作者:triump 转载链接:https://www.zhihu.com/question/52033960/answer/1531184480
cockroachDB 百度在用之前,现在估计他们自己开发了.
主要回答下关于架构与设计
cockroachDB,yugabyteDB,kudu, TIDB 这些都是 参考了google spanner 论文 的开源实现.
这些开源实现,包括mongodb 都看过源码架构,看过很多相关的paper,以及重点看了分布式事务的实现: 原子性,隔离性, linearizability(外部一致性). 注:mongodb 虽然起源于no-sql , 但是mongodb4.0 之后的版本 已经不是no-sql 了, 可以与以上任何一位new-sql 代表PK
先统一下概念:1. table 中的数据 不管是是以 hash 方式还是以range 方式切分,切分之后的单位叫tablet(cockroachdb 里叫range , TIDB 叫partion, yugabyteDB 与kudu 里叫 tablet, mongodb 里叫chunk).
- serializability & linearizability : 这是分布式数据库的黄金标准,也就是google spanner paper 里说的外部一致性. 这里的serializability 是事务隔离的最强保证, linearizability 是CAP 领域 对于C 的最强保证. 这两个概念是正交的,linearizability 在分布式领域中更加关注single-operation, single-object, real-time order ; 而在分布式数据库中, 每个事务的提交可能会修改多个数据对象, 这些数据对象有统一的版本号,如果我们把这些数据对象看成一个整体且是原子的,然后再对这个整体 施加 linearizability 约束就达到了 serializability & linearizability 标准.
- CAP-consistency : 这里指CAP 领域中的一致性, 不是ACID 中的C。
- node : 物理机器,容器或者一个进程。
对于serializability & linearizability 标准, 目前这些开源实现里面 一个也没有达到, 只有cockroachDB 在没有 google spanner 原子钟的情况下,是最接近这个黄金标准的. 随着云硬件基础设施的完善,相信会提供出像google 的原子钟及true time api, cockroachDB 也无缝支持. 刚开始我对cockroachDB 的CAP-consistency 有很大误解,认为在没有原子钟及TSO 中心授时 下,会出很多问题, 会有stale-read , 会有性能问题,会破环serializability , 其实不然. 目前cockroachDB 目前在这方面的实现已经足够健壮,具体细节后面再讲.
从架构上讲:
共同点 :
大致都可以分为两层,上层是SQL,下层是 KVStore(支持事务API) . 所有table 数据划分为tablet(比较喜欢这个命名,没有歧义)存储在KVStore 层. 每个tablet 会有一个独立的raft group 来保证 各个replica 的数据一致. 每个raft goup 会有一个leader lease 负责这个tablet 数据的读写.
上面的设计思想应该都是inspired by google spanner . 除了上面这点相同之处, 其余的部分的设计有很多不一样.
cockroachDB 的设计:
cockroachDB 的设计非常优雅,代码分层清晰,注释非常详细,追求极致的工程实现及技术创新,官方号称是 :这个星球上最先进的,面向未来的数据库. 我认为至少在开源界是最优秀的.
- cocokroachDB 设计之初就是需要Geo-Distributed 的,整个系统没有任何单点, 没有TSO ,都不存在一个单点来检测死锁, 实现了**分布式死锁**. 另外table 的scheme 信息 以及tablet 的路由信息都会放到KVStore 上. tablet 的路由信息靠Gossip 同步. cockroachDB 的时间戳服务由 每个node 上的HLC 提供.
cockroachDB 只有一个进程, 但是其SQL 层与KVStore层分界清晰,完全可以把KVStore 独立出来, 这样上层就是一个Dist SQL 层,下层就是支持分布式事务的KVStore层,在cockroachDB 的源码里叫KV-DB. 所以cockroachDB 的部署非常简单.
另外cockroachDB 的SQL 层是一个 支持MPP 的分布式SQL 引擎, 其他几个都不支持
cockroachDB 里的 KVStore 层提供了一个支持分布式事务的API 接口给SQL 层, 让SQL层感觉下面是一个单机的存储引擎. 所以 cockroachDB 完全可以单机部署, 副本集部署,很好的适配了不同规模的企业.
另外cockroachDB 开发了自己的存储引擎Pebble, 会替换掉RocksDB, 后面可以基于这个Pebble 做很多优化.
- 每个tablet 的数据及其raft log 在 cockroachDB 中 虽然是逻辑上独立的, 但物理上并不独立, 在一个node 上的所有tablet 数据 及raft-log 都是放在一个rocksDB 实例上的,这样弊大于利,不过有提到将这些数据独立的计划.
TIDB 是 所有tablet 的raft-log 放到一个rocksDB 实例,所有tablet 数据放到另一个rocksDB 实例. kudu 是每个tablet 的raft-log 独立,放在不同的文件中,kudu 有自己的存储引擎.
而yugabyteDB 的KVStore层源自kudu ,但在上面做了大量优化, yugabyteDB 中每个tablet 的 raft-log 放在独立的文件中,可以hash 到不同disk 上, 每个tablet 的数据有一个独立的rocksDB 实例,这样直接把rocksDB 的 wal 关掉,避免了 wal-log 的两次flush disk ,这样每个tablet 数据其实是物理隔离的,这样在很多方面都有性能优势. 就是程序变复杂了,比如:在tablet split 和merge 时候需要做的更多. 当然这种物理隔离会带来更多的想象空间, 以后一个table 可以是行存也可以是列存, 支持多个存储引擎.
多说一句:yugabyteDB的设计也很优秀,主要是C++,比较喜欢. 其TSO 与cockroachDB 一样也是用的HLC ,mongodb 也是, HLC 是大趋势。另外yugabyteDB 的SQL 层是直接在postgreSQL 上直接改的, 下层KVStore 层 源于kudu,在源码里叫TServer. TServer 启动时,会去加载postgreSQL 程序作为一个子进程启动, 这样 SQL 层运行在一个子进程里,TServer也是一个进程,他们之间通过local socket 通信. 会有另外一个Tmaster 会存储tablet 的路由信息,表的scheme , 统计上报信息 等. Tmaster 也是tablet 调度的发起者, 但其并不提供TSO 服务.
cockroachDB 分布式事务: 分布式事务的实现是整个系统中最复杂的,也是必须要保证数据库正确性的. cockroachDB 的分布式事务实现非常有亮点.
1. 原子性: 其他开源实现原子性的保证都是基于2PC,看Percolator 的论文就非常清楚了,都大同小异, 但是cockroachDB 做了大量优化,引入了并行提交,让一次分布式事务的延迟优化到了理论上最小值,也就是一次raft consensus 的延迟. 另外对于交互式事务,或者说一个事务由多条DML语句的事务,引入了pipeline write ,实现了*asynchronous raft consensus.*
引入了这两个特性后,我们做了测试,极大降低了事务的延迟,比其他几个开源实现性能都要好. 估计在5 倍以上.
2. 隔离性 :cockroachDB 实现了SSI 隔离级别,也是其默认级别,以前的版本实现了SI,但在
新的版本中删除了,因为SI 会有Write-skew 问题,在客户那里出过问题. 其SSI 的实现其实是TO/MVTO 的变种,然后inspired by Write-SI (论文:A Critique of Snapshot Isolation),虽然传统的TO/MVTO 属于乐观并发控制,早期的版本是一个纯粹的乐观机制,但是cockroachDB 为了防止乐观事务不断的abort 所引入的代价,加入了锁等待机制, 也是为了保证在冲突严重的场景下,保证事务的Liveness. 另外引入了read refresh 机制 也是为了性能考虑.
注意的是: cockroachDB 的DML 操作并不会缓存在buffer 里,等 commit 时候 再 laid-down到KVStore 上, 而是事务只要发起DML,就会将相关数据laid-down 到KVStore 上,这点不同于TIDB 与yugabyteDB 。另外 cockroachDB 的分布式事务的协调者 在源码里叫做TxnCoordinator。每次事务都是生成一个TxnCoordinator 对象 来发起2PC, 而TxnCoodinator 其实是在KVStore层.
- CAP-consistency :
cockroachDB 的一致性保证 基本接近 linearizability .
cockroachDB 采用了HLC 来为 其各种读写事件定序,HLC 本质上是lamport logical clock ,且 HLC 在某个tablet replicate set 上 是严格单调递增的, 所以很容易对那些由内部因果关系的事件定序。
对于外部因果关系的追踪就需要靠HLC 的 physical clock 部分. 而这个HLC 的physical clock 部分来源于 机器的wall-time。 由于各个机器的物理时钟(物理时钟一般会通过NTP 校准) 是不准的,会有clock-skew , 但cockroachDB 会假设各个 clock 之间 存在一个max clock offset bounds.
如果各个机器的物理时钟在这个max clock offset bounds 内,则cockraochDB 就是可以保证serializability & linearizability, 达到与google spanner 一样的标准, 除了在一些极端情况下,会出现外部因果关系反转, 不满足linearizability, 对于绝大多少应用,这种情况基本不会出现.
如果这个条件不满足,可能会出现stale-read , 但是其serializability与内部因果一致性 是依然可以保证的.
总之: 即使在机器物理时钟异常情况下,cockroachDB 也是可以保证serializability 与内部因果一致的, 其实这已经是非常强的保证了. 另外GPS 原子钟 将来云上应该会提供.
