ElasticSearch基础概念
为什么需要学习ElasticSearch
排名
根据 DB Engine的排名 显示,ElasticSearch是最受欢迎的企业级搜索引擎。
ElasticSearch在前十名内:
所以为什么要学习ElasticSearch呢?
1、在当前软件行业中,搜索是一个软件系统或平台的基本功能, 学习ElasticSearch就可以为相应的软件打造出良好的搜索体验。
2、其次,ElasticSearch具备非常强的大数据分析能力。虽然Hadoop也可以做大数据分析,但是ElasticSearch的分析能力非常高,具备Hadoop不具备的能力。比如有时候用Hadoop分析一个结果,可能等待的时间比较长。
3、ElasticSearch可以很方便的进行使用,可以将其安装在个人的笔记本电脑,也可以在生产环境中,将其进行水平扩展。
4、国内比较大的互联网公司都在使用,比如小米、滴滴、携程等公司。另外,在腾讯云、阿里云的云平台上,也都有相应的ElasticSearch云产品可以使用。
5、在当今大数据时代,掌握近实时的搜索和分析能力,才能掌握核心竞争力,洞见未来。
Doug Cutting
Hadoop之父:Doug Cutting
1998年9月4日,Google 公司在美国硅谷成立。正如大家所知,它是一家做搜索引擎起家的公司。

一位名叫 **Doug Cutting **的美国工程师,也迷上了搜索引擎。他做了一个用于文本搜索的函数库(姑且理解为软件的功能组件),命名为 Lucene。

Lucene 是用 JAVA 写成的,目标是为各种中小型应用软件加入全文检索功能。因为好用而且开源,非常受程序员们的欢迎。
早期的时候,这个项目被发布在Doug Cutting的个人网站和SourceForge(一个开源软件网站)。后来,2001年底,Lucene 成为 Apache 软件基金会 jakarta 项目的一个子项目。

2004年,Doug Cutting再接再励,在Lucene的基础上,和Apache开源伙伴 Mike Cafarella 合作,开发了一款可以代替当时的主流搜索的开源搜索引擎,命名为 Nutch 。

Nutch是一个建立在Lucene核心之上的网页搜索应用程序,可以下载下来直接使用。它在Lucene的基础上加了网络爬虫和一些网页相关的功能,目的就是从一个简单的站内检索推广到全球网络的搜索上,就像Google一样。
Nutch在业界的影响力比Lucene更大。
大批网站采用了Nutch平台,大大降低了技术门槛,使低成本的普通计算机取代高价的Web服务器成为可能。甚至有一段时间,在硅谷有了一股用Nutch低成本创业的潮流。
随着时间的推移,无论是Google还是Nutch,都面临搜索对象“体积”不断增大的问题。
