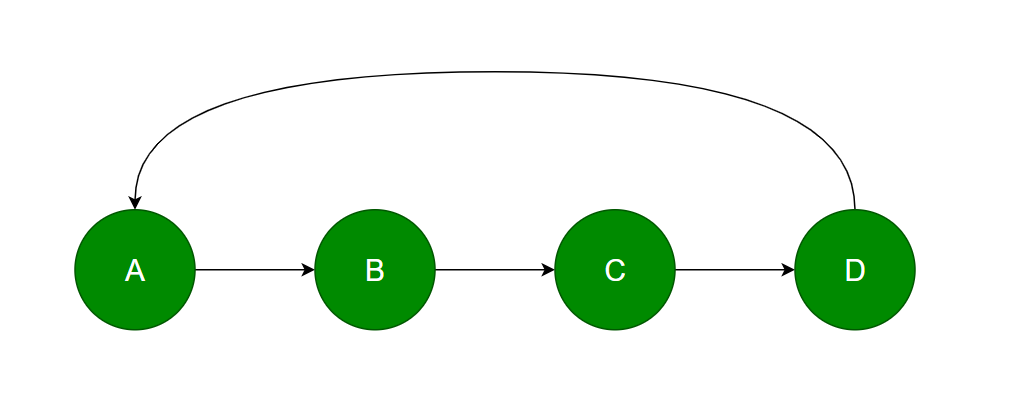
检测一个链表有没有环最简单的方式,就是通过集合(Set)。把链表中的所有元素都加入集合,如果有重复加入的现象,那么就有还。代码如下:
public boolean hasLoop1(){
var set = new HashSet<>();
var p = head;
while(p != null) {
if(set.contains(p)) {
return true;
}
set.add(p);
p = p.next;
}
return false;
}但是这样的方式需要建立一个跟链表元素个数相等的Set(通常是哈希表),浪费空间。您可以设想列表中有100万个元素,那这个HashSet可能会非常大,得不偿失。这种方案,我们称为空间复杂度很高,是O(N)。
有一个空间复杂度为O(1)的方式,可以使用快慢指针。
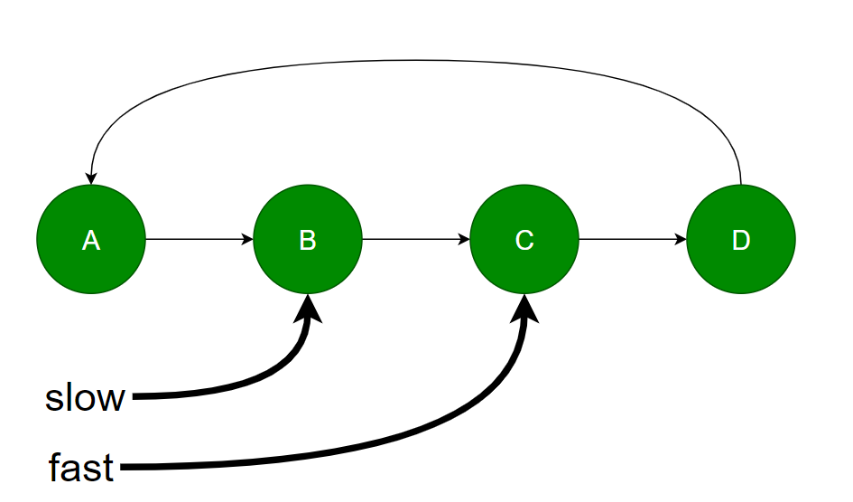
快指针每次走2个节点,慢指针每次走一个节点。那么它们如何可以相遇,就有环。你可能会问,在有环的情况下,快指针有没有可能越过慢指针?可以这样思考:
- 如果快指针到了慢指针前1个位置(下一次循环他们会相遇)
- 如果快指针到了慢指针当前的位置(那么它们相遇)
- 其他情况可以转化为上面的两种情况之1
以上的思考方式,在数学上叫做数学归纳法。但是从人的思考角度去看,这叫做归纳。归纳是一个我们每个人都有的思维方式,并不需要从数学中学习,但是可以从数学中得到更好的锻炼。
全部代码:
package datastructure;
import org.junit.Test;
import java.util.HashMap;
import java.util.HashSet;
import java.util.function.Predicate;
import static org.junit.Assert.assertEquals;
public class List<T> {
static class Node<T> {
Node<T> next = null;
T data;
public Node(T data){
this.data = data;
}
}
Node<T> head = null;
// O(1)
public void insert(T data) {
var node = new Node<>(data);
node.next = head;
head = node;
}
// O(n)
public Node<T> find(Predicate<T> predicate) {
var p = head;
while(p != null) {
if(predicate.test(p.data)) {
return p;
}
p = p.next;
}
return null;
}
public Integer size(){
var p = head;
Integer c = 0;
while(p != null) { p = p.next; c++; }
return c;
}
// O(n)
public void remove(Node<T> node){
if(head == null) {
return;
}
if(head == node) {
head = head.next;
return;
}
Node<T> slow = head;
var fast = head.next;
while(fast != node && fast != null) {
slow = fast;
fast = fast.next;
}
if(fast != null)
slow.next = fast.next;
}
public void reverse(){
// prev | current | next
Node<T> prev = null;
var current = head;
Node<T> next;
while (current != null) {
next = current.next;
current.next = prev;
prev = current;
current = next;
}
head = prev;
}
private Node<T> _reverse2(Node<T> head) {
if(head == null || head.next == null) {
return head;
}
Node<T> rest = _reverse2(head.next);
head.next.next = head;
head.next = null;
return rest;
}
public void reverse2() {
head = _reverse2(head);
}
public boolean hasLoop1(){