赞同 2107 条评论
分享
收藏喜欢
收起

分布式数据库内核开发
关注
61 人赞同了该回答
概述
目前,数据库执行引擎主要有解释型执行引擎(a-tuple-at-a-time)、编译型执行引擎和向量化执行引擎(a-batch-at-a-time,也属于解释型)三类。CockroachDB(CRDB)早期版本中实现了基于Volcano的解释型执行引擎,即tuple-at-a-time,但这种方式虽然实现简单,但性能不佳,CRDB为了提升性能,实现了向量化执行引擎。
CRDB是采用go语言实现的,个人理解,其基于go语言实现的向量化引擎在向量化引擎的“软实现”中还是很好的。
执行引擎基本原理介绍
Volcano执行引擎
基于原理
对于用户输入的sql text,数据库查询优化器会生成物理执行计划,这个执行计划是树型结构的。在数据库执行器中,采用迭代器的方式,自上而下拉取数据(pull)。即,在执行计划树中,每一个物理算子都会调用其下层算子的next方法,获取一个tuple。 火山模型(Volcano)的优点在于:简单清晰、易于实现,也便于算子间的组合,因为算子间next方法可以返回通用的tuple格式。但火山模型产生时,查询执行的主要瓶颈来自于IO,CPU消耗并不大,这种方式的缺点也很明显:
- 为中间结果或最终结果生成一个tuple时,都会调用next函数,过于频繁
- 通常是通过虚函数或函数指针的调用next函数,低效,并降低了CPU分支预测的能力
- 该模型经常导致较差的局部性(loacality)。这可以通过考虑对压缩关系的简单表扫描来看出。例如scan data,按照volcano模型,一次一行,但当真实scan一行时,其后面的几行都会被cache到,但无法直接使用这个cache的数据,因为要等到scan的第一行完成上级多个operator的next处理后,才可以进行下一个行,这时原来cache的rows很可能已经从cache中被换出了。
性能测试
RDBMS最初就采用了Volcano执行引擎,物理执行计划为operator tree形式,tuples从下向上以pipleline模式处理。然而,关系代数的参数具有很高的自由度。例如,对于一个简单的ScanSelect(R,b,P),只有在查询执行时,才能完全了解输入关系R的格式(列数、它们的类型和tuple的偏移量),b表示bool类型的select过滤表达式,P表示投影表达式(用于定义output relation)。为了能够处理各种类型的R、b、P,DBMS必须实现一个解释器,能够处理任意复杂度的表达式。 采用这种解释执行方式,存在一个弊端,特别是解释的粒度是一个tuple,对于一个查询执行的cost来说,真正的实际工作cost可能占的比重很小,例如Q1查询中+、-、、sum、avg计算实际的cost占比可能很低。以MySQL 4.1 TPCH query1(1s)为例进行说明,查询结果的gprof trace见表2。表2表示,Q1查询中+、-、、sum、avg计算实际的cost占整个查询的cost比重不到10%,整个query 的IPC为0.7,低。

- cum字段表示func执行的累计时间
- excl字段表示func执行自身代码(去重掉func调用其他func的代码)耗时占cum的比例
- calls字段表示func在整个查询中的调用次数
- ins字段表示每次调用时发生的平均指令数
- ipc字段表示每次调用时发生的平均IPC
观察表2 ,
- 黑色加粗条目表示query1中5个(+、-、、sum、avg)实际计算函数的执行时间等信息,+、-、、sum、avg等5个实质计算函数耗时不到总耗时的10%
- query1总耗时中,28%用于创建和lookup hash表,hash表用于agg
- query1总耗时中,剩余62%用于rec_get_nth_field等辅助函数,rec_get_nth_field用于从tuple中读取、输出指定column value、
再观察表2,表2的结果是在MIPS R12000 CPU环境中获取的,Item_func_puls::val函数在每次+操作中需要消耗38个指令。 在MIPS R12000 CPU上,在每个cycle中,可以执行3个整型或浮点型addition指令,1个load或store指令,平均每个指令要延迟5个cycle。一个简单的算术运算符+(double src1, double src2):double,在RISC的指令如下:
- LOAD src1,reg1
- LOAD src2,reg2
- ADD reg1,reg2,reg3
- STOR dst,reg3
本代码含4个指令,其中3个是load/stor指令,占比较大,因此MIPS处理器的一个加法运算+(double src1, double src2)大概需要是3个cycles(3个LOAD/STORE)。 回到表2,Item_func_puls::val每执行一次平均38个指令,ipc为0.8,那么平均一次加操作,需要cycles = 38 / 0.8 ≈ 49。而+(double src1, double src2):double平均需要3个cycles,差异如此大! 对Item_func_puls::val这种高成本的一种解释是没有使用loop pipelining。因为MySQL每次调用的Item_func_puls::val函数时,在一个cycle中,只是串行的计算一个加法,而不是采用了pipeline模式,一个cycle中,进行一个数组的loop加法,这样编译器就不能进行loop pipelining优化。因此,加法操作由4个相互依赖的指令组成(load, load, add, store),每个指令需要等上一个指令完成才可以进行。平均一个指令延迟5个cycle,因此,一次加法就延迟了20个cycle。其余的cycle(49-20 = 29)用在了函数跳转、入栈、出栈上。 注:测试结论引自论文[CIDR 2005]MonetDB-X100 Hyper-Pipelining Query。
向量化执行引擎
基本原理
论文[CIDR 2005]MonetDB-X100 Hyper-Pipelining Query分析了解释执行的问题,即a-tuple-at-a-time往往没有利用好现代CPU,只能实现较低的IPC(instructions-per-cycle)。向量化执行采用了a-vector-at-a-time的方式,即一次处理一个bach,可以直接使用SIMD指令,通过控制好vector size充分利用cpu cache,另外也可以在代码编译的时候,让编译器能够基于loop pipeline机制,生成更容易充分利用cpu cache的机器码,从而提升cpu利用率,最终提升性能。
Hard-Coded向量化执行
论文[CIDR 2005]MonetDB-X100 Hyper-Pipelining Query中,作者以TPCH query1为例,来说明为什么向量化引擎可以提升性能。
SELECT l_returnflag, l_linestatus,
sum(l_quantity) AS sum_qty,
sum(l_extendedprice) AS sum_base_price,
sum(l_extendedprice * (1 - l_discount)) AS sum_disc_price,
sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge,
avg(l_quantity) AS avg_qty,
avg(l_extendedprice) AS avg_price,
avg(l_discount) AS avg_disc,
count(*) AS count_order
FROM lineitem
WHERE l_shipdate <= date '1998-09-02'
GROUP BY l_returnflag, l_linestatus;- TPC-H benchmark ware house数据量为1GB,可以通过Scaling Factor (SF)进行扩展。
- Query1 对lineitem表进行scan,lineitem表含有6M tuples
- Query1 对lineitem表,经select过滤后,仍会选择5.9M tuples
- 计算固定精度的decimal表达式
- 8个agg计算(4个sum、3个avg、1个count)
- 2个column和常量的减
- 1个column和常量的加法
- 3个column和column的乘法,
- GroupBy columns是2个single-char columns,仅产生4个组,因此,可以用一个小的hash表进行分组,因为lineitem tuples数量不大,1GB ware house为6M tuples,因此,都可以存在内存中,不需要额外的IO,甚至可以在CPU cache中完成hash表的访问,这样就不会出现cpu cache miss
为了了解现代CPU在类似Query 1这样的查询中可以做什么优化,作者在MonetDB中实现了一个Q1的UDF,用以获取Q1的理想的性能,作为baseline,UDF如下图

- UDF只传递给查询涉及的列
- 在MonetDB中,这些列以数组的形式存储在BAT[void,T]中,其中oid的值是从0开始递增的
- 在MonetDB中,void(virtual-oid)不进行实际存储,BAT就会以一个数组的形式出现
- 在计算中,将输入的数组用__restrict__ 修饰,告知编译器,这些指针不会指向同一数据,这样编译器就可以在编译过程中,利用cpu的loop pipelining
论文的测试结果显示,这种UDF实现(标记为“hand-coded”)将查询时间降低到惊人的0.22秒,远低于同等条件下的MySQL26,6秒。
向量化引擎
以X100: A Vectorized Query Processor为例进行说明。 X100使用了一个标准的关系代数作为查询语言。不在使用column-at-a-time风格的语言了。这样关系操作符就可以同时处理多个列(多个向量),允许在cpu cache中,一个表达式产生的向量作为下一个算子的输入,即中间结果在cpu cache中。 图6展示了TPC-H Query 1的一个简版示例,使用以下X100关系代数语法:
Aggr(
Project(
Select(Table(lineitem),<(shipdate, date('1998-09-03'))),
[ discountprice = *( -( flt('1.0'), discount),
extendedprice) ]),
[ returnflag ],
[ sum_disc_price = sum(discountprice) ])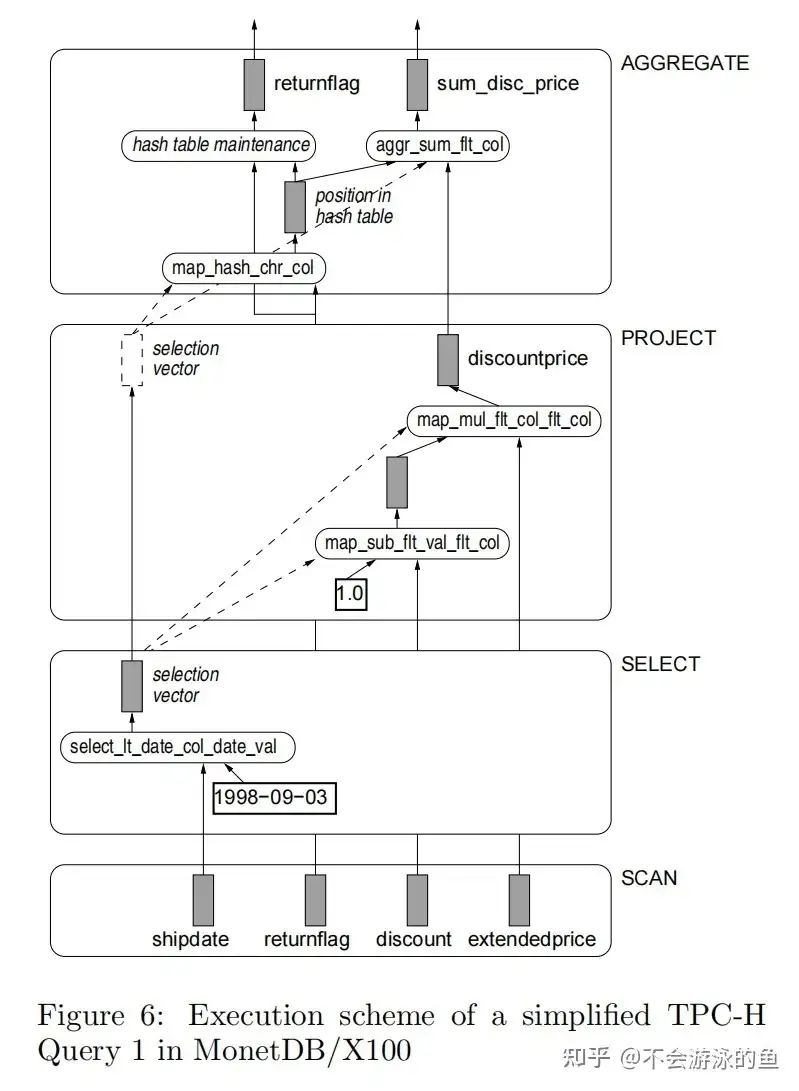
- 查询执行使用了Volcano风格的pipeline,一个vector的最小单元是1000 values
- Scan算子从Monet BATs中读取数据,vector-at-a-time,仅scan查询中使用到的column