尤其是Google,作为互联网搜索引擎,需要存储大量的网页,并不断优化自己的搜索算法,提升搜索效率。

在这个过程中,Google确实找到了不少好办法,并且无私地分享了出来。
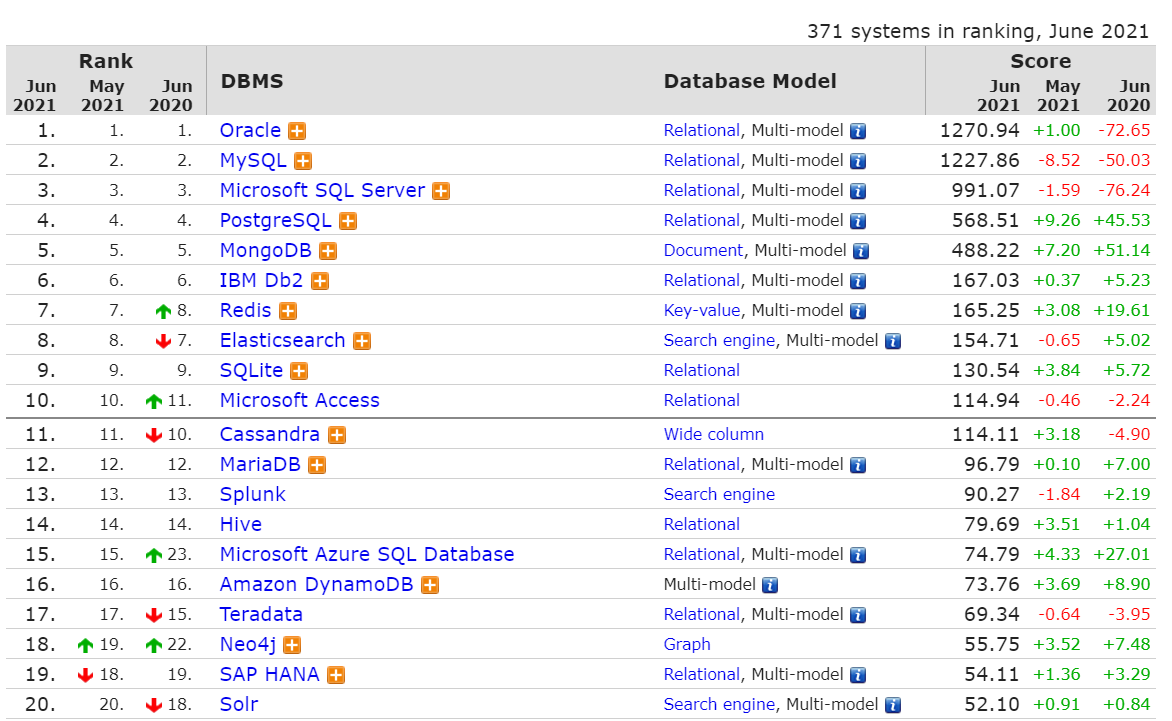
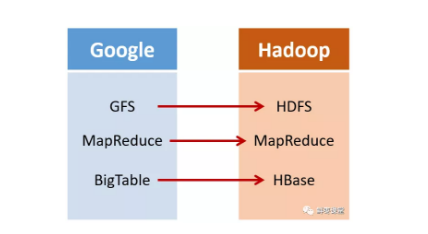
2003年,Google发表了一篇技术学术论文,公开介绍了自己的谷歌文件系统GFS(Google File System)。
这是Google公司为了存储海量搜索数据而设计的专用文件系统。
第二年,也就是2004年,Doug Cutting基于Google的GFS论文,实现了分布式文件存储系统,并将它命名为NDFS(Nutch Distributed File System)。
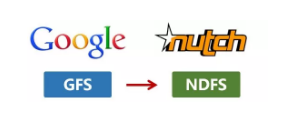
还是2004年,Google又发表了一篇技术学术论文,介绍自己的MapReduce编程模型。这个编程模型, 用于大规模数据集(大于1TB)的并行分析运算。
第二年(2005年),Doug Cutting又基于MapReduce,在Nutch搜索引擎实现了该功能。
2006年,Yahoo(雅虎)公司,招安了Doug Cutting

加盟Yahoo之后,Doug Cutting将NDFS和MapReduce进行了升级改造,并重新命名为 Hadoop(NDFS也改名为HDFS,Hadoop Distributed File System)。
这个,就是后来大名鼎鼎的大数据框架系统——Hadoop的由来。
而Doug Cutting,则被人们称为 Hadoop之父。

Hadoop这个名字,实际上是Doug Cutting他儿子的黄色玩具大象的名字。所以,Hadoop的Logo,就是一只奔跑的黄色大象。

我们继续往下说。 还是2006年,Google又发论文了。
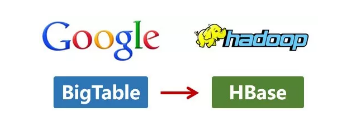
这次,它们介绍了自己的BigTable。这是一种分布式数据存储系统,一种用来处理海量数据的非关系型数据库。
Doug Cutting当然没有放过,在自己的hadoop系统里面,引入了BigTable,并命名为HBase。
好吧,反正就是紧跟Google时代步伐,你出什么,我学什么。
所以,Hadoop的核心部分,基本上都有Google的影子。
2008年1月,Hadoop成功上位,正式成为Apache基金会的顶级项目。
同年2月,Yahoo宣布建成了一个拥有1万个内核的 Hadoop 集群,并将自己的搜索引擎产品部署在上面。
7月,Hadoop打破世界纪录,成为最快排序1TB数据的系统,用时 209 秒。
Lucene