var set = new HashSet<>();
var p = head;
while(p != null) {
if(set.contains(p)) {
return true;
}
set.add(p);
p = p.next;
}
return false;
}
public boolean hasLoop2(){
if(head == null || head.next == null) {
return false;
}
var slow = head;
var fast = head.next.next;
while(fast != null && fast.next != null) {
if(fast == slow) {return true;}
slow = slow.next;
fast = fast.next;
fast = fast.next;
}
return false;
}
@Test
public void test_insert(){
var list = new List<Integer>();
list.insert(1);
list.insert(2);
list.insert(3);
var p = list.head;
for(Integer i = 3; p != null ; i--) {
assertEquals(i, p.data);
p = p.next;
}
}
@Test
public void test_find_remove(){
var list = new List<String>();
list.insert("C++");
list.insert("Java");
list.insert("C");
list.insert("C#");
list.insert("python");
var node = list.find(x -> x == "Java");
assertEquals("Java", node.data);
var node2 = list.find(x -> x == "ruby");
assertEquals(null, node2);
list.remove(node);
assertEquals(Integer.valueOf(4), list.size());
assertEquals(null, list.find(x -> x == "Java"));
}
@Test
public void test_reverse() {
var list = new List<Integer>();
list.insert(1);
list.insert(2);
list.insert(3);
list.reverse();
var p = list.head;
for (Integer i = 1; p != null; i++) {
assertEquals(i, p.data);
p = p.next;
}
}
@Test
public void test_reverse2() {
var list = new List<Integer>();
list.insert(1);
list.insert(2);
list.insert(3);
list.reverse2();
var p = list.head;
for (Integer i = 1; p != null; i++) {
assertEquals(i, p.data);
p = p.next;
}
}
@Test
public void test_loop(){
var list = new List<Integer>();
list.insert(3);
list.insert(2);
list.insert(1);
list.insert(0);
var node = list.find(x -> x == 3);
node.next = list.head;
assertEquals(true, list.hasLoop1());
assertEquals(true, list.hasLoop2());
}
}总结
链表和数组相比。
插入元素的时间复杂度从数组的O(n)减少到了O(1)。双向链表删除元素的时间复杂度可以到O(1),单向链表删除元素达不到O(1)。两个双向链表合并,可以在O(1)内完成,只需要知道一个链表的尾部和另一个链表的头部。两个单向链表合并不能在O(1),因为拿到一个链表的尾部,需要一次遍历。
另外,如果为链表实现索引访问,访问第k个元素,需要k次next计算,因此和数组相比索引器链表开销更高。
链表可以无限分配空间(unbounded),是一个数据的容器。链表可以用来实现Stack和Queue(下一节课),并发编程中大量使用链表实现队列。链表可以用来组织存储,文件系统、内存管理中都大量使用了链表。
链表可以用来实现HashTable(见哈希表部分)。