- Select算子会创建一个selection-vector,对于scan输入的vector,执行谓词计算,将满足条件的values写入到selection-vector,注意,整个过程不会更改scan vector,而是从中选择满足条件的values,填充至新建的selection-vector
- project算子
- 计算表达式:discountprice = *( -( flt('1.0'), discount),extendedprice)
- 创建新的vector,写入discountprice
- 注意:在Select算子中并未改变“discount” column和“extendedprice”column的值
- 注意:在Select算子中,利用map-primitive(源语),对于输入的scan vector,创建同等大小且下标位置相同的Select vector,但会在select的vector中标记哪些数据是被选中的,即有效数据,后续的计算,会根据Select vector的有效数据标记,知道Select vector中哪些数据可用,因此这个Select vector会一直向上传递。
- 在project算子中,Select vector将作为筛选,从“discount” 和 “extendedprice”中筛选出满足条件的values,分别创建新的vector
- 本例中会将Select vector作为输入,传递给agg算子,用于筛选有效的数据
- agg算子,使用Select vector作为输入,基于标记为有效的values计算其在agg算子的hash 表的位置,然后使用这些数据更新agg算子的结算结果
注:map_mul_flt_col_flt_col是一种基本的计算源语,实现了两组float类型的vector的乘法计算,其他源语类似,不再赘述。 图7列出了X100当前支持的关系运算符。在X100关系代数中,Table是一个物化的relation,DataFlow是Volcano模型pipeline中的vector流,即vector-at-a-time。
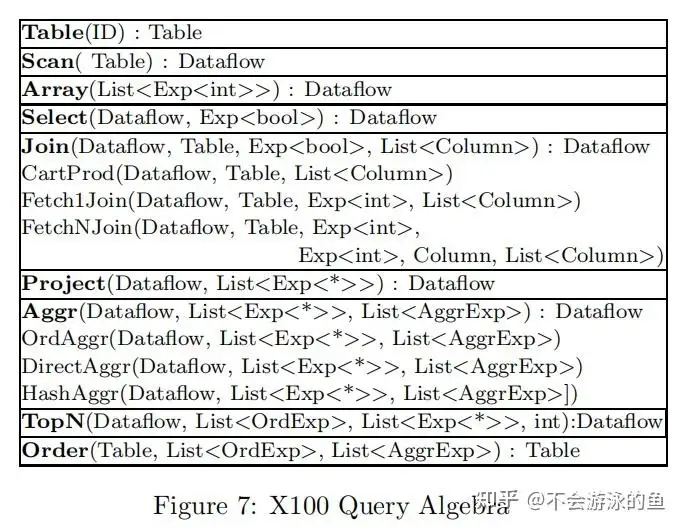
- Order、TopN、Select算子返回的dataflow的shape同其input dataflow
- 其他算子会生成新的shape的dataflow
- Project算子仅用于表达式计算,并不会去重
- 去重仅发生在Aggr算子包含group-by columns的情况下
X100使用column-wise vector layout的主要原因是,向量化执行的计算原语与解释执行相比,灵活度较低,函数每次执行时,入参都是vector,即类型是确定的(如int、double等),数组的长度是确定的,不需要关心table的布局(如record偏移信息)。这样在编译X100时,C编译器能够观察到向量化原语,即函数中使用了__restrict__修饰符,例如double*restrict col1, double*restrict col2,这样编译器就可以使用loop-pipelining进行编译优化。 例如,浮点数向量加法实现函数如下:
map_plus_double_col_double_col(
int n,
double*__restrict__ res,
double*__restrict__ col1,
double*__restrict__ col2,
int*__restrict__ sel)
{
if (sel) {
for(int j=0;j<n; j++) {
int i = sel[j];
res[i] = col1[i] + col2[i];
}
} else {
for(int i=0;i<n; i++)
res[i] = col1[i] + col2[i];
}
}- 参数sel可以为null,也可以指向一个n个元素的array,这个array是select算子中符合过滤条件的元素的index
- X100所有的向量化原语都允许传递这种的select vectors
- 其基本原理是,在select算子后,保持子操作符传递的vector的完整通常比将满足select条件的数据复制到新的(连续的)vector中更快
X100中支持数百个map_plus_double_col_double_col类似的函数,是通过模板生成的,模板如下: any::1 +(any::1 x,any::1 y) plus = x + y 此外,X100还支持组合原语,例如: /(square(-(double*, double*)), double*)
- 作者发现组合原语执行速度是单独2个原语计算的2倍
- 原因是进行了指令组合
- 向量化执行通常是load/store成对出现的,因为对于一个简单的2元计算,每一个向量化指令都需要load 2个参数,store一个计算结果,相当于4个指令,1个用于计算,2个用于load,1个用于store
- 现代CPU在一个cycle中仅能够执行1或2个 load/stroe操作
- 在组合源语中,第一个计算的结果写入cpu寄存器,用于第二个计算,这样2个计算就只有一个load和一个store,降低了成本
Vector Size 影响
论文给出了Vector Size对性能的影响。
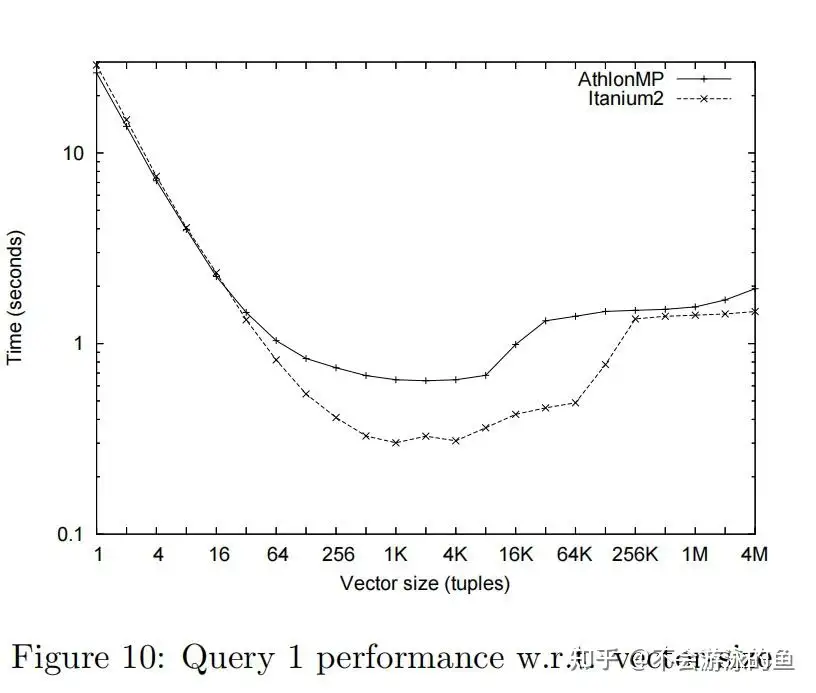
- vector size是需要根据CPU cache size进行调整的
- vector size过小,无法充分利用loop pipeling,性能不理想
- vector size过大,无法fit cpu cache,性能也不理想
SIMD优化
前面描述的都是基于高级语言方面的向量化执行引擎,这里简单介绍下基于SIMD实现的向量化引擎。 SIMD允许使用一个cpu指令操作多个数据。最初,主要用于提升多媒体处理和科学计算的性能,但也被建议用于数据库中。SIMD指令虽然具有很大的性能提升潜力,但应用到数据库中有两个重要的限制: 通常SIMD指令操作的数据必须是相同的数据类型,并且数据类型通常被限制为32/64位的整数和浮点数 在大多数ISAs中,SIMD write/load指令通常没有scatter/gather 功能,这使得SIMD仅能用于顺序处理数据 解决方案
- 对于限制1,一种解决方案是,转换column的数据类型,例如将char转换为int,或将fload转换为double。
- 对于限制2,一种解决方案是,使用如下的数据结构
- 左侧中,类似DSM格式,一次SIMD同时处理attrA[1024]、attrB[1024]、attrC[1024]、attrD[1024]
- 右侧中,类似NSM格式,一次SIMD同时处理一个data[1024],相当于一次SIMD同时处理多个行存的tuples,这些tuples之间无依赖关系,感觉原理同在pipeline中tuples-at-a-time
struct int_vec4 { struct int4 {
int attrA[1024]; int attrA;
int attrB[1024]; int attrB;
int attrC[1024]; int attrC;
int attrD[1024]; int attrD;
}; };
int_vec4 data; int4 data[1024];另外,论文[SIGMOD 2015]Rethinking SIMD Vectorization for In-Memory Databases基于先进的SIMD指令,例如gathers和scatters,提出了一种新的向量化执行引擎,并给出了selection scans、hash tables、partition的向量化实现代码,在这些基础上,实现了sort和join等算子。详细内容见[SIGMOD 2015]Rethinking SIMD Vectorization for In-Memory Databases--学习笔记。 注:论文作者来自哥伦比亚大学和Oracle
编译执行引擎
基本原理
Thomas Neumann教授(HyPer数据库的初始人之一)在[VLDB 2011]Efficiently Compiling Efficient Query Plans for Modern Hardware中提出,随着内存硬件的进步,查询性能越来越取决于查询处理本身的原始CPU成本。经典的火山迭代器模型虽然技术非常简单和灵活,但由于缺乏局部性(locality)和频繁的指令错误预测,在现代cpu上的性能较差。过去已经提出了一些技术,如面向批处理的处理或向量化tuples处理策略来改善这种情况,但即使是这些技术也经常被hand-written计划执行。 这篇论文提出了一种新的编译策略,它使用LLVM编译器框架将查询转换为紧凑而高效的机器代码。通过针对良好的代码和数据局部性和可预测的分支布局,生成的代码经常可以与手写的C++代码相媲美。将这些技术已经集成到HyPer数据库系统中,获得了很好的查询性能,而只需要增加适度的编译时间。 论文认为,基于关系代数的operator对于查询的推理非常有用,但在查询处理本身过程中展示操作符结构并不一定最好。为了利用hand-coded代码(基于cpu cache)和vectorized方式的优点,论文提出了一种在与现有方法的几个重要方法不同的查询编译策略:
- 以数据为中心进行查询处理,而不是以operator为中心。对数据进行处理后,尽可能的长时间将数据保存在CPU寄存器中,为了实现这个目标,论文模糊了operator间的调用边界
- 数据流采用了push模型,而不是pull模型,因为push模型具有更好的代码和数据locality(局部性)
- 使用 LLVM 编译框架,将查询编译成 native machine code,也就是一种机器码
编译执行框架
论文为查询的编译、执行提出了一个非常不同的架构。为了最大程度的提升查询处理性能,论文认为必须要确保代码和数据的局部性(locality),这样才可以最大程度的发挥CPU pipeline机制的性能优势。论文定义了pipeline-breaker和full pipeline breaker,以便于后续的描述。
- pipeline-breaker:如果一个operator,在处理其input tuples时,只要将其中的一个tuole从register(寄存器)取出,存入内存中,那么,这个operator就是pipeline breaker。
- full pipeline breaker:如果一个operator在处理其input tuples前,会materialize(物化)所有tuples,那这个operator是full pipeline breaker
论文认为,关于pipeline-breaker和full pipeline breaker的定义有点简单,因为单个tuple可能过大,导致无法存入CPU寄存器,但现在假设有足够数量的寄存器来容纳所有输入属性。论文在后面会更详细地讨论这个问题。论文认为将数据溢出到内存是一个pipeline-breaker操作。在查询处理期间,所有数据都应尽可能长时间地保存在CPU寄存器中。 现在的问题是,如何组织查询处理,从而使数据能够尽可能长时间地保存在CPU寄存器中?