Lucene是一套信息检索工具包,并不包含搜索引擎系统,它包含了索引结构、读写索引工具、相关性工具、排序等功能,因此在使用Lucene时仍需要关注搜索引擎系统,例如数据获取、解析、分词等方面的 东西。
为什么要给大家介绍下Lucene呢,因为我们学过的 solr 和 即将要学习的 elasticsearch 都是基于该工具包做的一些封装和增强罢了
什么是ElasticSearch
ElasticSearch的由来
许多年前,一个刚结婚的名叫 Shay Banon 的失业开发者,跟着他的妻子去了伦敦,他的妻子在那里学习厨师。 在寻找一个赚钱的工作的时候,为了给他的妻子做一个食谱搜索引擎,他开始使用 Lucene 的一个早期版本。
直接使用 Lucene 是很难的,因此 Shay 开始做一个抽象层,Java 开发者使用它可以很简单的给他们的程序添加搜索功能。 他发布了他的第一个开源项目 Compass。
后来 Shay 获得了一份工作,主要是高性能,分布式环境下的内存数据网格。这个对于高性能,实时,分布式搜索引擎的需求尤为突出, 他决定重写 Compass,把它变为一个独立的服务并取名 Elasticsearch。
第一个公开版本在2010年2月发布,从此以后,Elasticsearch 已经成为了 Github 上最活跃的项目之一,他拥有超过300名 contributors(目前736名 contributors )。 一家公司已经开始围绕 Elasticsearch 提供商业服务,并开发新的特性,但是,Elasticsearch 将永远开源并对所有人可用。
据说,Shay 的妻子还在等着她的食谱搜索引擎…
谁在使用ElasticSearch
ElasticSearch是一款非常强大的、基于Lucene的开源搜索及分析引擎;它是一个实时的分布式搜索分析引擎,它能让你以前所未有的速度和规模,去探索你的数据。
它被用作全文检索、结构化搜索、分析以及这三个功能的组合:
Wikipedia 使用 Elasticsearch 提供带有高亮片段的全文搜索,还有 search-as-you-type 和 did-you-mean 的建议。
The Guardian (国外新闻网站),类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论)+社交网络数据(对某某新闻的相关看法),数据分析,给到每篇新闻文章的作者,为它的编辑们提供公众对于新文章的实时反馈(好,坏,热门,垃圾,鄙视,崇拜)
Stack Overflow 将地理位置查询融入全文检索中去,并且使用 more-like-this 接口去查找相关的问题和回答。
GitHub 使用 Elasticsearch 对1300亿行代码进行查询。
.....