- 经典iterator模型明显不行,因为tuple时通过next函数传递的,这种通过函数调用的方式传递数据肯定会导致数据从寄存器中的换入换出,发生pipeline-breaker
- block-oriented 执行模型虽然next函数调用次数大大减少,但也发生了pipeline-breaker,因为一个block的tuples超出了寄存器的存储空间
- 事实上,iterator模型采用了pull模式从下级算子中获取数据,无论怎么改进都有pipeline-breaker的风险。因为,iterator模型提供了迭代器基类,所有算子都需要实现这个类,为输出提供一个线性化的访问接口。
有时operator可能仅产生少量的输出tuples,这时是可以保存在寄存器中的,而不需要复制到内存或物化。 论文使用了push模型,反转了数据流向,执行计划树上的算子不再是自上而下pull数据,而是自下而上push数据。当push数据时,push进行到下一个pipeline-breaker结束。这样,数据总是从一个pipeline-breaker被push到了下一个pipeline-breaker。而一个pipeline-breaker可能会经历多个相邻的上下级算子(也可以理解为在执行计划树上存在父子关系的算子)之间,这些算子处理的tuple都在寄存器中,减少了memory access的次数,使得计算代价非常低。此外,基于push模型的架构中,更趋向于将复杂的控制流指令放置于cpu tight loop之外,这样可以降低寄存器的压力。由于pipeline-breaker终究会物化tuples,也就是将tuples从寄存器中copy到cpu缓存、内存、磁盘IO,具体根据数据量而定,但通过这种方式最小化了查询执行的memory access的次数。 这里解释下什么是CPU的 tight loop
- 使用汇编语言进行计算,一个loop中包含了很少的指令但会迭代很多次
- 这种循环计算过程中,会产生大量的IO或CPU消耗,且无法与操作系统中运行的其他程序充分共享资源
- 例如,for (unsigned int i = 0; i < 0xffffffff; ++ i) {}
示例说明见图3,其中Γ表示GroupBy算子。
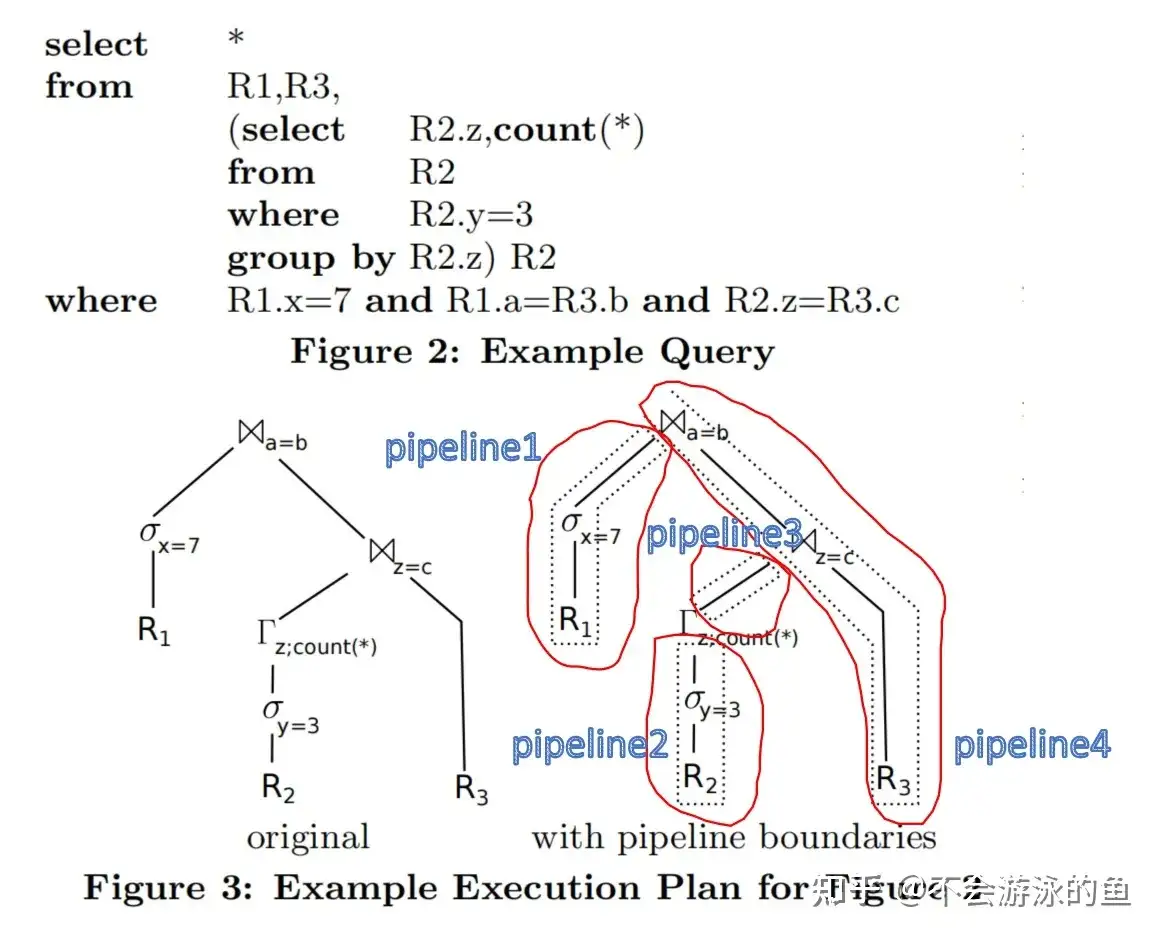
上图中,左侧表示一个常规的执行计划树,右侧表示按照pipeline-breaker切分后的执行计划树。
- 左侧图中
- 从R2中select一些tuples,然后GroupBy z,然后使用groupby的结果与R3进行join,然后再和R1的结果进行join。
- 实现中采用了经典的operator模型,最上面的join将生成最终结果。首先,重复的向其left input pull数据,构建hash表,并将pull到的tuples存入hash表中;然后从其right input中pull数据,使用right tuple取hash表probe,如果满足,则执行join并输出结果。最上层的join的left input和right input采用类似的方式,递归向其input pull数据。
- 分析本例中的数据流向,可以看出,原则上,tuples是从一个物化点转移到了另一个物化点。例如,在join a = b节点中,对于a的tuples采用了hash表进行物化。b中的数据也是经历了几次物化,如,对R2的tuples过滤后物化到一个hash表中(hash aggregation)
- 右侧图中
- 右侧表示按照pipeline-breaker切分后的执行计划树,右侧被拆分成4个部分,每个部分都是pipeline模式的,在pipeline内tuples是不需要物化的,即数据都在寄存器中,pipeline之间存在pipeline-breaker,即需要对tuples进行物化,例如pipeline1和pipeline4。
按照图3右侧的方式,必须在某个时候物化tuples,如本例中的3个pipeline-breaker,pipeline1和pipeline4、如pipeline3和pipeline4、如pipeline2和pipeline3,因此论文建议以一种编译方式执行查询,即所有pipeline操作都纯粹在CPU中执行(即,没有物化),查询以pipeline-breaker之间的pipeline为单位执行。 图3右侧相应的伪代码如下:
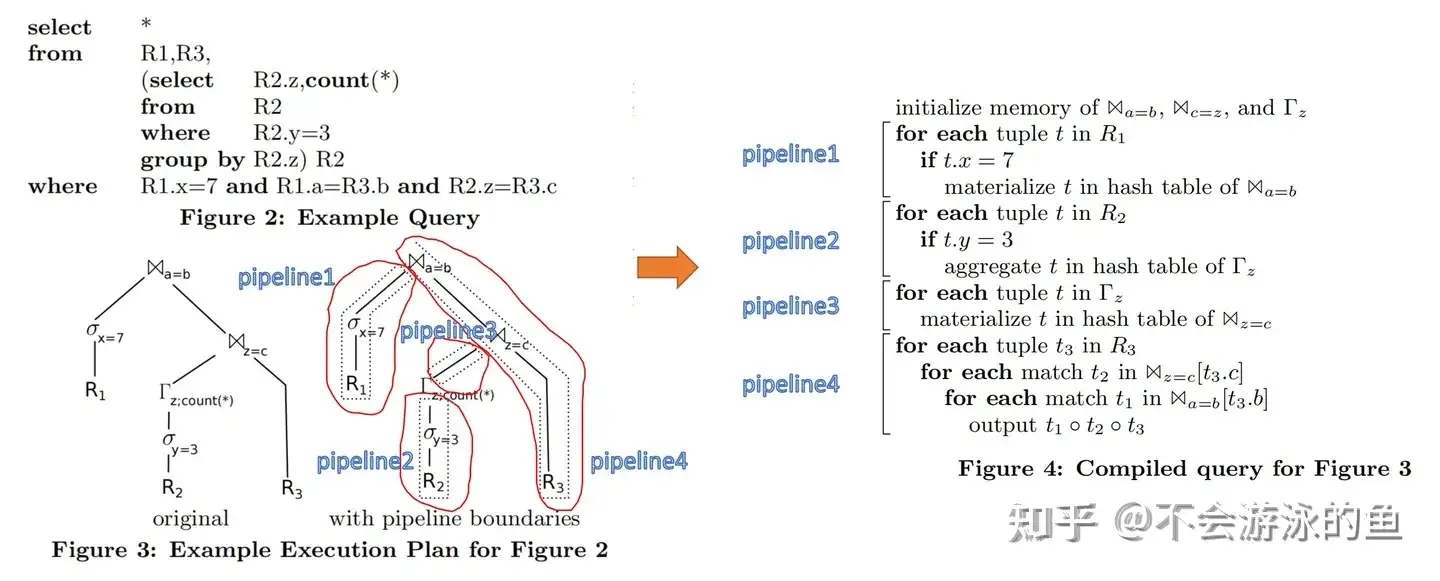
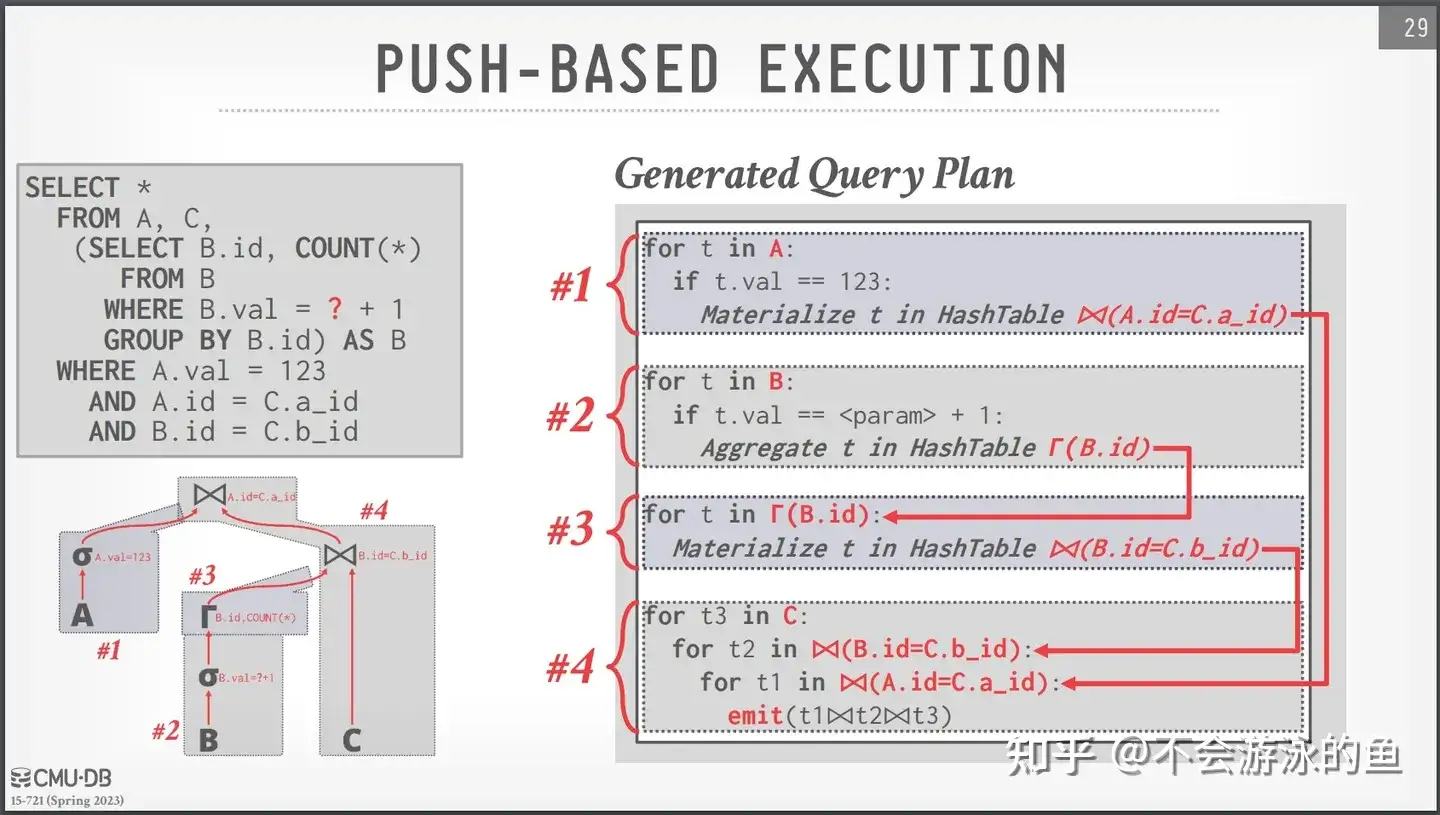
从图4中可以看出,使用了4段代码片段对应了图3右侧的4个pipeline。图3中原始的通过递归的pull模型执行方式,在这里变成了4个独立的pipeline单元,这些pipeline单元(pipeline1-pipeline4)存在生产者消费者关系,可以以一种类似于CPU流水线的方式执行。因此,每个pipeline内的代码和数据都具有良好的locality(局部性)。局部性原理是,CPU访问存储器时,无论是存取指令还是存取数据,所访问的存储单元都趋于聚集在一个较小的连续区域中。pipeline模式的良好的局部性可以更好的发挥CPU的多级Cache、分支预测等能力,使程序运行的更快。 下图是cmu15732对图4的更形象的描述,箭头表示了数据的push方向。
编译关系代数表达式
从图4pipeline1-pipeline4的代码片段中,可以看出,一个片段内执行的操作不仅限于一个operator,例如pipeline1中涉及了scan R1、selection x=7、join中建立hash表,这些算子操作的数据都是在一个pipeline-breaker内(数据位于CPU寄存器中)的,也就是说,查询执行的代码片段不以operator为中心(operator-centric),而是以数据为中心(data-centric)。每个代码片段,pipeline1-pipeline4,都可以在一个execution pipeline中执行所有的算子,然后将这个片段计算得到的结果物化,传递给下一个pipeline breaker。原来的单个operator的执行逻辑很可能会分散于多个pipeline代码片段中,例如顶层的join(a=b)中,构建a的hash表分散在pipeline1中,用right input probe hash表发生在pipeline4, 将一个执行计划树,按照pipeline进行组织,每个pipeline中涉及多个operator,这种方式pipeline内的代码是复杂的,那么如何才能将执行计划树拆分成若干个pipeline,又如何才能简化pipeline内的代码逻辑呢? 为了解决这个问题,论文认为,从查询编译器的角度来看,采用pipeline模式的所有的operators,都应该提供类似于迭代器模型的简单的接口。从概念上讲,每个operator都提供了两个标准接口:
- produce() :从下层operator中索要数据,然后调用上层算子的consume接口,将数据push给上层算子
- consume():对下层operator push来的数据,执行本算子的处理逻辑,并将处理结果push给本算子的上层算子的consume()函数
示例说明如下:
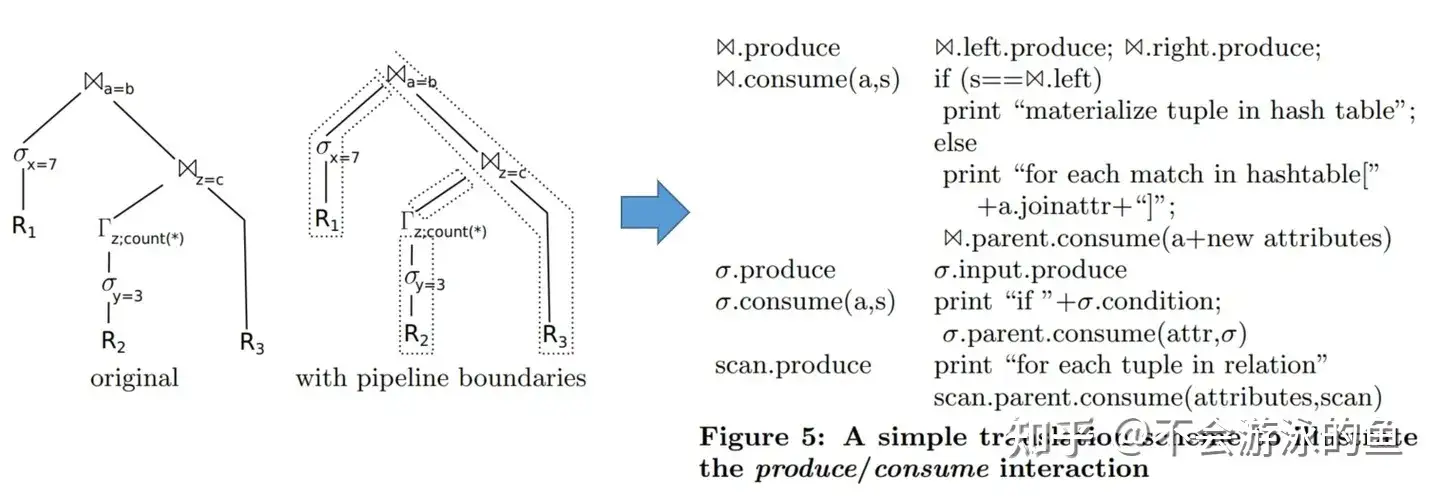
- 执行计划树从⋈(a=b).produce开始,调用⋈(a=b).left.produce
- ⋈(a=b).left.produce调用σ.produce
- σ.produce 调用 σ.input.produce
- σ.input.produce调用scan.produce,σ.input就是scan R1,σ.input.produce,就是 scan R1.produce,实际上就是对R1执行scan
- scan.produce中
- scan R1的tuples
- 对于每个tuple,调用scan.parent.consume(),即σ.consume()
- σ.consume(),对于从scan.produce中获取的tuple,执行if x== 7判定,满足条件,则执行σ.parent.consume(),即⋈(a=b).consume,否则过滤掉
- ⋈(a=b).consume,从步骤6调入本步骤时,hash表为空,则基于R1的tuples创建hash表,当来所有来自R1的tuples都写入hash表后,调用⋈(a=b).right.produce
- ⋈(a=b).right.produce调用⋈(z=c).right.produce获取结果集,然后调用⋈(z=c).right.parent.consume(),即⋈(a=b).consume,走else分支,执行probe
- 步骤8完成"for each match in hashtable..."后,调用⋈.parent.consume()将数据返给用户
上述逻辑的概述如下:
- ⋈(a=b).produce => ⋈(a=b).left.produce => σ.produce => scan.produce,scan是叶节点 ,直接从R1中获取数据
- scan.produce => σ.consume() => ⋈(a=b).consume,基于R1的tuples构建hash表,完成R1的所有tuples构建hash表后,进入步骤3
- ⋈(a=b).right.produce => ...,方式同2
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ 当编译器处理这样的query,通过produce中描述的执行依赖关系以及算子是否是pipeline-breaker的特性,它就可以把Join左侧各个算子的consume部分串联起来,形成一个scan -> select -> build hash的流水线。这2个接口只被编译器用来做动态编译。 注:为了方便理解,可以把produce想象成“函数调用”,而consume想象成“函数实现 + return 结果”,这样等于是告诉了编译器**函数间的调用逻辑,以及每个函数的具体实现!*编译器看到这些就和看到我们编写的code没啥区别,正常编译即可。 func1 { / consume描述 / .... func2() return到func0 } func2 { / consume描述 */ .... func3() return到func1 } func3 { ... } 整体流程: func0 -> func1 -> func2 ... 注:------------线之间的内容直接引自https://zhuanlan.zhihu.com/p/378198199 ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ 详细介绍见[VLDB 2011]Efficiently Compiling Efficient Query Plans for Modern Hardware --学习笔记
CRDB执行引擎
以下使用表People(Id,Name,Age)为例进行说明。在Volcano执行引擎中,采用了row-by-row的方式,一次处理一个row。在向量化执行引擎中,一次处理一个batch的column data,每个向量化函数,仅处理特定类型的column的数据类型。本例中,Id是一个int型array,Name是bytes型array,Age是int类型array。这两种数据模型如下:
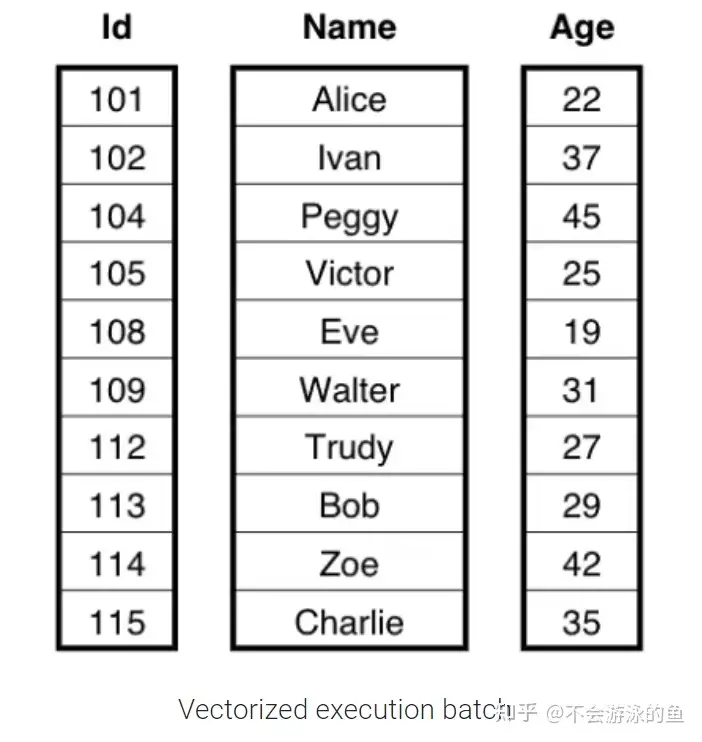
查询SQL如下: SELECT Name, (Age - 30) * 50 AS Bonus FROM People WHERE Age > 30
Volcano执行引擎
示例sql的执行计划中,CRDB最下层的算子是scan,用于从People表中扫描数据,最上层的算子是Project,用于向用户返回数据。整个过程如下:
- scan算子:从People表的kv 存储层读取一个row,然后传递给select算子
- select算子:检查传递过来的row是否满足过滤条件 Age>30,如果通过检查,则将row传递给project算子
- project算子:执行Bonus = (Age - 30) * 50,用于输出给用户
注:这里只是一个简单的示例,实际中,会根据where条件,scan可能满足条件的kv存储单元。
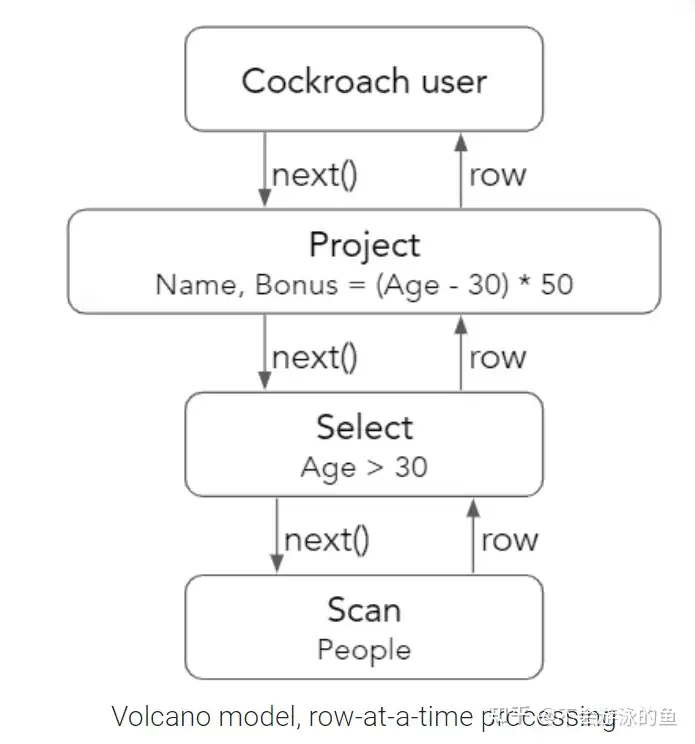
聚焦到select算子,实现代码同其他DBMS差异不大。Select算子会向其子算子(Scan算子)请求next row,并检查其是否满足过滤条件,如果满足则返回给其父算子。如果不满足过滤条件,则丢弃这个row。直至返回EOF。
func (f *filterNode) Next(params runParams) (bool, error) {
for {
if next, err := f.source.plan.Next(params); !next {
return false, err
}
passesFilter, err := sqlbase.RunFilter(f.filter, params.EvalContext())
if err != nil {
return false, err
}
if passesFilter {
return true, nil
}
// Row was filtered out; grab the next row.
}
}这段代码对于每一行数据都要调用一个完全通用的标量表达式过滤器!这个表达式可以是任意的,例如 乘法、除法、等值检查、内置函数等,甚至可以是一个很长的表达式树。由于这种通用性,计算机需要在每一行数据上做很多工作,它必须先检查表达式的类型,然后才能开始工作,其实就是有一个虚函数实例化的过程。这就是解释性语言相对于编译性语言所面临的劣势。 注:本段内容来自CRDB的19年的博客,目前已经在volcano引擎中进行了优化,支持一次一个batch rows。