除了搜索,结合Kibana、Logstash、Beats开源产品,Elastic Stack(简称ELK)还被广泛运用在大数据近实时分析领域,包括:日志分析、指标监控、信息安全等。它可以帮助你探索海量结构化、非结构化数据,按需创建可视化报表,对监控数据设置报警阈值,通过使用机器学习,自动识别异常状况。
为什么不是直接使用Lucene
Lucene简介
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具 包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。
Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。
Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。
在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
Lucene是一个全文检索引擎的架构。那什么是全文搜索引擎?全文搜索引擎是名副其实的搜索引擎,国外具代表性的有Google、Fast/AllTheWeb、AltaVista、 Inktomi、Teoma、WiseNut等,国内著名的有百度(Baidu)。它们都是通过从互联网上提取的各个网站的信息(以网页文字为主)而建立的数据库中,检索与用户查询条件匹配的相关记录,然后按一定的排列顺序将结果返回给用户,因此他们是真正的搜索引擎。
从搜索结果来源的角度,全文搜索引擎又可细分为两种,一种是拥有自己的检索程序(Indexer),俗称 “蜘蛛”(Spider)程序或“机器人”(Robot)程序,并自建网页数据库,搜索结果直接从自身的数据库中 调用,如上面提到的7家引擎;另一种则是租用其他引擎的数据库,并按自定的格式排列搜索结果,如 Lycos引擎。
ElasticSearch是基于Lucene的,那么为什么不是直接使用Lucene呢?
Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库。
但是 Lucene 仅仅只是一个库。为了充分发挥其功能,你需要使用 Java 并将 Lucene 直接集成到应用程序中。 更糟糕的是,您可能需要获得信息检索学位才能了解其工作原理。Lucene 非常 复杂。
Elasticsearch 也是使用 Java 编写的,它的内部使用 Lucene 做索引与搜索,但是它的目的是使全文检索变得简单,通过隐藏 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API。
然而,Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确的形容:
- 一个分布式的实时文档存储,每个字段 可以被索引与搜索
- 一个分布式实时分析搜索引擎
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