向量化执行引擎
向量化执行模型的理念是在执行过程中不允许使用虚函数,各种类型都是明确的。这需要对任何task、数据类型和属性的组合,都应该有一个单独的算子来负责工作。在上例中,用户请求一个batch的数据,每个算子从其子节点请求一个batch的数据,执行特定的任务,然后将一个batch的数据返回给其父节点。
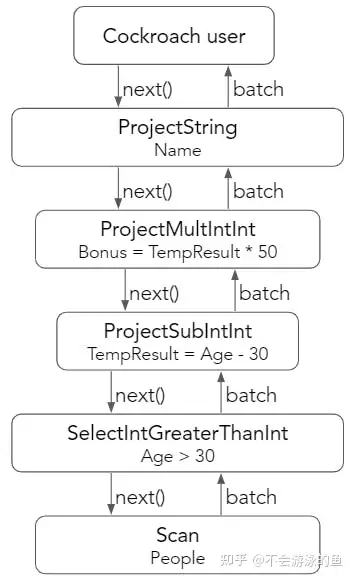
从上图中,可以看出每个算子都明确了数据类型,说明如下:
- SelectIntGreaterThanInt,要求input的column类型是int,比较的value(30)类型也是int,这个算子是获取Age中比30大的集合,即sel_age batch,然后将其发送给ProjectSubIntInt 算子
- ProjectSubIntInt 算子仅负责执行减法,结果放置于tmp batch中,然后传递给ProjectMultIntInt 算子
- ProjectMultIntInt 算子执行乘法,这样完成了最终的Bonus = (Age - 30) * 50 计算
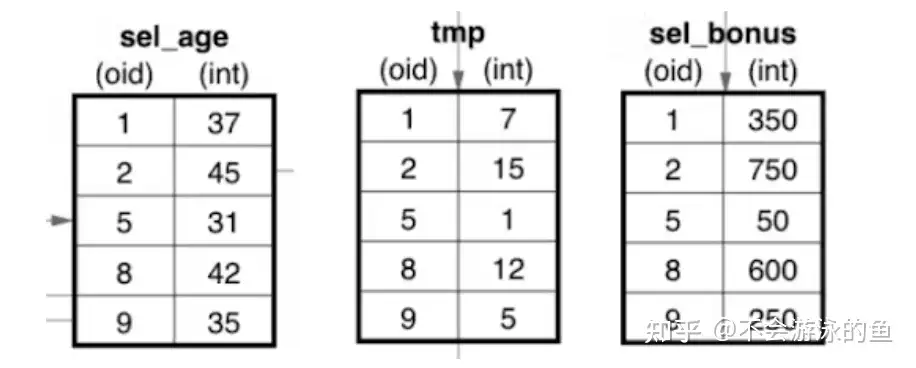
为了实现一个向量化算子,需要将原来的tuple-at-a-time的处理过程分解成对单个列的紧密小循环。代码片段实现了SelectIntGreaterThanInt操作符。该函数从其子节点中检索一个batch,并循环遍历列中的每个元素,将大于30的值标记为已选。然后将这个原batch及其选择向量(sel batch)返回给父算子进行进一步处理。sel向量中记录了scan算子输出的原始向量中满足过滤条件的元素的下标集合。
func (p selGTInt64Int64ConstOp) Next() ColBatch {
for {
batch := p.input.Next()
col := batch.ColVec(p.colIdx).Int64()[:ColBatchSize]
var idx uint16
n := batch.Length()
sel := batch.Selection()
for i := uint16(0); i < n; i++ {
var cmp bool
cmp = col[i] > p.constArg
if cmp {
sel[idx] = i
idx++
}
}
}
}selGTInt64Int64ConstOp函数代码简洁,并且高效。代码段中有一个 for 循环,它迭代一个 Go 语言原生的 int64 切片,将每个元素与另一个常量 int64 进行比较,并将结果存储在另一个 Go 语言原生的 uint16 切片中。这个循环非常简单、快速,基本上可以是 Go 这样的语言中编写出最简单和最快的循环了。
CRDB Hash Join向量化实现
传统的hash join实现
示例sql如下
SELECT customers.name, orders.age
FROM orders
JOIN customers
ON orders.id = customers.order_id
AND orders.person_id = customers.person_id| Left input | Right input | |
|---|---|---|
| Table | orders | customers |
| Equality key | (id, person_id) | (order_id, person_id) |
| Output columns | [age] | [name] |
hash join是等值join的一种实现算法,算法的简单说明如下:
- 选择一个数据量小的表作为build table,也就是用于构建hash表
- Build phase:基于build table的hash join等值列构建hash表,为每个row计算一个hash值
- Probe phase:对每个probe table的row,采用相同的hash函数,计算hash值,然后从build table的hash表中进行查找,如果key匹配,则返回两个row的join结果
向量化hash join
simple bucket-chained hash-table
CRDB使用了simple bucket-chained hash-table实现hash join,算法过程如下:

- input values数组:join column 的values数组
- fist数组:hash桶
- 数组下标是桶的序号,input values经过hash函数能够映射到这个下标
- 数组下标对应的value指向next数组的下标
- input数组的values可能会指向同一个first数组的下标
- next数组:下标相当于一个链表,表示hash table中的bucket chain关系
- 0表示链表的末尾
- >=1 表示链表中下一个元素在next数组中的下标
- values[0]数组:表示next数组表示的链表中的元素的input value值,一一对应
CRDB实现了论文**Balancing Vectorized Query Execution with Bandwidth-Optimized Storage**中提出的hash join向量化算法。该算法的解决的挑战是,将hash join分解为一系列简单的循环,每个循环只涉及单个列,并尽可能少地使用运行时run-time decisions, if statements 和 jumps。
build phase
算法伪代码如下:
// Input: build relation with N attributes and K keys
// 1. Compute the bucket number for each tuple, store in bucketV
for (i = 0; i < K; i++)
hash[i](hashValueV, build.keys[i], n); // type-specific hash() / rehash()
modulo(bucketV, hashValueV, numBuckets, n);
// 2. Prepare hash table organization, compute each tuple position in groupIdV
hashTableInsert(groupIdV, hashTable, bucketV, n)
// 3. Insert all the attributes
for (i = 0; i < N; i++)
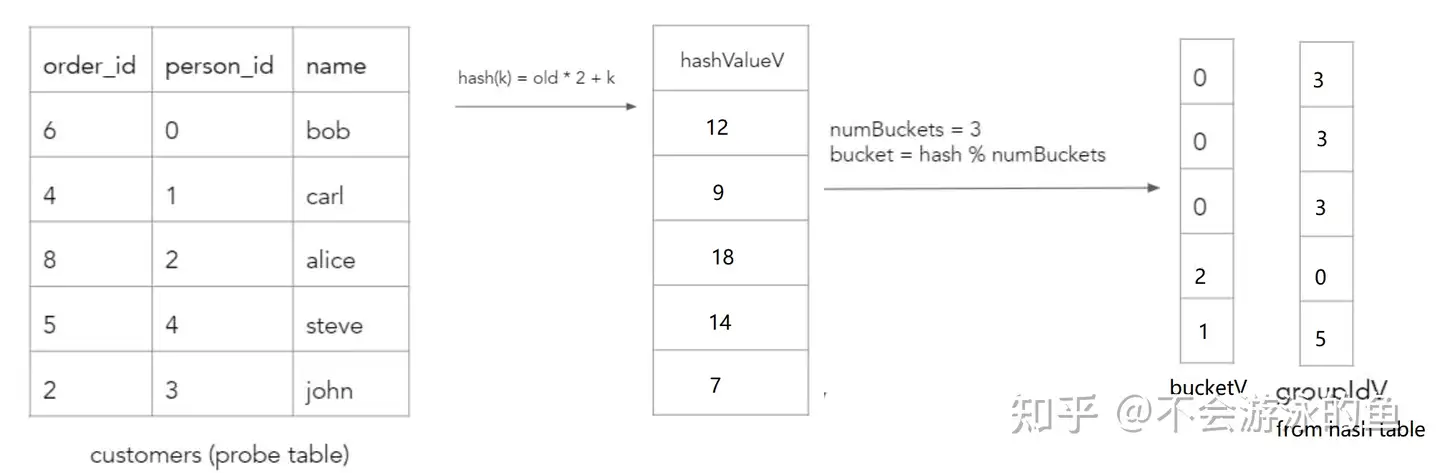
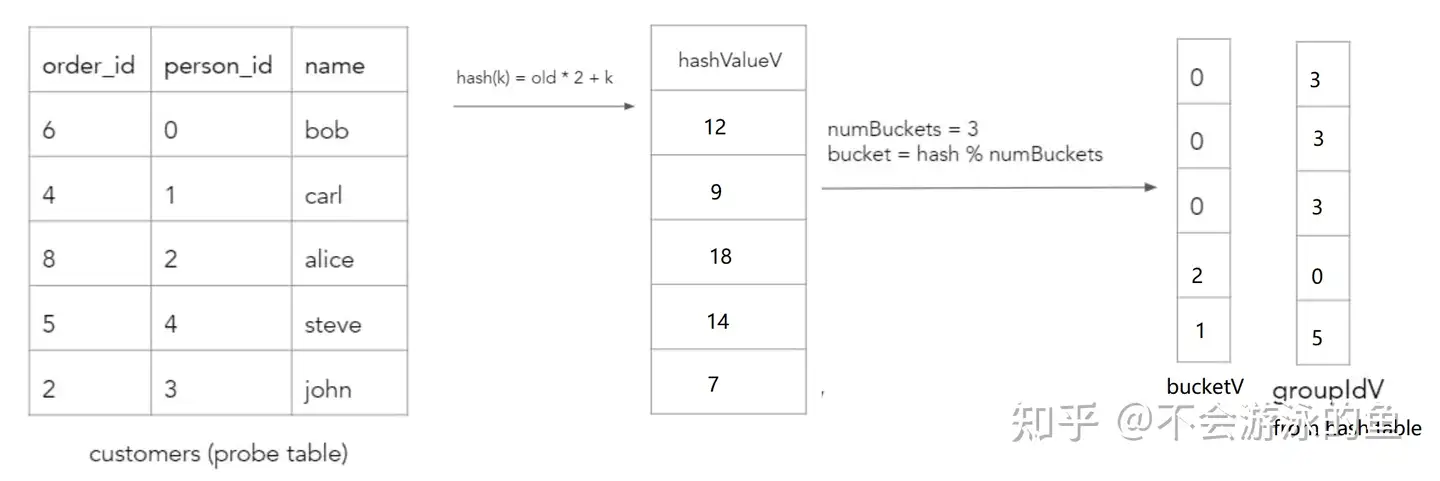
spread[i](hashTable.values[i], groupIdV, build.values[i], n);build阶段的第一个任务就是为每个build tuple计算hash桶序号。为了支持多columns的hash join,build阶段分解为如下步骤:
- 计算hashValueV向量,使用hash*(例如,hash_slng)原语input 参数 为第一个hash join column vector
- 调整hashValueV向量,使用rehash*原语,输入为hashValueV向量和下一个hash join column vector,通过hash函数计算新的hash值,存入hashValueV向量,对后续的hash join column vector重复此过程
- 计算bucketV vector,使用modulo原语,计算hashValueV中每个value对应的bucket值,存入bucketV vector
回到本节的示例:
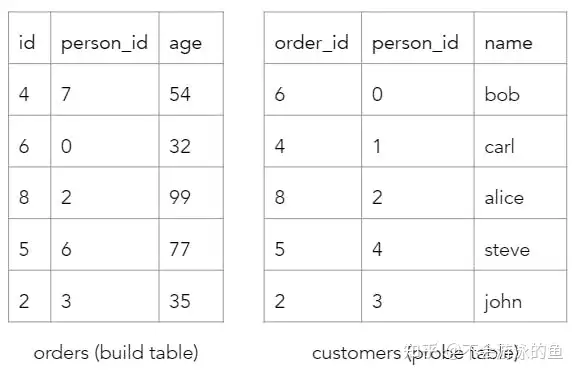
首先,计算hash值 CRDB会计算build表的每个row的hash值,通过对每个等值比较column进行循环并执行哈希来计算的,其实就是用第一个字段计算一次hash值,然后作为输入,和第二个字段进行计算,得到第二次hash值,直至所有join字段全部完成计算。示例过程如下,其中k是当前字段的value,old是基于前一个字段计算出的hash值,初始为0:
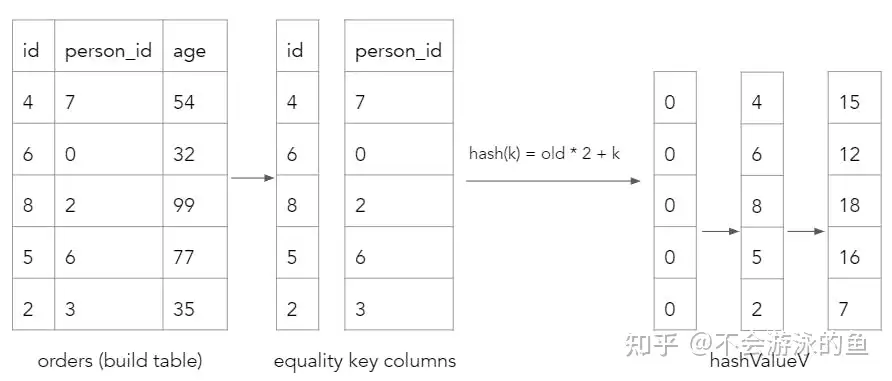
然后,对hashValueV array采用再进行一次hash计算,得出每个value所在的hash bucket位置。本例中,设定buckets数量为3。
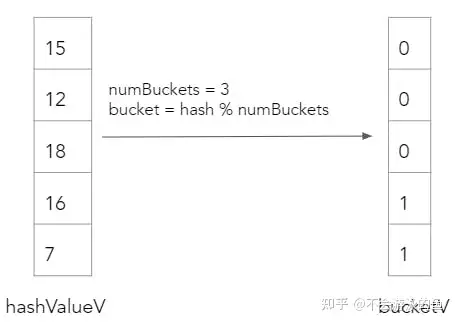
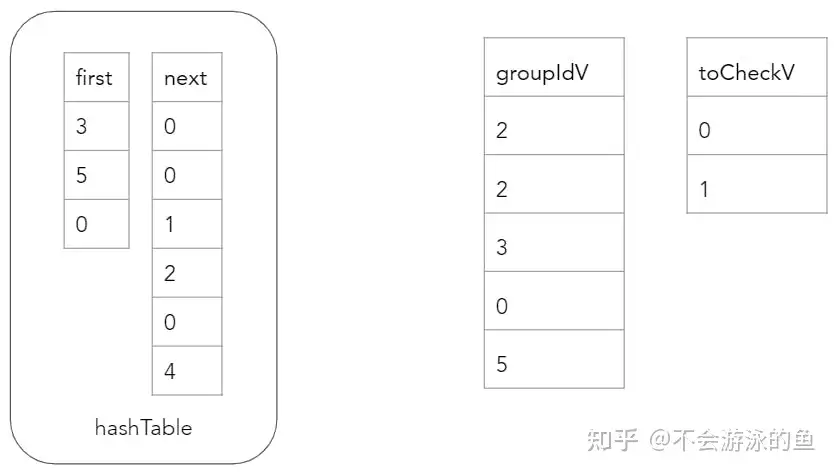
第二步,构建hash表的key 基于这个bucketV,就可以调用hashTableInsert原语构建hash表了,即将build table的rows插入到这个hash表对应的bucketV中,这里采用了链表的方式解决hash冲突。同时,也会创建groupIdV 向量,用来记录每个tuple在hash表中的位置
hashTableInsert(groupIdV, hashTable, bucketV, n) {
for (i = 0; i < n; i++) {
groupIdV[i] = hashTable.count++;
hashTable.next[groupIdV[i]] = hashTable.first[bucketV[i]];
hashTable.first[bucketV[i]] = groupIdV[i];
}
}groupIdV 向量记录了bulld table row的唯一ID,示例如下:
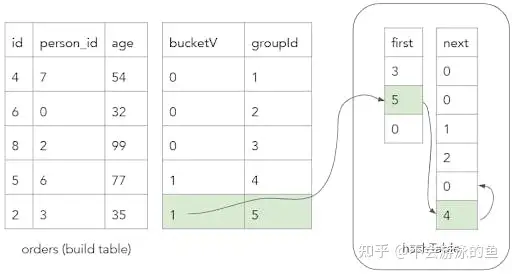
这个图很好理解,id为2和5的两个row,位于一个hash桶内,在first中,记录了最新的row,即groupid为5,其next是groupid为4的row,因为只有2个,因此其next为0,表示无。 最后,为hash表的每个key写入values 使用spread函数,向hash表hashTableValues的key中插入values(其他属性字段的值)。
spread(hashTableValues, groupIdV, inputValues, n) {
for (i = 0; i < n; i++)
hashTableValues[groupIdV[i]] = inputValues[i];
}probe phase 算法伪代码如下:
// Input: probe relation with M attributes and K keys, hash-table containing
// N build attributes
// 1. Compute the bucket number for each probe tuple.
// ... Construct bucketV in the same way as in the build phase ...
// 2. Find the positions in the hash table
// 2a. First, find the first element in the linked list for every tuple,
// put it in groupIdV, and also initialize toCheckV with the full
// sequence of input indices (0..n-1).
lookupInitial(groupIdV, toCheckV, bucketV, n);
m = n;
while (m > 0) {
// 2b. At this stage, toCheckV contains m positions of the input tuples for
// which the key comparison needs to be performed. For each tuple
// groupIdV contains the currently analyzed offset in the hash table.
// We perform a multi-column value check using type-specific
// check() / recheck() primitives, producing differsV.
for (i = 0; i < K; i++)
check[i](differsV, toCheckV, groupIdV, hashTable.values[i], probe.keys[i], m);
// 2c. Now, differsV contains 1 for tuples that differ on at least one key,
// select these out as these need to be further processed
m = selectMisses(toCheckV, differV, m);
// 2d. For the differing tuples, find the next offset in the hash table,
// put it in groupIdV
findNext(toCheckV, hashTable.next, groupIdV, m);
}
// 3. Now, groupIdV for every probe tuple contains the offset of the matching