ES和solr的差别
Solr简介
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了 比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化
Solr可以独立运行,运行在 Jetty、Tomcat 等这些 Servlet 容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr 根据 xml 文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json 等格式的查询结果进行解析,组织页面布局。Solr 不提供构建 UI 的功能,Solr 提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
solr是基于lucene开发企业级搜索服务器,实际上就是封装了lucene。
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于 Web-service 的API接口。用户可以通过 http 请求,向搜索引擎服务器提交一定格式的文件,生成索引;也可以通过提出查找请求,并得到返回结果。
Elasticsearch和Solr比较

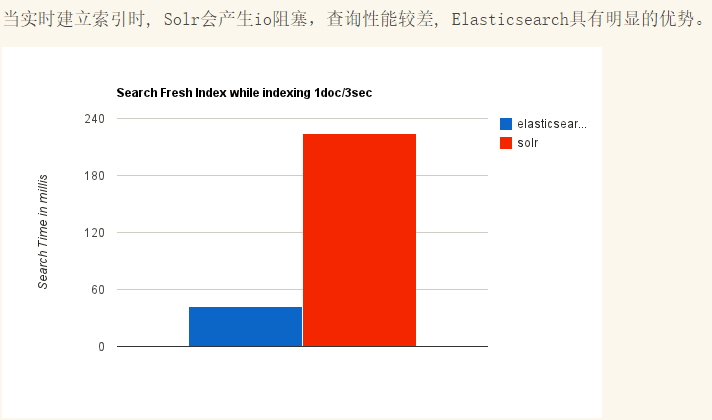
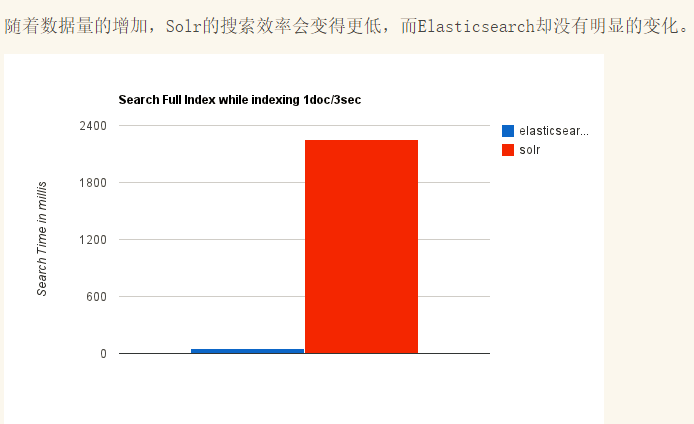
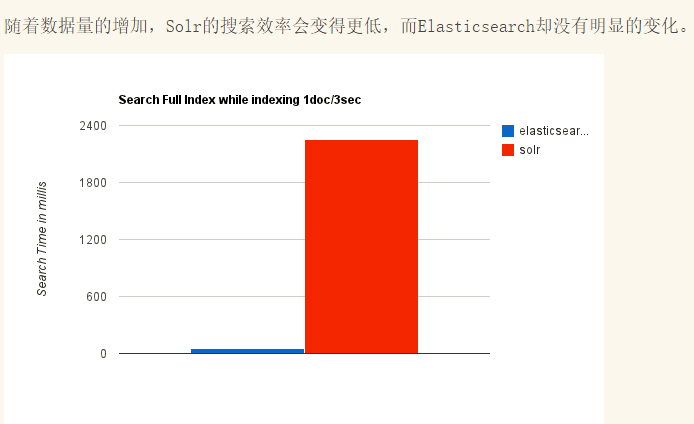
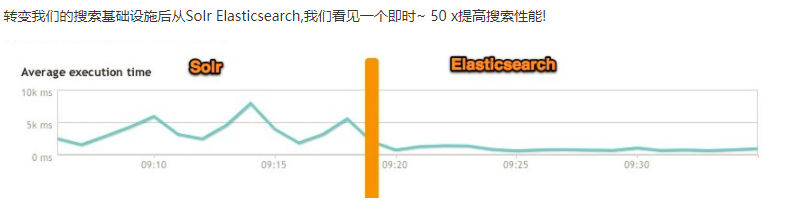
总结
1、es基本是开箱即用,非常简单。Solr安装略微复杂一丢丢!
2、Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能。
3、Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持json文件格式。
4、Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要 kibana 友好支撑
5、Solr 查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用;
- ES建立索引快(即查询慢),即实时性查询快,用于facebook新浪等搜索。
- Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
6、Solr比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而 Elasticsearch相对开发维护者较少,更新太快,学习使用成本较高。
ES的基础概念
我们还需对比结构化数据库,看看ES的基础概念,为我们后面学习作铺垫。
- Near Realtime(NRT) 近实时。数据提交索引后,立马就可以搜索到。
- Cluster 集群,一个集群由一个唯一的名字标识,默认为“elasticsearch”。集群名称非常重要,具有相同集群名的节点才会组成一个集群。集群名称可以在配置文件中指定。
- Node 节点:存储集群的数据,参与集群的索引和搜索功能。像集群有名字,节点也有自己的名称,默认在启动时会以一个随机的UUID的前七个字符作为节点的名字,你可以为其指定任意的名字。通过集群名在网络中发现同伴组成集群。一个节点也可是集群。
- Index 索引: 一个索引是一个文档的集合(等同于solr中的集合)。每个索引有唯一的名字,通过这个名字来操作它。一个集群中可以有任意多个索引。
- Type 类型:指在一个索引中,可以索引不同类型的文档,如用户数据、博客数据。从6.0.0 版本起已废弃,一个索引中只存放一类数据。
- Document 文档:被索引的一条数据,索引的基本信息单元,以JSON格式来表示。
- Shard 分片:在创建一个索引时可以指定分成多少个分片来存储。每个分片本身也是一个功能完善且独立的“索引”,可以被放置在集群的任意节点上。
- Replication 备份: 一个分片可以有多个备份(副本)
为了方便理解,作一个ES和数据库的对比
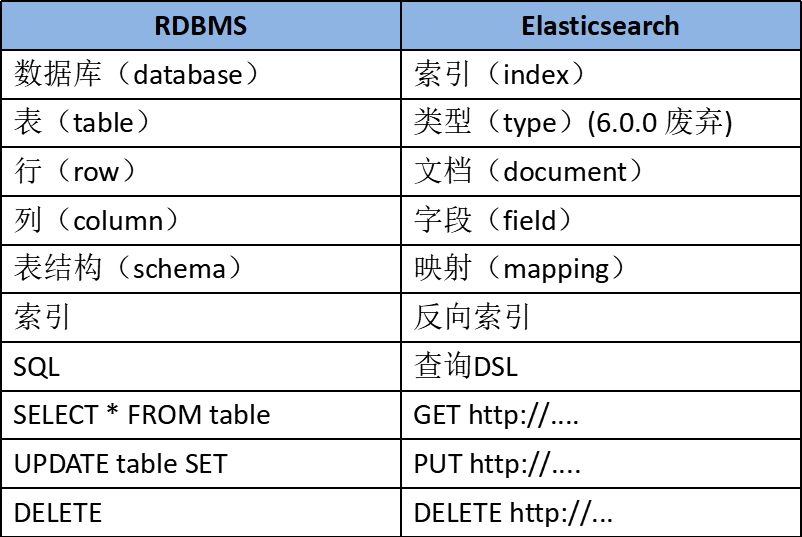
和 mysql 的类比
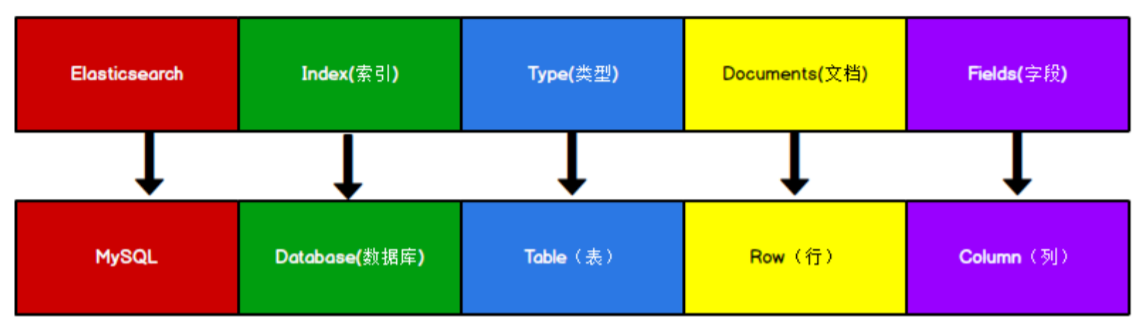
Elasticsearch 7.X 中, Type 的概念已经被删除了。
RESTful
REST 指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是 RESTful。Web 应用程序最重要的 REST 原则是,客户端和服务器之间的交互在请求之间是无状态的。从客户端到服务器的每个请求都必须包含理解请求所必需的信息。如果服务器在请求之间的任何时间点重启,客户端不会得到通知。此外,无状态请求可以由任何可用服务器回答,这十分适合云计算之类的环境。客户端可以缓存数据以改进性能。
在服务器端,应用程序状态和功能可以分为各种资源。资源是一个有趣的概念实体,它向客户端公开。资源的例子有:应用程序对象、数据库记录、算法等等。每个资源都使用 URI (Universal Resource Identifier) 得到一个唯一的地址。所有资源都共享统一的接口,以便在客 户端和服务器之间传输状态。使用的是标准的 HTTP 方法,比如 GET、PUT、POST 和 DELETE。
在 REST 样式的 Web 服务中,每个资源都有一个地址。资源本身都是方法调用的目标,方法列表对所有资源都是一样的。这些方法都是标准方法,包括 HTTP GET、POST、 PUT、DELETE,还可能包括 HEAD 和 OPTIONS。简单的理解就是,如果想要访问互联网上的资源,就必须向资源所在的服务器发出请求,请求体中必须包含资源的网络路径,以及对资源进行的操作(增删改查)。