// tuple in the hash table. Use it to project attributes from the hash table.
// (the probe attributes are just propagated)
for (i = 0; i < N; i++)
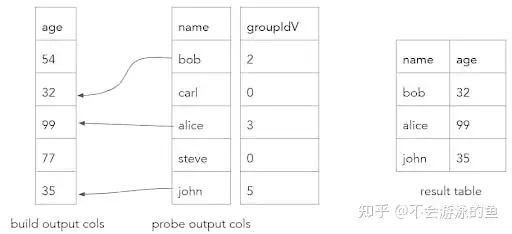
gather[i] (result.values[M + i], groupIdV, hashTable.values[i], n);哈希连接算法probe阶段的目标是在build hash表中查找probe表中每一行的等值键,如果找到,则构造匹配行的结果输出。为了实现这一目标,需要计算probe表每个row的bucket位置,并跟随build hash表中相应的桶链,直到找到匹配项或到达链表的末尾。
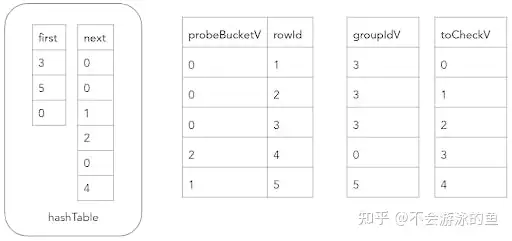
哈希连接probe阶段的下一步是,需要验证probe表中每个row的等值键是否与对应的build hash表groupIdV值所代表的row的等值键相等。如果不相等,则需要将该probe表中row的索引重新加入到toCheckV数组中,并将其对应的groupIdV值更新为同一桶链中的next值。 在向量化的方式下,需要将这个过程分解成几个简单的循环,以便在单个列上进行操作。lookupInitial函数使用与构建阶段相同的方法计算每个探测表键的bucketV值,并将groupIdV填充为每个桶中哈希表的第一个值,groupIdV中存放的是build table的rowid。由于不同的join key可以位于同一个哈希表桶中(由于冲突),因此还需要验证每行是否确实匹配。因此,还需要使用索引(0,...,n)填充toCheckV数组。哈希连接的更新状态如下。
probe阶段的下一步是验证probe表每个row的join key的values是否等于相应的groupIdV值所代表的build table的row的values。在第一次迭代中,
- probeBucketV为0的三个row,即customer表中(order_id,person_id)为{(6,0),(4,1),(8,2)}的三个row,分别和build table中groupIdV为3的row进行匹配,即order表(id,person_id)值为(8,2)的row进行匹配,对比结果中,probe table的rowid为3的row满足匹配条件,因此,groupIdV中第三个记录的值为3,第一个和第二个记录的值,为build table中,hash桶0中对应链表的下一个元素,即groupId值为2。此时,toCheckV为0和1。因为hash桶0的第一个元素是3,3的下一个是2,2的下一个是1,1的下一个是0
- probeBucketV为2桶中,仅有1个row,即customer表中(order_id,person_id)为(2,3),在groupIdV的对应位置为5。在build hash表中,下标为1的hash桶中,存在一个链表,即5->4->0。其中groupId为5的row中,(order_id,person_id)为(2,3),此时probe table的中probeBucketV为2的桶内所有元素都在build table中找到了匹配项,因此更新groupIdV的对应值为5,不需要在从build table的hash桶链表中进行查找,因此,无需增加toCheckV的元素
经过这个过程,hash join的状态如下:
通过哈希表匹配算法,可以将probe表中的row与build表中的row进行匹配。将probe表中的每一行哈希到相应的桶中,然后在每个桶中搜索匹配的build表rows。最终,匹配的结果会被复制到一个结果batch处理中。如果没有匹配,则结果为0。
向量化实现的优势
向量化执行是一种并行计算的技术,可以同时处理多个元素,而不是逐个处理。这种技术能够提升算法的性能,因为可以利用CPU cache、减少类型转换和条件分支,并且在需要时进行值的合并。相反,基于row的Volcano 模型需要逐行解释执行,因此对 CPU 不友好。 Cockroach 数据库的向量化hash join性能比 Volcano 模型hash join提高了约 40 倍。
Volcano model hash joiner:
BenchmarkHashJoiner/rows=16-8 13.46 MB/s
BenchmarkHashJoiner/rows=256-8 18.69 MB/s
BenchmarkHashJoiner/rows=4096-8 18.97 MB/s
BenchmarkHashJoiner/rows=65536-8 15.30 MB/s
Vectorized hash joiner:
BenchmarkHashJoiner/rows=2048-8 611.55 MB/s
BenchmarkHashJoiner/rows=262144-8 1386.88 MB/s
BenchmarkHashJoiner/rows=4194304-8 680.00 MB/s小结
CRDB在实现向量化执行引擎中,采用了vector-at-a-time方式,在执行过程中不允许使用虚函数,各种类型都是明确的,对任何task、数据类型和属性的组合,都会有一个单独的函数来负责。这样,可以依赖编译器,在编译优化阶段,能够利用loop pipeline机制,生成更容易充分利用cpu cache的机器码,从而提升cpu利用率,最终提升性能。 但也存在几点不足:
- CRDB没有使用SIMD指令进一步优化性能,原因在于CRDB是go实现的,go native中使用SIMD挑战大
- CRDB存储中仍然使用了行存,在使用向量化引擎时,需要进行行转列,在结果返回给用户前,还需要完成列转行。因此,这里存在一个trade off,即根据数据量、查询的特征,动态选择执行引擎,遗憾的是CRDB目前不支持这种自适应
- 在向量化执行中,vector size的设置应该和CPU的cache相关,但目前CRDB采用了hard code方式设置的,不支持自适应
参考
- https://www.cockroachlabs.com/blog/vectorized-hash-joiner/
- MonetDB/X100: Hyper-Pipelining Query Execution
- [VLDB 2011]Efficiently Compiling Efficient Query Plans for Modern Hardware
- [SIGMOD 2015]Rethinking SIMD Vectorization for In-Memory Databases
- Balancing Vectorized Query Execution with Bandwidth-Optimized Storage